有一些网站源代码不规范,在html中间突然出现。末尾又出现一次.这种情况下,会导致解析出错。现在已经修复。
- 基于可视化区域,更准确地识别正文
- 修复下面这种情况时,无法正确寻找正文的 bug
<div>
我是正文我是正文我是正文<a href="xxx">关键词1</a>我是正文我是正文我是正文我是正文
我是正文我是正文我是正文我是正文我是正文<a href="xxx">关键词2</a>我是正文我是正文
我是正文
</div>- 统计一个标签下面的 p 标签的时候,应该把这个标签下面的直接文档数也统计进去
- 修复 extract_by_htag_and_title 在发现 H 标签中的文本与 title 标签的文本在最小公共子串长度小于4时被认为是标题的问题。
- 在使用 title 标签提取标题时,对于分隔符-_|分割的第一段内容,必须要大于4个字符才当做标题,否则会返回整个 title 标签的文本。
- 预处理时,把 标签移除。
USELESS_ATTR对应的节点,只有 class 完全匹配才需要删除。之前包含就删除的匹配方式会导致 ifeng 的正文被删除。
- 指定列表页特征,自动提取列表页数据
- 不再需要计算文本密度的标准差
- 🚀减少重复计算,大幅度提升分析速度
- 优化标题提取逻辑,根据@止水 和 @asyncins 的建议,通过对比 //title/text()中的文本与 标签中的文本,提取出标题。
- 增加
body_xpath参数,精确定义正文所在的位置,强力避免干扰。
例如对于澎湃新闻,在不设置body_xpath参数时:
result = extractor.extract(html,
host='https://www.xxx.com',
noise_node_list=['//div[@class="comment-list"]',
'//*[@style="display:none"]',
'//div[@class="statement"]'
])提取效果如下:
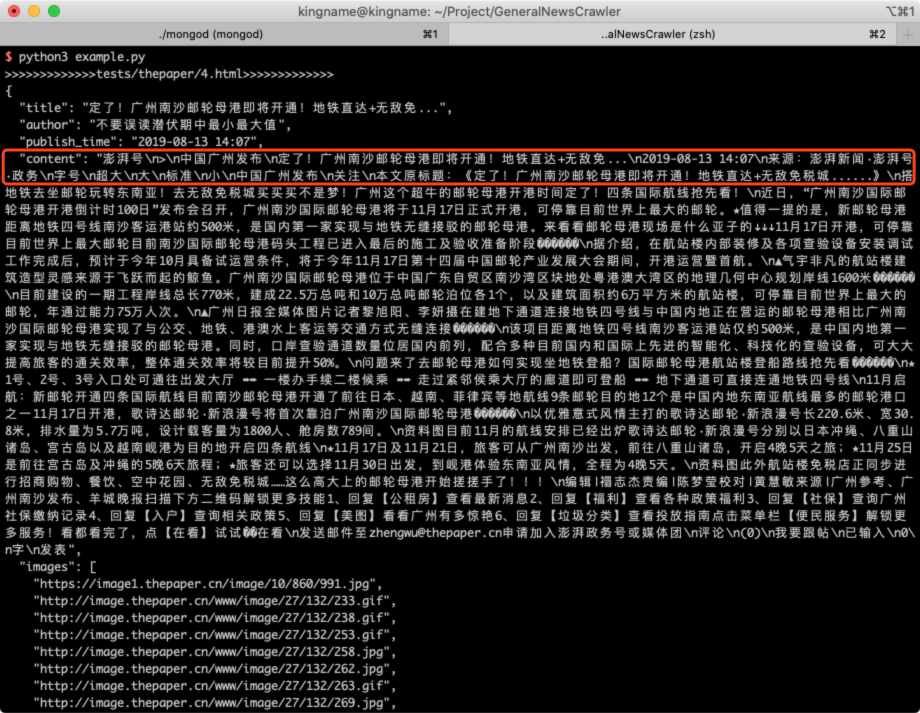
设置了body_xpath以后:
result = extractor.extract(html,
host='https://www.xxx.com',
body_xpath='//div[@class="news_txt"]', # 缩小正文提取范围
noise_node_list=['//div[@class="comment-list"]',
'//*[@style="display:none"]',
'//div[@class="statement"]'
])结果如下:
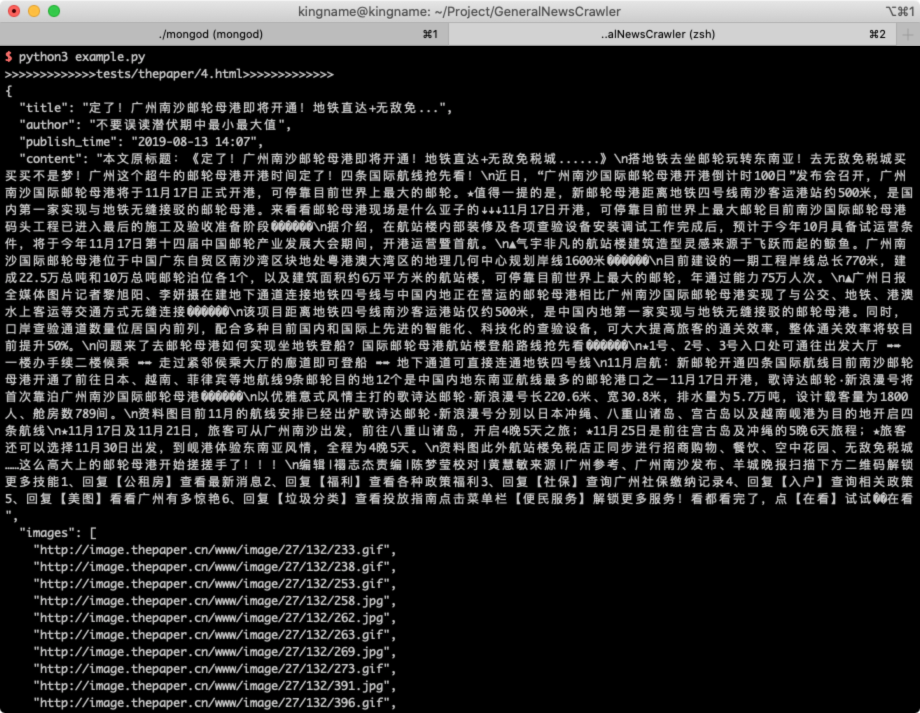
- 预处理可能会破坏 HTML 结构,导致用户自定义的 XPath 无法正确工作,因此需要把提取用户名、发布时间、标题的代码放在预处理之前。
- 感谢@止水提供的 meta 对应的新闻时间属性,现在会从 HTML 的 meta 数据中检查是否有发布时间。
- 在GeneralNewsExtractor().extract()方法中传入参数
author_xpath和publish_time_xpath强行指定抓取作者与发布时间的位置。 - 在.gne 配置文件中,通过如下两个配置分别指定作者与发布时间的 XPath
author:
xpath: //meta[@name="author"]/@content
publish_time:
xpath: //em[@id="publish_time"]/text()- 修复由于
node.getparent().remove()会移除父标签中,位于自己后面的 text 的问题 - 对于class 中含有
article/content/news_txt/post_text的标签,增加权重 - 使用更科学的方法移除无效标签
通用参数可以通过 YAML、JSON 批量设置了。只需要在项目的根目录下创建一个 .gne ,就可以实现函数默认参数的功能。
- 现在可以通过传入参数
host来把提取的图片url 拼接为绝对路径
例如:
extractor = GeneralNewsExtractor()
result = extractor.extract(html,
host='https://www.xxx.com')返回数据中:
{
...
"images": [
"https://www.xxx.com/W020190918234243033577.jpg"
]
}- 增加更多的 UselessAttr
- 返回的结果包含
images字段,里面的结果是一个列表,保存了正文中的所有图片 URL - 指定
with_body_html参数,返回的数据中将会包含body_html字段,这是正文的 HTMl 源代码:
...
result = GeneralNewsExtractor().extract(html, with_body_html=True)
body_html = result['body_html']
print(f'正文的网页源代码为:{body_html}')