使用extract方法进行内容抽取的时候如果加了对body内容的xpath配置就报错 #104
Assignees

Labels
bug
Something isn't working
Comments
|
你可以显看看,你获取到的html_content里面,有没有rich_media_content这个class |
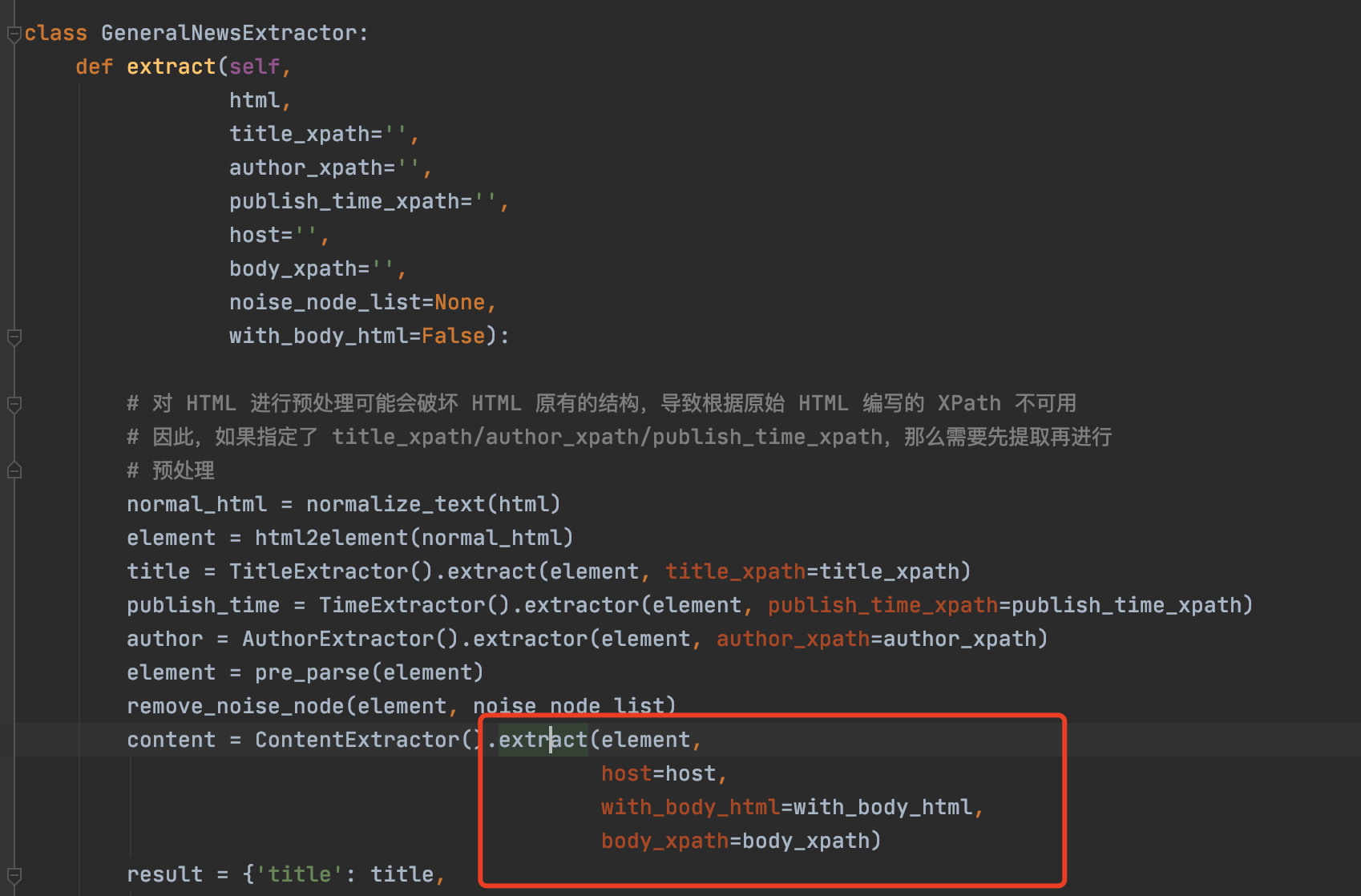
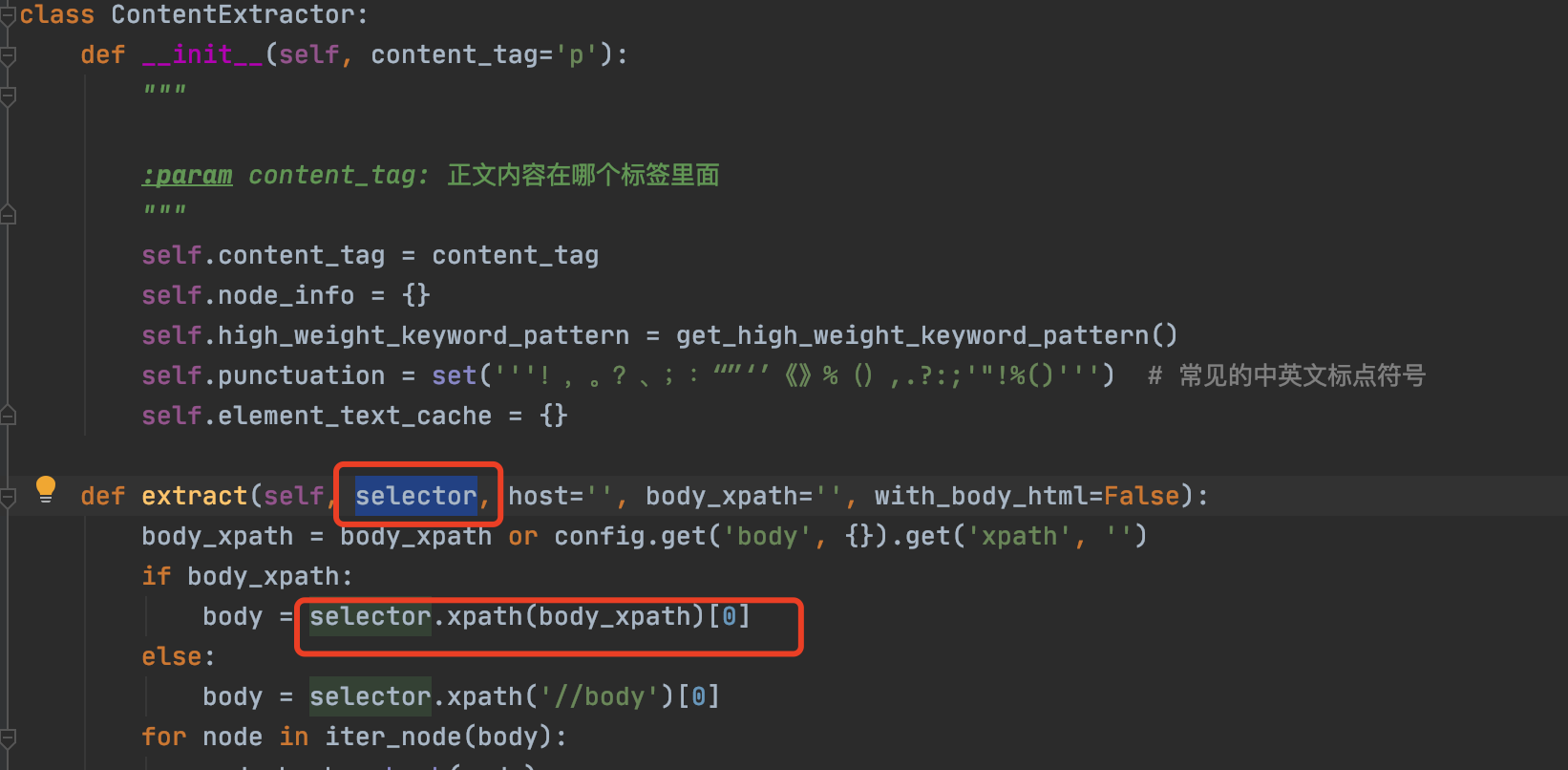
返回的是有那个class的,只是这个方法里面有个selector参数,在这个地方源码没有传,导致进去用下标获取时会报错
|

|
这个 selector 参数就是我传进去的 element。 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
使用GeneralNewsExtractor的extract方法进行内容抽取的时候如果加了对body内容的xpath配置就报错
如何复现
body = selector.xpath(body_xpath)[0]
IndexError: list index out of range
屏幕截图

使用环境:
The text was updated successfully, but these errors were encountered: