目录:
在量化过程中,浮点实数值会映射到低比特量化空间,比如8bit、4bit等。从量化计算方式的角度,量化主要可以分为线性量化和非线性量化。线性量化方法由于计算方式简单以及较多硬件支持,应用最为广泛,目前PaddlePaddle中主要支持线性量化计算。线性量化又可以细分为对称量化,非对称量化等,PaddleSlim中默认支持对称量化。
以线性对称量化为例,其计算公式为:
反量化过程可以用以下公式表述:
其中,s为所选取的scale值,即尺度因子,将全精度参数映射到低比特取值范围;α为选定的全精度参数的表示范围,量化过程会对全精度数值进行截断处理,即全精度数值将被限制在[-α,α]内。b为量化的比特数,x为待量化的全精度参数。因此,如果给定量化的比特数b,我们只需要选定合适的α值,就可以确定量化所需的参数s。
在模型量化过程中分为权重量化和激活量化:
- 权重量化:即需要对网络中的权重执行量化操作。可以选择逐层(layer-wise)或者逐通道(channel-wise)的量化粒度,也就是说每层或者每个通道选取一个量化scale。在PaddleSlim中所有权重量化都采用
abs_max或者channel_wise_abs_max的方法,需要注意的是部分部署硬件有可能不支持channel-wise量化推理。 - 激活量化:即对网络中不含权重的激活类OP进行量化。一般只能采用逐层(layer-wise)的量化粒度。在PaddleSlim的中默认采用
moving_average_abs_max的采样策略。
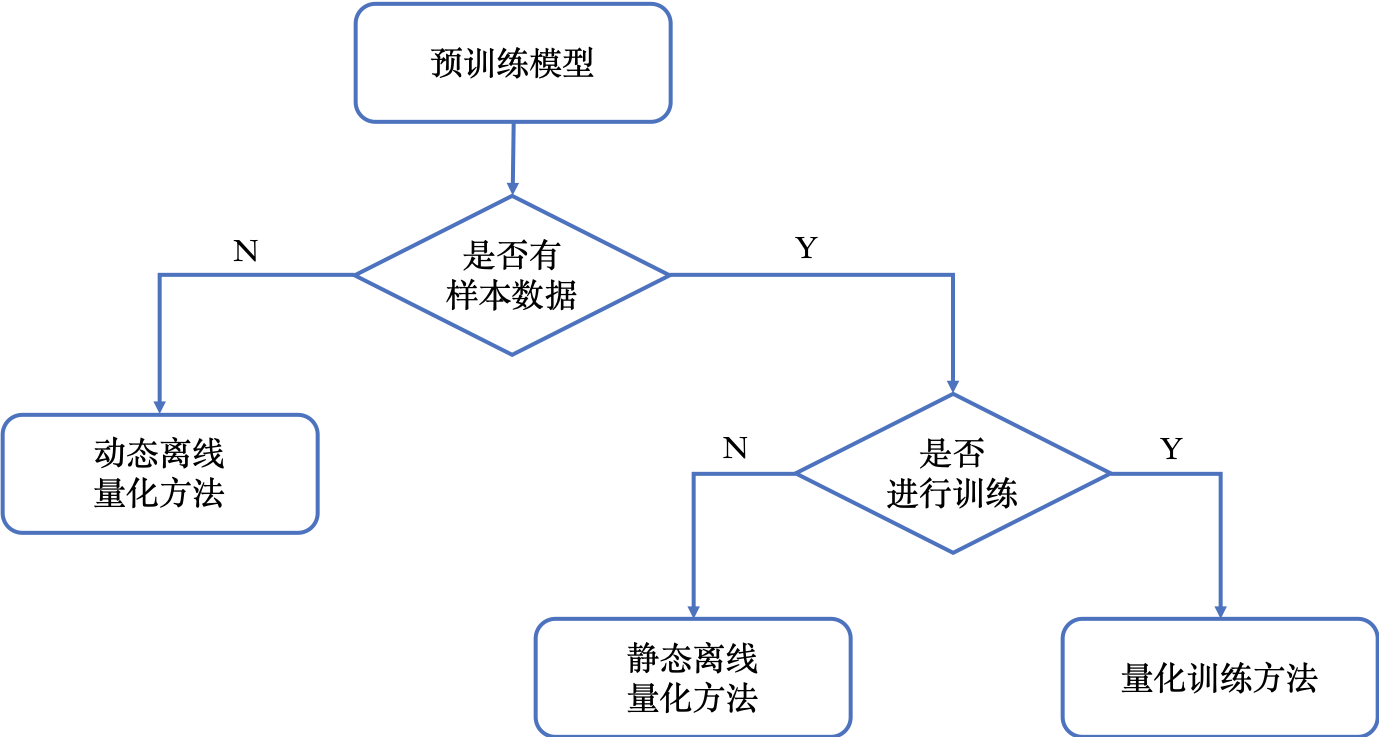
静态离线量化是基于采样数据,离线的使用KL散度、MSE等方法计算量化比例因子的方法。相比量化训练,静态离线量化不需要重新训练,可以快速得到量化模型。
静态离线量化的步骤如下:
- 加载预训练的FP32模型,配置用于校准的DataLoader;
- 读取小批量样本数据,执行模型的前向推理,保存更新待量化op的量化Scale等信息;
- 将FP32模型转成INT8模型,进行保存。
导出模型步骤:
- 离线量化校准时根据量化统计白名单 插入observer节点。静态离线量化后,在导出量化模型时会将所有observer(统计量化信息)节点转换成量化(quantize_linear)和反量化(dequantize_linear)节点。
- 将量化OP的权重转换为定点数,比如INT8,相比于FP32,这会缩减模型体积2~4倍左右。
目前支持的静态离线量化方法有:
| 量化方法 | 方法详解 |
|---|---|
| abs_max | 选取所有激活值的绝对值的最大值作为截断值α。此方法的计算最为简单,但是容易受到某些绝对值较大的极端值的影响,适用于几乎不存在极端值的情况。 |
| KL | 使用参数在量化前后的KL散度作为量化损失的衡量指标。此方法是TensorRT所使用的方法,我们根据8-bit Inference with TensorRT 进行了实现。在大多数情况下,使用KL方法校准的表现要优于abs_max方法。 |
| avg | 选取所有样本的激活值的绝对值最大值的平均数作为截断值α。此方法计算较为简单,可以在一定程度上消除不同数据样本的激活值的差异,抵消一些极端值影响,总体上优于abs_max方法。 |
| hist | 首先采用KL散度的方式将所有参数映射为直方图,然后根据给定百分比,选取直方图的百分位点作为截断值α。此方法可以去除掉一些极端值,并且可以灵活调节直方图百分比(hist_percent)来调整截断值大小,以适应不同模型。 |
| mse | 使用均方误差作为模型量化前后输出的损失的衡量指标。选取使得激活值在量化前后的均方误差最小的量化参数。此方法较为耗时,但是效果常常优于其他方法。 |
| emd | 使用推土距离(EMD)作为模型量化前后输出的损失的衡量指标。使用EMD距离做度量,量化前后EMD距离越小,量化精度越高。选取使得激活值在量化前后的均方误差最小的量化参数。 |
| bias_correction | 通过简单的校正常数来补偿权重weight量化前后的均值和方差的固有偏差,参考自论文。 |
| Adaround | 对每层weight值进行量化时,不再采样固定四舍五入方法,而是自适应的决定weight量化时将浮点值近似到最近右定点值还是左定点值。具体的算法原理参考自论文。 |
| BRECQ | 对每层weight值进行量化时,不再采样固定四舍五入方法,而是自适应的决定weight量化时将浮点值近似到最近右定点值还是左定点值,同时以region为单位调整weight。具体的算法原理参考自论文。 |
| QDrop | 对每层weight值进行量化时,不再采样固定四舍五入方法,而是自适应的决定weight量化时将浮点值近似到最近右定点值还是左定点值,同时以dropout的方式引入激活量化的噪声。具体的算法原理参考自论文。 |
说明:
- 可以在PaddleSlim的离线量化接口中设置不同的方法。
- 离线量化示例:PTQ Example。
PaddleSlim量化训练是指模拟量化训练方案,在模型训练前需要先对网络计算图进行处理,先在需要量化的算子前插入量化-反量化节点,再经过训练,产出模拟量化的模型。一般量化训练直接在训好的浮点模型上进行finetune少量Epoch即可,finetune过程中,学习率也需要适当调小。量化训练的优点是在训练中调整权重分布以适应模拟量化计算,从而大幅降低量化模型的精度损失,一般优于离线量化方法。缺点是训练过程较慢,资源要求较高。
量化训练的一般步骤:
- 构建模型和数据集
- 进行浮点模型的训练
- 加载预训练模型,进行量化训练微调
- 导出量化预测模型
量化训练示例:
动态离线量化将模型中特定OP的权重从FP32类型量化成INT8等类型,该方式的量化有两种预测方式:
- 第一种是反量化预测方式,即是首先将INT8/16类型的权重反量化成FP32类型,然后再使用FP32浮运算运算进行预测;
- 第二种量化预测方式,即是预测中动态计算量化OP输入的量化信息,基于量化的输入和权重进行INT8整形运算。
目前只有Paddle Lite中支持第一种反量化预测方式,其余方式暂不支持。
- 对携带weight算子量化:
携带weight算子是指Conv、Linear这类其中一个输入是从weight参数中读取。如下图左所示,量化模型的weight存储的是低比特的形式(比如INT8格式),存储体积和FP32相比会减少几倍。在模型中weight输入前会插入反量化(dequantize_linear)算子算子。
在其激活输入前会插入量化(quantize_linear)和反量化(dequantize_linear)算子。在该算子输出位置插入量化(quantize_linear)和反量化(dequantize_linear)算子,方便预测库直接获取输出scale信息。
- 对激活层算子量化:
在对激活层算子(比如max_pool、add、sigmoid等)量化时,如下图右所示,在其输入前会插入量化(quantize_linear)和反量化(dequantize_linear)算子。在该算子输出位置插入量化(quantize_linear)和反量化(dequantize_linear)算子,方便预测库直接获取输出scale信息。


-
输入(INPUTS)
X: 将要被量化的N-D Tensor输入。Scale: float标量或者1-D Tensor类型,存储当前输入浮点数截断值range_abs_max,即上方公式中的α。当Scale是float标量时,表示当前层是per-layer量化;当Scale是1-D Tensor时,表示当前层是per-channel量化。ZeroPoint: 表示量化时的零点,类型和Scale完全一致。默认对称量化,ZeroPoint保持全0。
-
输出(OUTPUTS)
Y: 量化计算输出的的N-D Tensor,Y与输入X应保持完全一致。
-
属性(ATTRIBUTES)
bit_length: 类型为int,当前层量化的比特数,默认8。quant_axis: 类型为int,多维Tensor量化在维度上的轴。当前层是per-layer量化时,quant_axis=-1;表示当前层是per-channel量化时,quant_axis根据不同算子可选0或1。round_type: 类型为int,可选属性,表示近似计算的方法。目前可选0和1,0表示rounding to nearest ties to even;1表示rounding to nearest ties away from zero。如果该属性不存在,表示默认0。
-
输入(INPUTS)
X: 将要被反量化的N-D Tensor输入。Scale: Scale值和上一层quantize_linear中Scale类型和数值应完全一致。ZeroPoint: ZeroPoint值和上一层quantize_linear中ZeroPoint类型和数值应完全一致。
-
输出(OUTPUTS)
Y: 反量化计算输出的的N-D Tensor,Y与输入X应保持完全一致。
-
属性(ATTRIBUTES)
bit_length:类型为int,当前层量化的比特数,默认8。quant_axis: 类型为int,多维Tensor量化在维度上的轴。当前层是per-layer量化时,quant_axis=-1;表示当前层是per-channel量化时,quant_axis根据不同算子可选0或1。round_type: 类型为int,可选属性,表示近似计算的方法。目前可选0和1,0表示rounding to nearest ties to even;1表示rounding to nearest ties away from zero。如果该属性不存在,表示默认0。
