| title |
|---|
Kafka 如何解决消息不丢失? |
作者:Tom哥
公众号:微观技术
博客:https://offercome.cn
人生理念:知道的越多,不知道的越多,努力去学
Kafka 消息框架,大家一定不陌生,很多人工作中都有接触。它的核心思路,通过一个高性能的MQ服务来连接生产和消费两个系统,达到系统间的解耦,有很强的扩展性。
你可能会有疑问,如果中间某一个环节断掉了,那怎么办?
这种情况,我们称之为消息丢失,会造成系统间的数据不一致。
那如何解决这个问题?需要从生产端、MQ服务端、消费端,三个维度来处理
生产端的职责就是,确保生产的消息能到达MQ服务端,这里我们需要有一个响应来判断本次的操作是否成功。
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)
比如,上面的代码就是通过一个Callback函数,来判断消息是否发送成功,如果失败,我们需要补偿处理。
另外,为了提升发送时的灵活性,kafka提供了多种参数,供不同业务自己选择
该参数表示有多少个分区副本收到消息,才认为本次发送是成功的。
- acks=0,只要发送消息就认为成功,生产端不等待服务器节点的响应
- acks=1,表示生产者收到 leader 分区的响应就认为发送成功
- acks=-1,只有当 ISR 中的副本全部收到消息时,生产端才会认为是成功的。这种配置是最安全的,但由于同步的节点较多,吞吐量会降低。
表示生产端的重试次数,如果重试次数用完后,还是失败,会将消息临时存储在本地磁盘,待服务恢复后再重新发送。建议值 retries=3
消息发送超时或失败后,间隔的重试时间。一般推荐的设置时间是 300 毫秒。
这里要特别注意一种特殊情况,如果MQ服务没有正常响应,不一定代表消息发送失败,也有可能是响应时正好赶上网络抖动,响应超时。
当生产端做完这些,一定能保证消息发送成功了,但可能发送多次,这样就会导致消息重复,这个我们后面再讲解决方案
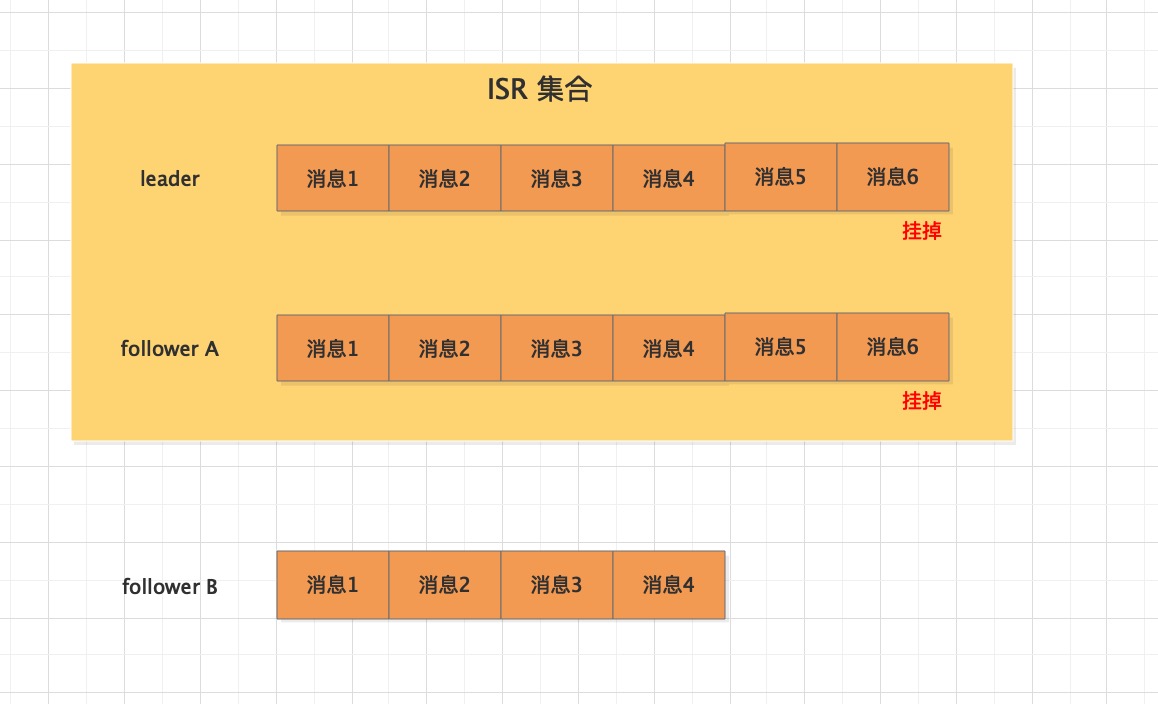
MQ服务端作为消息的存储介质,也有可能会丢失消息。比如:一个分区突然挂掉,那么怎么保证这个分区的数据不丢失,我们会引入副本概念,通过备份来解决这个问题。
具体可设置哪些参数?
表示分区副本的个数, replication.factor >1 当leader 副本挂了,follower副本会被选举为leader继续提供服务。
表示 ISR 最少的副本数量,通常设置 min.insync.replicas >1,这样才有可用的follower副本执行替换,保证消息不丢失
是否可以把非 ISR 集合中的副本选举为 leader 副本。
如果设置为true,而follower副本的同步消息进度落后较多,此时被选举为leader,会导致消息丢失,慎用。
消费端要做的是把消息完整的消费处理掉。但是这里面有个提交位移的步骤。
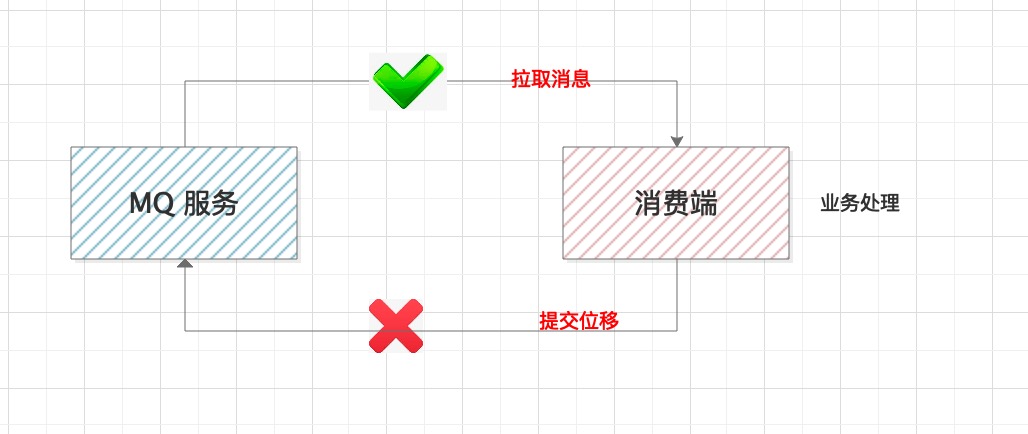
有的同学,考虑到业务处理消耗时间较长,会单独启动线程拉取消息存储到本地内存队列,然后再搞个线程池并行处理业务逻辑。这样设计有个风险,本地消息如果没有处理完,服务器宕机了,会造成消息丢失。
正确的做法:拉取消息 --- 业务处理 ---- 提交消费位移
关于提交位移,kafka提供了集中参数配置
参数 enable.auto.commit
表示消费位移是否自动提交。
如果拉取了消息,业务逻辑还没处理完,提交了消费位移但是消费端却挂了,消费端恢复或其他消费端接管该分片再也拉取不到这条消息,会造成消息丢失。所以,我们通常设置 enable.auto.commit=false,手动提交消费位移。
List<String> messages = consumer.poll();
processMsg(messages);
consumer.commitOffset();
这个方案,会产生另外一个问题,我们来看下这个图

拉取了消息4~消息8,业务处理后,在提交消费位移时,不凑巧系统宕机了,最后的提交位移并没有保存到MQ 服务端,下次拉取消息时,依然是从消息4开始拉取,但是这部分消息已经处理过了,这样便会导致重复消费。
首先,要解决MQ 服务端的重复消息。kafka 在 0.11.0 版本后,每条消息都有唯一的message id, MQ服务采用空间换时间方式,自动对重复消息过滤处理,保证接口的幂等性。
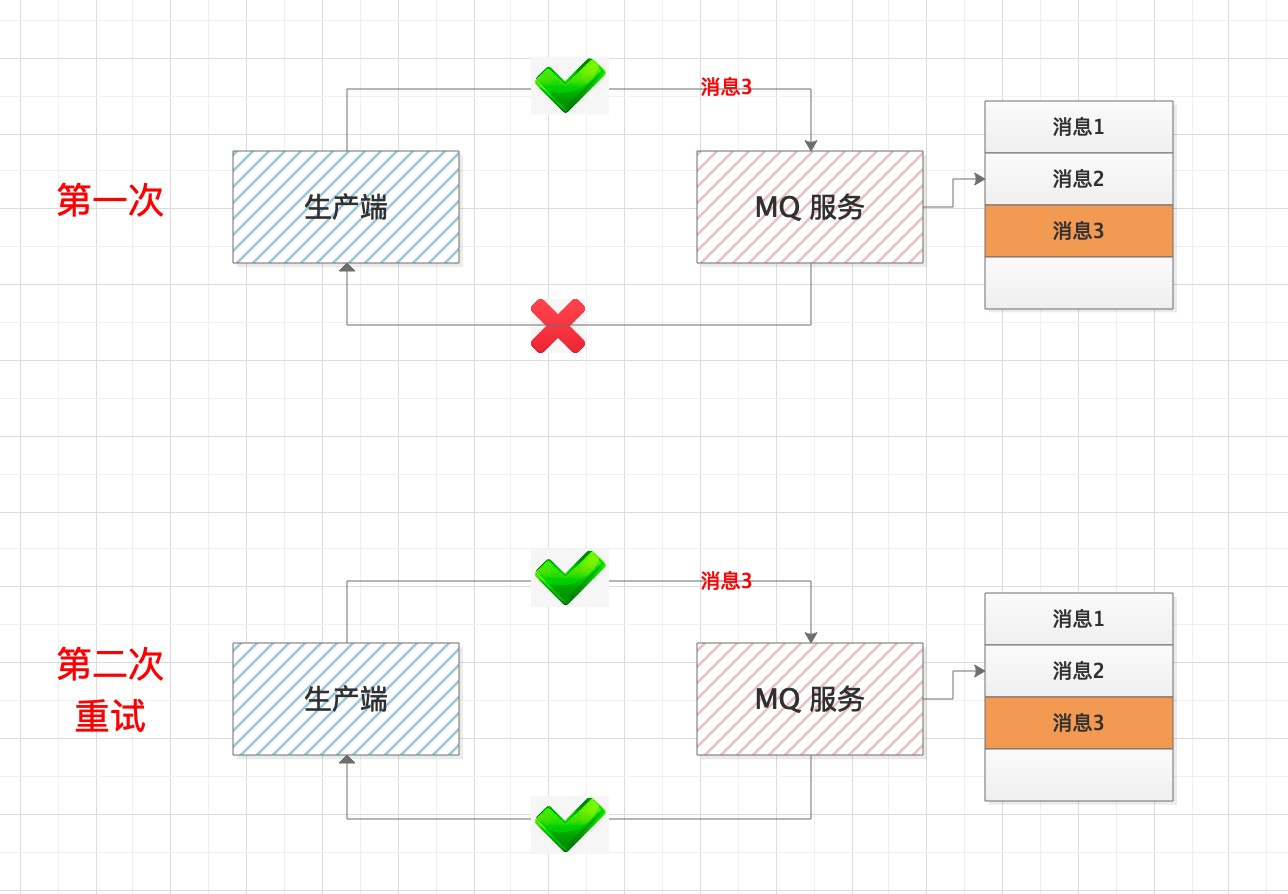
但这个不能根本上解决消息重复问题,即使MQ服务中存储的消息没有重复,但消费端是采用拉取方式,如果重复拉取,也会导致重复消费,如何解决这种场景问题?
方案一:只拉取一次(消费者拉取消息后,先提交 offset 后再处理消息),但是如果系统宕机,业务处理没有正常结束,后面再也拉取不到这些消息,会导致数据不一致,该方案很少采用。
方案二:允许拉取重复消息,但是消费端自己做幂等性控制。保证只成功消费一次。
关于幂等技术方案很多,我们可以采用数据表或Redis缓存存储处理标识,每次拉取到消息,处理前先校验处理状态,再决定是处理还是丢弃消息。