Replies: 4 comments 3 replies
-
|
Totally agree. This feature is also available in Google Cloud Platform, at least in Cloud Run. I used global variables in Python for loading machine learning models in Tensorflow. The first time, the docker container takes some time to load the model which is stored in a file, but after that inferences are served fast, since the model is already loaded in memory and it is shared among different function executions in the same docker container. |
Beta Was this translation helpful? Give feedback.
-
|
I just started to use Appwrite today, and I can say that this was the only major concern I had, right when I saw that we have to provide a I think the current implementation is a dealbreaker for many people that need a more customized backend. If I want to rate limit the users from reading posts (to prevent scraping) I would have to proxy all requests through a function currently, which would spawn a single process, every time a user sees a post, which is very frequent, as users can scroll through posts, like on Instagram. |
Beta Was this translation helpful? Give feedback.
-
|
Hmmm if I think about it, maybe, MAYBE, all of this can be simply achieved using custom runtime. I will try to achieve that and share the progression. |
Beta Was this translation helpful? Give feedback.
-
|
Sooo yeah, it was possible using custom runtime. I created Then, there is When client sends a request to master, master will require() file This require only runs once, because NodeJS... That means, whatever code is in root of executor will also only run once, because Nodejs. It just works like that... What does this achieve? Nice to meet you, global variables! To make sure the concept is working, I implemented it into my current project with ~10 functions. Inside these functions, I require libraries (knex, MySQL, ulid, ..) and create a connection to MySQL with 1 query to ensure it works. Then, I run the function itself (fetch data from MySQL, format, return). Without this solution, every request took ~1 second. Then I moved require(), connection to MySQL and first query outside of execute() function, to make it global. The rest of the code was inside execute() because that needed to be run on every request. Here are the results: I will talk to Appwrite about this and create a PR if they accept this solution. What do you guys think about it? @MarvinJWendt @JaviBonilla |
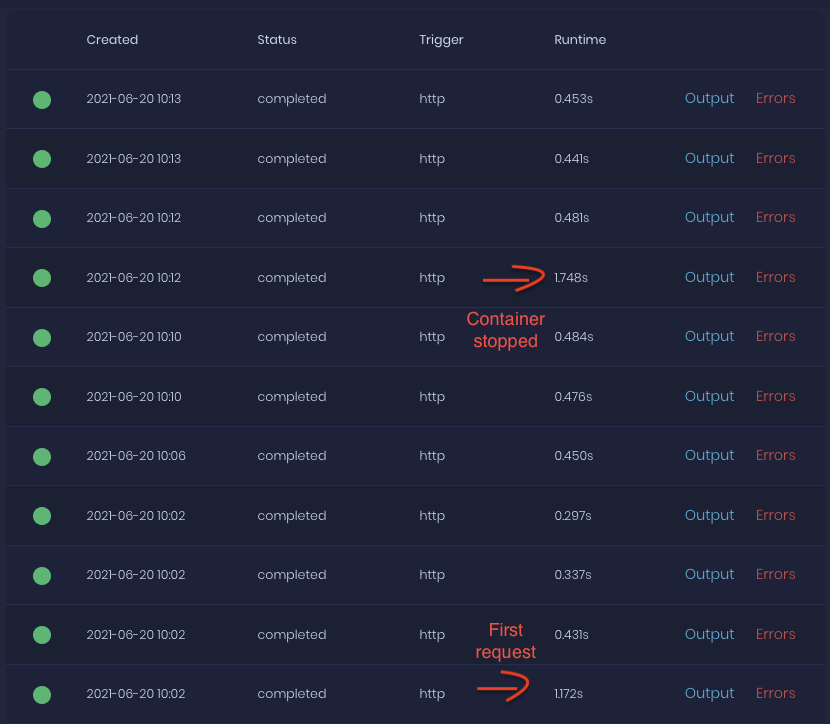
Beta Was this translation helpful? Give feedback.
-
|
This is a nice workaround, but I think the official solution should be more performant. In your proposed solution, it still creates a process for each execution ( Using something like the FaaS library that @JaviBonilla suggested looks like it could be the "right thing" as it should be very efficient and is made by Google. It also has nearly a Million downloads per Week, so I guess it does it's job well. |
Beta Was this translation helpful? Give feedback.
-
|
@Meldiron Good idea and it is awesome to see the execution time reduction 😀. Also great work for your custom docker images and endpoints support. I’m planning to use them soon. I’m happy with this solution for the time being, but the function as a service solution seems more maintenable in the long term. |
Beta Was this translation helpful? Give feedback.
-
|
This is an open source framework from Google for cloud functions available for several programming languages and frameworks: nodejs, Python, etc. https://github.com/GoogleCloudPlatform/functions-framework-nodejs Not sure if this feature of global scope variables per instance is available there, but if this is the case, it maybe useful for achieving this in custom runtimes. |
Beta Was this translation helpful? Give feedback.
-
How Appwrite does it?
Appwrite has a functions container that listens for new executions and when there is a new one, it starts a separate NodeJS container. Inside this container, it starts my code and wait for it to end. When it ends, it takes all console log and keeps it as a result of an execution.
How Google/Amazon/Microsoft does it?
Amazon starts a container as soon as the first request comes in. Instead of simply running my script and waiting for it to stop, it has its own NodeJS wrapper that runs for as long as the container is running. What this wrapper does? It includes my code (using require or import) and my code HAS TO export some method (for example
execute) Whenever there is a new request to execute my code, their wrapper runs functionexecuteand returns the result of this function (whatever I return there).Who does it better?
Amazon! Why? Amazon's approach introduces
global variables. What does that mean? All NodeJS code in my script that is outsideexecutemethod will be triggered once on first require/import - when Amazon NodeJS wrapper starts. Then, it will share EVERYTHING that was created this way between all executions inside this one container.Why is it important?
You mainly need this structure with global variables when working with 3rd party software such as MySQL, Redis or ElasticSearch. For example, MySQL has a pretty long handshake - process of creating a connection. That means, my first request to get an user would take 800ms, but the second one would take 50ms, if I used Amazon. This has nothing to do with caching, this is simply handshake taking too long.
Using Amazon's approach, you would handshake each time a new container is started. (not really often, just few times an hour on simple small project)
Using the current Appwrite approach, you would handshake each time a NEW EXECUTION IS REQUESTED. This is a HUGE problem because it adds at least 0.5s to response time to each execution - it makes it impossible to use Appwrite functions with realtime feature to host the whole API that requires connection to any 3rd party software.
Soo if I used Amazon approach, time to run executions would be something like:
First: 800ms
Second: 100ms
Third: 100ms
...
50th request: 800ms (when new container starts, due to long pause or anything)
51th request: 100ms
52th request 100ms
(and so on)
Meanwhile if I used Appwrite, it would be:
First: 800ms
Second: 800ms
Third: 800ms
(and so on, forever)
Conclusion? Solution?
Well, after publishing realtime feature, Appwrite will get A LOT OF attention from people that are not used to serverless because they still want to write their own code (it's easier to write secure code than to write secure rules/permissions in complex project). These people are not used to NoSQL databases, so I strongly believe a lot of them would be looking for a way to connect to MySQL database and would end up with the same problem as me.
Solution? Well... It most likely is possible to re-write whole structure how NodeJS works.. I can't tell how much of a problem it would be, but that would simply be the best solution - copy from the best (Amazon, Google..).
I can also see a solution by adding configuration for most used services (such as ElasticSearch, MySQL, ...) directly into Appwrite. This way, Appwrite will take care of keeping all communication alive and having some connections ready to be used instantly. This way, I would import Appwrite SDK inside my NodeJS script and use it's MySQL client.
Finally, it would be possible to prepare some optional external services such as
appwrite-mysql-proxythat would simply always keep connection to MySQL databases and I will use unix sockets to communicate with it. This will require some security updates, so it seems to be the least relevant solution.Any thoughts, ideas? What do YOU think about this?
Beta Was this translation helpful? Give feedback.
All reactions