[BUG] hackernews demo fails on merge branch #473
Assignees


Labels
Comments
|
as w/ other semantic search, now also getting: so semantic search may have an issue? |
|
@tanmoyio search still problematic on hn demo even for 0.29.1 (g distro so w/ rapids):
|
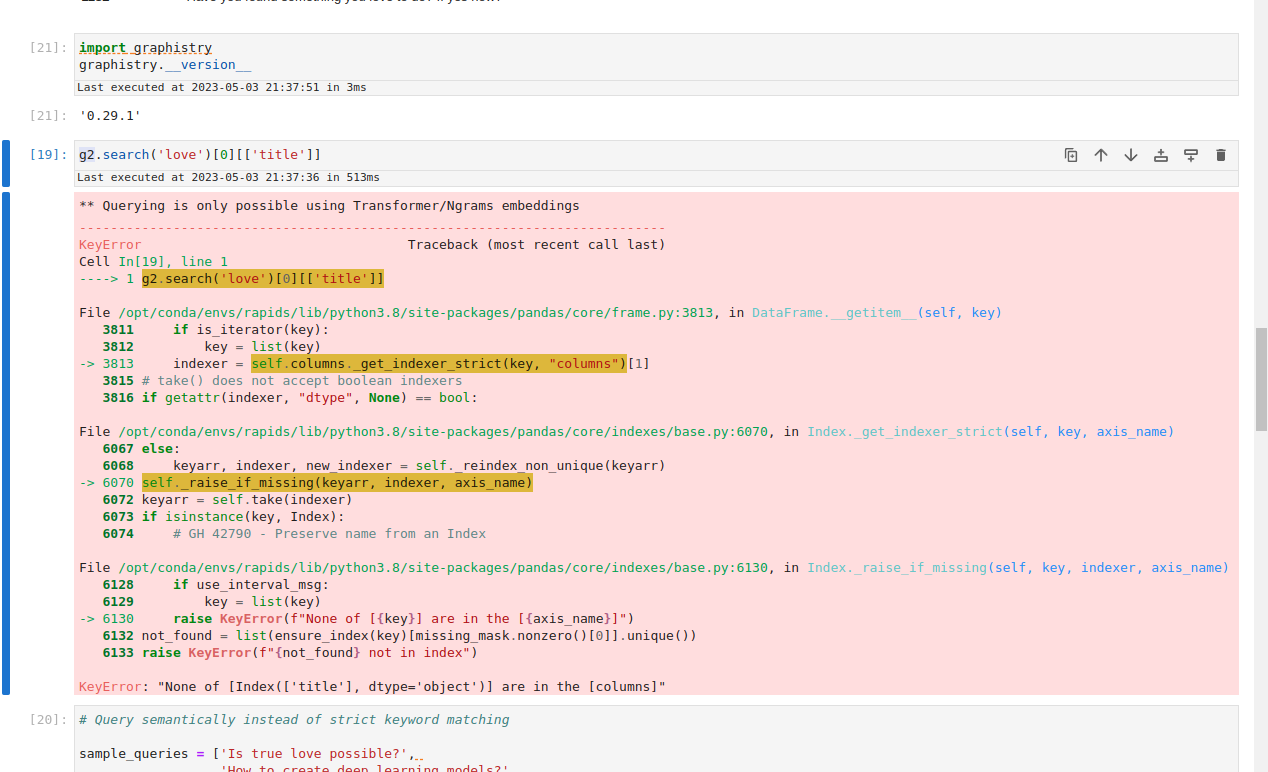
|
I'm getting a lot of: => |
|
I wonder if this is parameterization based on cpu vs gpu, or something deeper? |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
On
http://localhost/notebook/lab/tree/demos/ai/Introduction/Ask-HackerNews-Demo.ipynb:The text was updated successfully, but these errors were encountered: