Webhook issues: InternalError (failed calling webhook "ipaddresspoolvalidationwebhook.metallb.io") #1597
Comments
|
Hi, Pure speculation, but could the API server initially cache an invalid cert before the cabundle injection and the waiting cause this cache to expire and the new injected certificate being loaded? |
|
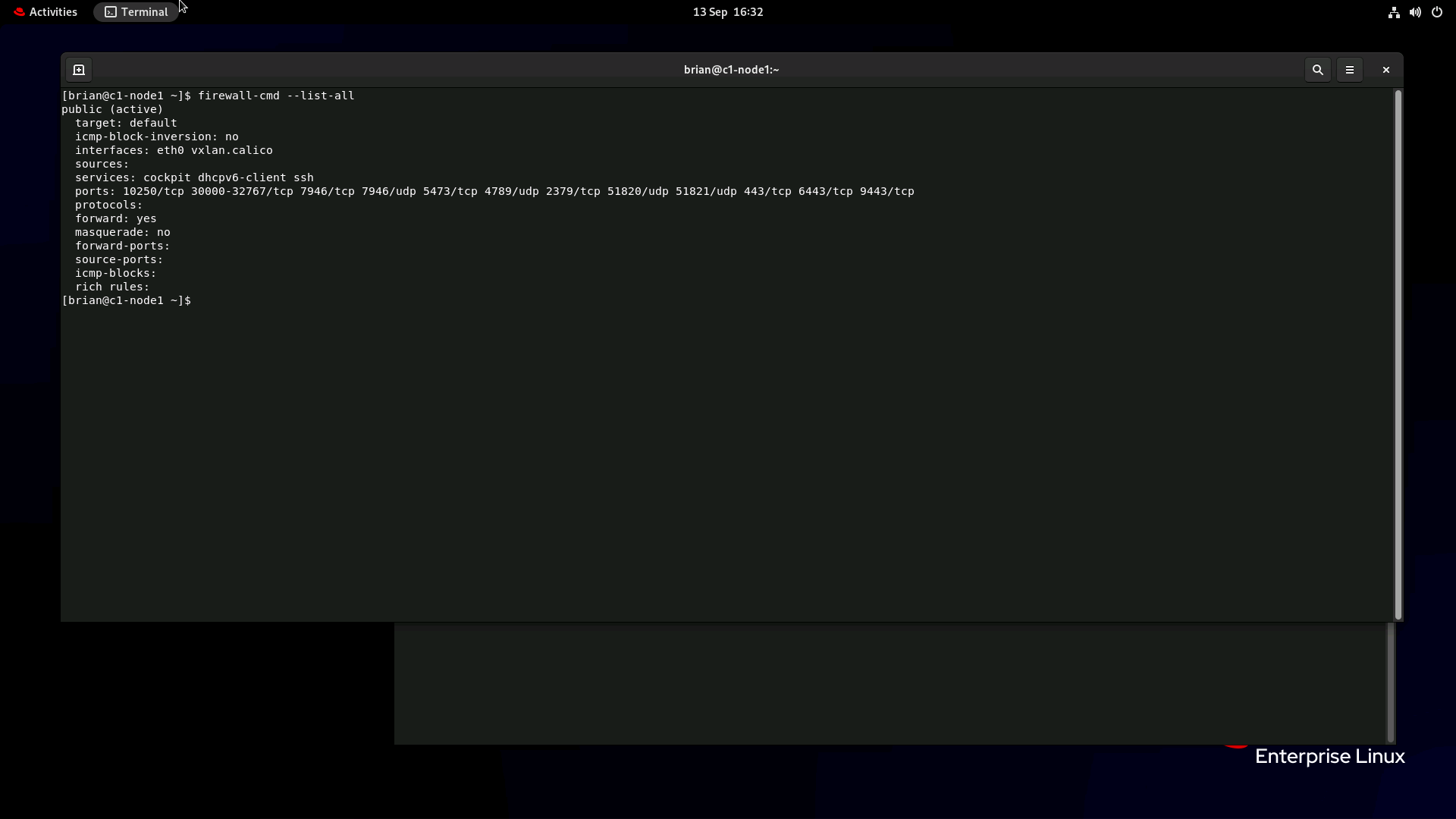
Hi, If I turn off the firewall on the worker nodes then all works well. The firewall dropped logs report
The configuration of the firewall is
The webhook service is described below.
I'm a beginner with Kubernetes and Metallb so any advice would be gratefully accepted. Brian.. |


This comment was marked as outdated.
This comment was marked as outdated.
|
My problem was fixed. I had problems with helm deployment, metallb version 0.12 and outdated crds. Redeploying everything works perfectly. Best regards. |
|
I've experienced when installing MetalLB via But, it doesn't always happen. |
|
Hi @fedepaol I've done two installations of MetalLB today, both using the same version of the chart (latest available as at time of writing).
I've run the tests outlined above and got the expected response from While we're here, can MetalLB be configured to get certificates from cert-manager? Happy to submit a PR on the chart if it should work, and is not implemented. |
|
Hi @fireflycons , we had a discussion about the method to provide certificates to the webhooks, and we came up to the conclusion that adding an additional dependency such as cert-manager was not ideal, so we ended up embedding https://github.com/open-policy-agent/cert-controller in metallb to perform such task. |
|
Ok @fedepaol that's fine re cert-manager. At least I know how you're doing it now :-) Any ideas on why the IPAddressPool isn't working in my virtualbox setup? |
|
What you mean by "the ipaddresspool isn't working"? |
|
I mean what this entire discussion is about. When I try to create the IPAddresPool and L2Advertisement resources, they time out. |
|
Ah apologies. Can you check the logs of the apiserver? |
|
Hi @fedepaol API server error is {
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "Internal error occurred: failed calling webhook \"ipaddresspoolvalidationwebhook.metallb.io\": failed to call webhook: Post \"https://metallb-webhook-service.metallb-system.svc:443/validate-metallb-io-v1beta1-ipaddresspool?timeout=10s\": context deadline exceeded",
"reason": "InternalError",
"details": {
"causes": [
{
"message": "failed calling webhook \"ipaddresspoolvalidationwebhook.metallb.io\": failed to call webhook: Post \"https://metallb-webhook-service.metallb-system.svc:443/validate-metallb-io-v1beta1-ipaddresspool?timeout=10s\": context deadline exceeded"
}
]
},
"code": 500
}Now the cluster is running the control plane as OS services (i.e. not kubeadm). Doesn't this usually mean that in-cluster webhooks need to have Was unable to redeploy the controller on the host network as it has a port clash, I'm guessing with the speaker pod that's on the same worker. This is the cluster configuration. Note that this is purely a learning exercise for K8s students, however some are asking to extend the exercise to deploy ingress and I thought it would be good to try it with MetalLB. Note that I have successfully installed the same chart version on a kubeadm cluster. |
|
Hello! I've deployed Metallb Operator on OKD 4.11 and I'm trying now to configure the address pool via: respectively and I get following error message:
"NO_PROXY" also covers .svc Already tried disabling the webhook by which didn't work for me. |
|
My secret and webhook don't have any values for UPDATE: I deleted the controller pod and both the secret and the webhook certs were recreated. UPDATE 2: A few hours later both the secret, and the webhook had no value for the caBundle again..... I suspect this is due to using ArgoCD via |
|
We started hitting this issue in our CI after migrating to kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/namespace.yaml
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/metallb.yaml
kubectl -n metallb-system wait deploy/controller --timeout=90s --for=condition=Available
kubectl apply -f ./metal_lb_cm.yamlI noticed that in kind, metallb-system controller-6846c94466-bn2qx 0/1 Running 0 15s
metallb-system speaker-6t6x8 0/1 CreateContainerConfigError 0 15s
metallb-system speaker-6t6x8 0/1 Running 0 17s
metallb-system controller-6846c94466-bn2qx 1/1 Running 0 20s
metallb-system speaker-6t6x8 1/1 Running 0 30sworkaround that seems to be working so far for us is waiting until all pods (speaker & controller) are ready: kubectl -n metallb-system wait pod --all --timeout=90s --for=condition=Ready
kubectl -n metallb-system wait deploy controller --timeout=90s --for=condition=Available
kubectl -n metallb-system wait apiservice v1beta1.metallb.io --timeout=90s --for=condition=Available
kubectl apply -f ./metal_lb_addrpool.yamlour --- Metal LB config:
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: example
namespace: metallb-system
spec:
addresses:
- 172.18.255.200-172.18.255.255
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: empty
namespace: metallb-systemposting as fyi, in case anyone is looking for a workaround in kind. |
|
Experiencing same issue with webhook failure. |
It's in the first post. Also, if you are using helm to deploy, you can use this value https://github.com/metallb/metallb/blob/main/charts/metallb/values.yaml#L332 from the last release. |
|
Hello! Same Issue, Env: |
|
Originally went I did a fresh install, I opted out of installing cilium-proxy and went with the default kube-proxy I tried everything under the sun for a month, but ultimately it came down to metallb not working with my kube-proxy but it worked with cilium-proxy. I never found the error for this in the end and I am not saying kube-proxy doesn't work but did come down to something in my proxy configuration or node configuration. Hope this helps. |
Similar situation here using kind. I tested the following configurations:
So it does seem to be connected to the proxy networking in my case as well as @jmcgrath207's. |
|
Hello, I followed the guide in the first comment and everything worked but I'm still getting the error. I want to try disabling the webhook but I'm using I'm pretty new to kurbenettes, any help would be greatly appreciated. |
|
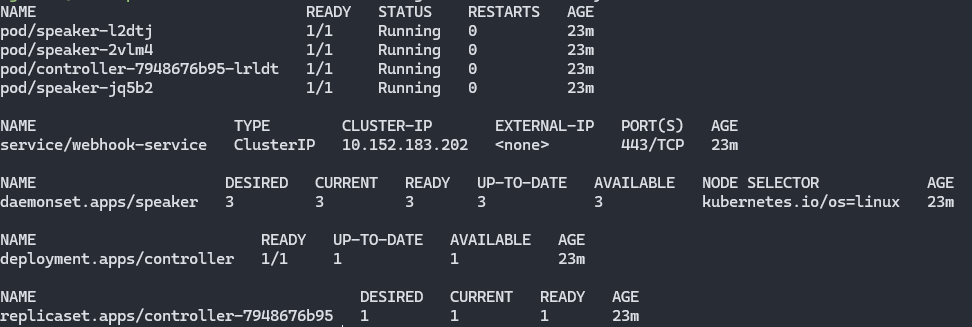
I have a 3 Node cluster running and got the following messages when i tried to apply IPAddressPools and L2Advertisment. Every pod is also running: The errors changed once i disabled the firewall. |
|
Hi All, I performed the checks from initial post. I checked every node in the cluster - all good with certificate: but API Server is still unable to make a call: Could someone please suggest what else to check? I'm happy to provide logs to get certs issue finally sorted out. |
|
Have you try disabling the firewalls of your nodes?. |
|
I fixed this issue by scheduling the controller pod to the master node. |
|
To resolve this issue, you can try the following steps: Look for a pod with a name similar to metallb-controller-xxxxx to confirm if it's running. If you get any error, you may need to change end of the command above with this: After all of this, you can apply metallb-adrpool.yaml and metallb-12.yaml this is the content of my YAML files; metallb-12.yaml |
|
For v0.13.10 Ignore some webhook configs works for me: 2009 path: /validate-metallb-io-v1beta1-ipaddresspool 2029 path: /validate-metallb-io-v1beta1-l2advertisement |
|
This issue has been automatically marked as stale because it has been open 30 days
|
This is what fixed it for me! Add to the pod spec |
For me it also worked. But why? |
|
I've encountered an issue that seems related to the problem discussed here, specifically while configuring MetalLB on an RKE2 cluster running in VMs provisioned by Vagrant on my local machine (VirtualBox). The VMs have two network interfaces: the first one is a NAT interface that Vagrant always configures (including SSH port forwarding rules for provisioning), and I've added a second interface, which is bridged to my host machine's physical interface to make the VMs part of my local subnet. When I shut down the VMs and remove the NAT interface, leaving only one interface, everything works as expected. I'm eager to understand why this might be happening and how to overcome this limitation. Any insights or potential fixes would be greatly appreciated. |
same problems i find i have proxy config when i delete them everything ok |
My setup is kubeadm cluster on raspberry pi's. Default helm installation of metallb. I was getting the following error trying to apply configs: Error from server (InternalError): error when creating "STDIN": Internal error occurred: failed calling webhook "ipaddresspoolvalidationwebhook.metallb.io": failed to call webhook: Post "https://metallb-webhook-service.metallb-system.svc:443/validate-metallb-io-v1beta1-ipaddresspool?timeout=10s": dial tcp 10.98.186.109:443: connect: connection refused
Error from server (InternalError): error when creating "STDIN": Internal error occurred: failed calling webhook "l2advertisementvalidationwebhook.metallb.io": failed to call webhook: Post "https://metallb-webhook-service.metallb-system.svc:443/validate-metallb-io-v1beta1-l2advertisement?timeout=10s": dial tcp 10.98.186.109:443: connect: connection refusedYour solution fixed this for me. Specifically:
I really wish we had a bit of understanding of why the pod running on the master node fixes this issue? I do not have firewalls installed on my worker nodes. In either case, thank you @bejay88! |
|
Ok, so we tried a few different things to get this to work and I thought I'd report in how we've worked around the issue. First some context. We deploy metallb via helm via ansible.
So I don't know why it needs to be on the control plane but the solution for us was to change the values.yaml file in the helm chart to add the following to the It was around line 230 in the version of the values.yaml file we have that isn't heavily modified. I'd be really curious as to the actual reason it works on the control-plane node but not any others. I don't know if that is a legitimate bug or if something about our cluster is at fault for that. |
|
Ok, so upon further investigation this has turned out to be a firewall issue. Our ansible scripts were doing the following: Once we ensured the firewall had been restarted prior to applying the L2Advertisement/IPAddressPool config then applying the config it worked without fail. Our setup is using rke2 1.25 and the firewall was setup per the guidelines. |
|
This issue has been automatically marked as stale because it has been open 30 days
|
|
This issue was automatically closed because of lack of activity after being marked stale in the |
|
Opening port 8472/udp on all nodes fixed it for me. |
|
I too had this issue, and it turned out to be a firewall issue where the controller pod could not receive the web hook calls. I use Rancher with project network isolation activated for my cluster. That creates a rule in each namespace that is supposed to allow all communication to/from the nodes (since that is required for many system functions, like webhooks). Unfortunately, I use Cilium which has a bug that prevents such policies to work: cilium/cilium#12277 I debugged this by using Hubble to inspect the traffic flow:
|
This approach worked for me also. Thanks. It's like a Saviour. |
This is an umbrella issue to try to provide troubleshooting information and to collect all the webhook related issues:
#1563
#1547
#1540
A very good guide that can be applied also to metallb is https://hackmd.io/@maelvls/debug-cert-manager-webhook
Please note that the service name / webhook name might be slightly different when consuming the helm charts or the manifest.
Given a webhook failure, one must check
if the metallb controller is running and the endpoints of the service are healthy
If the caBundle is generated and the configuration is patched properly
To get the caBundle used by the webhooks:
kubectl get validatingwebhookconfiguration metallb-webhook-configuration -ojsonpath='{.webhooks[0].clientConfig.caBundle}' | base64 -dTo get the caBundle from the secret:
kubectl -n metallb-system get secret webhook-server-cert -ojsonpath='{.data.ca\.crt}' | base64 -dThe caBundle in the webhook configuration and in the secret must match, and the raw version you get from
kubectl -n metallb-system get secret webhook-server-cert -ojsonpath='{.data.ca\.crt}'must be different from the default dummy one that can be found here:metallb/config/crd/crd-conversion-patch.yaml
Line 15 in 93755e1
Test if the service is reacheable from the apiserver node
Find the webhook service cluster ip:
Fetch the caBundle:
Move the caBundle.pem file to a node, and from the node try to curl the service, providing the resolution from the service fqdn to the service's clusterIP (in this case, 10.96.50.216):
The expected result is the webhook complaining about missing content:
But that will guarantee the certificate is valid.
In case the connection times out:
The instructions at https://hackmd.io/@maelvls/debug-cert-manager-webhook#Error-2-io-timeout can be followed.
Use tcpdump on port 443 to see if the traffic from the apiserver is directed to the endpoint (the controller pod's ip in this case).
How to disable the webhook
A very quick workaround is to disable the webhook, which requires changing its failurePolicy to
failurePolicy=IgnoreThe text was updated successfully, but these errors were encountered: