基于workflow 做postrgre v3 通信协议,需要注意那些事项? #766
Comments
|
非常的可以啊。 |
|
你可以发一下协议描述我看看。 |
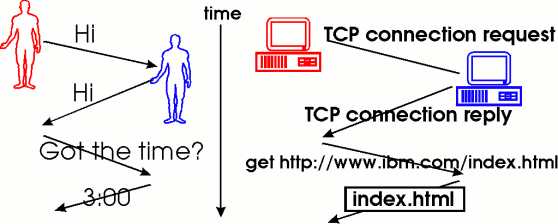
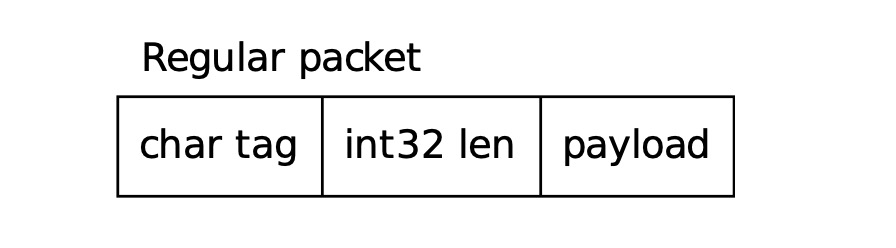
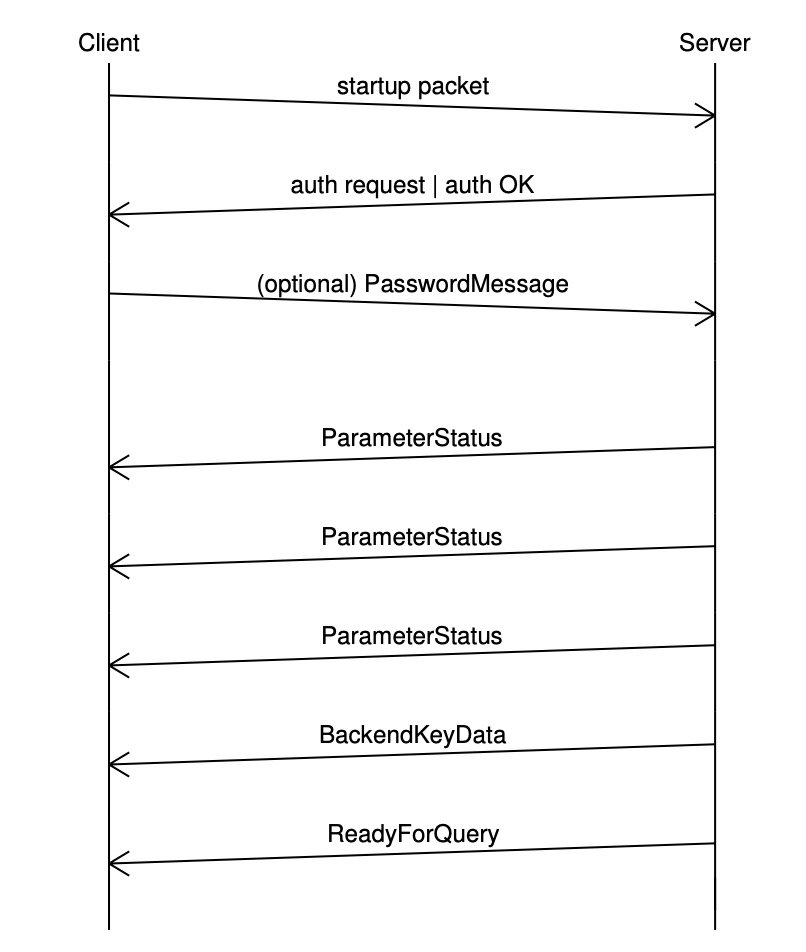
PostgreSQL 通信协议简介: 我们在使用数据库服务时,通常需要使用客户端连接数据库服务端,以 PostgreSQL 为例,常用的客户端有自带的 psql,JAVA 应用的数据库驱动 JDBC,可视化工具 PgAdmin 等,这些客户端都需要遵守 PostgreSQL 的通信协议才能与之 "交流"。所谓协议,可以理解为一套信息交互规则或者规范,最为我们熟知的莫过于 TCP/IP 协议和 HTTP 协议。 。 消息类型PostgreSQL 目前支持如下客户端消息类型: 服务端收到如上消息的处理流程可以参考 [PostgresMain](https://github.com/postgres/postgres/blob/bf68b79e50e3359accc85c94fa23cc03abb9350a/src/backend/tcop/postgres.c#L4277)。服务端发送给客户端的消息有如下类型(不完全): 客户端处理如上服务端消息的流程可以参考 PostgreSQL libqp 的实现 [pqParseInput3](https://github.com/postgres/postgres/blob/c9d29775195922136c09cc980bb1b7091bf3d859/src/interfaces/libpq/fe-protocol3.c?spm=a2c6h.12873639.0.0.265b2eeerGaO34#L63)。 消息流Startup
客户端首先发送 取消请求在 取消请求并不是通过当前正在处理请求的连接发送的,而是会创建一个新的连接,创建该连接发送的消息与之前创建连接的消息不同,不再发送 取消请求不保证一定成功,可能服务端接收到取消请求时,当前的查询请求已经结束。取消请求只能在一定程度上加速当前查询结束,如果当前请求被取消,客户端会收到一条错误消息。 发送请求连接创建之后,通信协议进入 Simple Query客户端通过 每个命令的结果发送完成之后,服务端会发送一条 注意,一个请求中的多条 SQL 命令会被当做一个事务来执行,如果有命令执行失败,整个事务都会回滚。用户可以在请求中显式添加
Extended QueryExtended Query 协议将以上 Simple Query 的处理流程分为若干步骤,每一步都由单独的服务端消息进行确认。该协议可以使用服务端的 perpared-statement 功能,即先发送一条参数化 SQL,服务端收到 SQL(Statement)之后对其进行解析、重写并保存,这里保存的 Statement 也就是所谓 Prepared-statement,可以被复用;执行 SQL 时,直接获取事先保存的 Prepared-statement 生成计划并执行,避免对同类型 SQL 重复解析和重写。 如下例, 可见,Extended Query 协议通过使用服务端的 Prepared Statement,提升同类 SQL 多次执行的效率。但与 Simple Query 相比,其不允许在一个请求中包含多条 SQL 命令,否则会报语法错误。 Extended Query 协议通常包括 5 个步骤,分别是 Parse,Bind,Describe,Execute 和 Sync。以下分别介绍各个阶段的处理流程。 Parse客户端首先向服务端发送一个 PostgreSQL 服务端收到该消息后,调用 Bind客户端发送 PostgreSQL 收到该消息后,调用
Describe客户端可以发送 Execute客户端发送
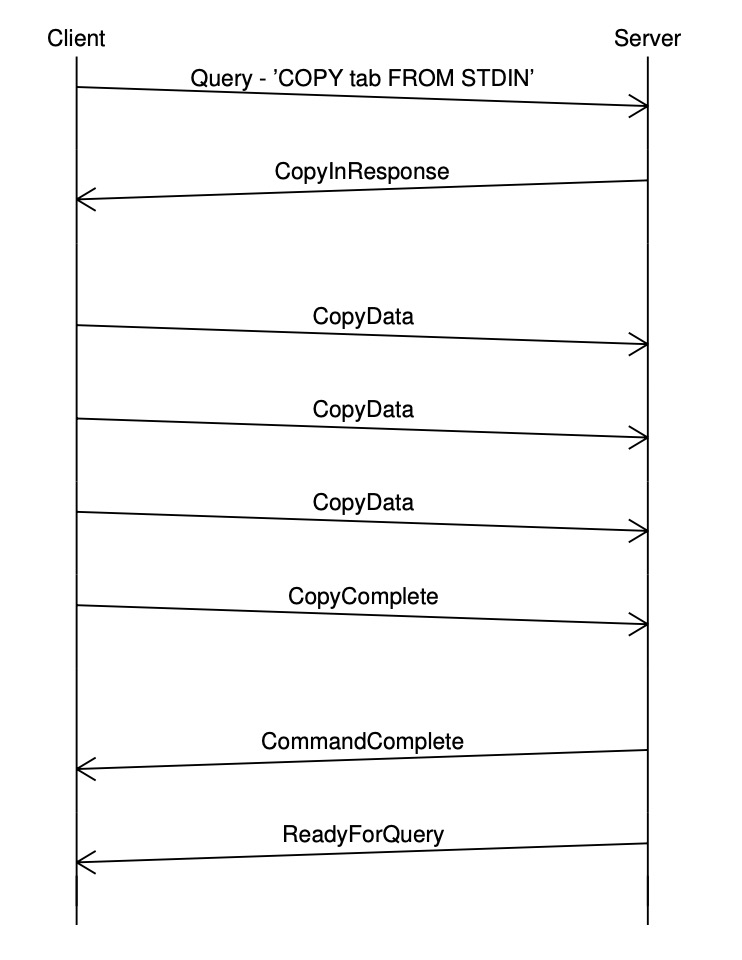
Sync使用 Extended Query 协议时,一个请求总是以 Extended Query 完整的消息流如下: Copy 子协议为高效地导入/导出数据,PostgreSQL 支持 Copy 子协议对应三种模式:
以 总结本文简要介绍了 PostgreSQL 的通信协议,包括消息格式、消息类型和常见通信过程的消息流。一般通信过程分为两个阶段: PostgreSQL 通信协议中,除本文介绍的 最后,本文严重参考了 2014 年 PG 大会这篇[6]分享,推荐大家阅读。 参考文献
本节描述每个消息报文的具体格式。报文上标注了发送方:前端(F)、后端(B)、双方(F&B)。注意,尽管每个报文在开始处都包含一个字节数,消息格式的结束可以不在字节数引用中。其目标是合法性检测。(CopyData报文是个例外,因为他的格式部分与数据流;任何非法CopyData数据都无法被中断)。 AuthenticationOK (B)
AuthenticationKerberosV5 (B)
AuthenticationCleartextPassword (B)
AuthenticationCryptPassword (B)
AuthenticationMD5Password (B)
AuthenticationSCMCredential (B)
AuthenticationGSS (B)
AuthenticationSSPI (B)
AuthenticationGSSContinue (B)
BackendKeyData (B)
Bind (F)
随后是每个参数的字段对:
在最后一个参数后的字段:
BindComplete (B)
CancelRequest (F)
Close (F)
CloseComplete (B)
CommandComplete (B)
CopyData (F&B)
CopyDone (F&B)
CopyFail (F)
CopyInResponse (B)
CopyOutResponse (B)
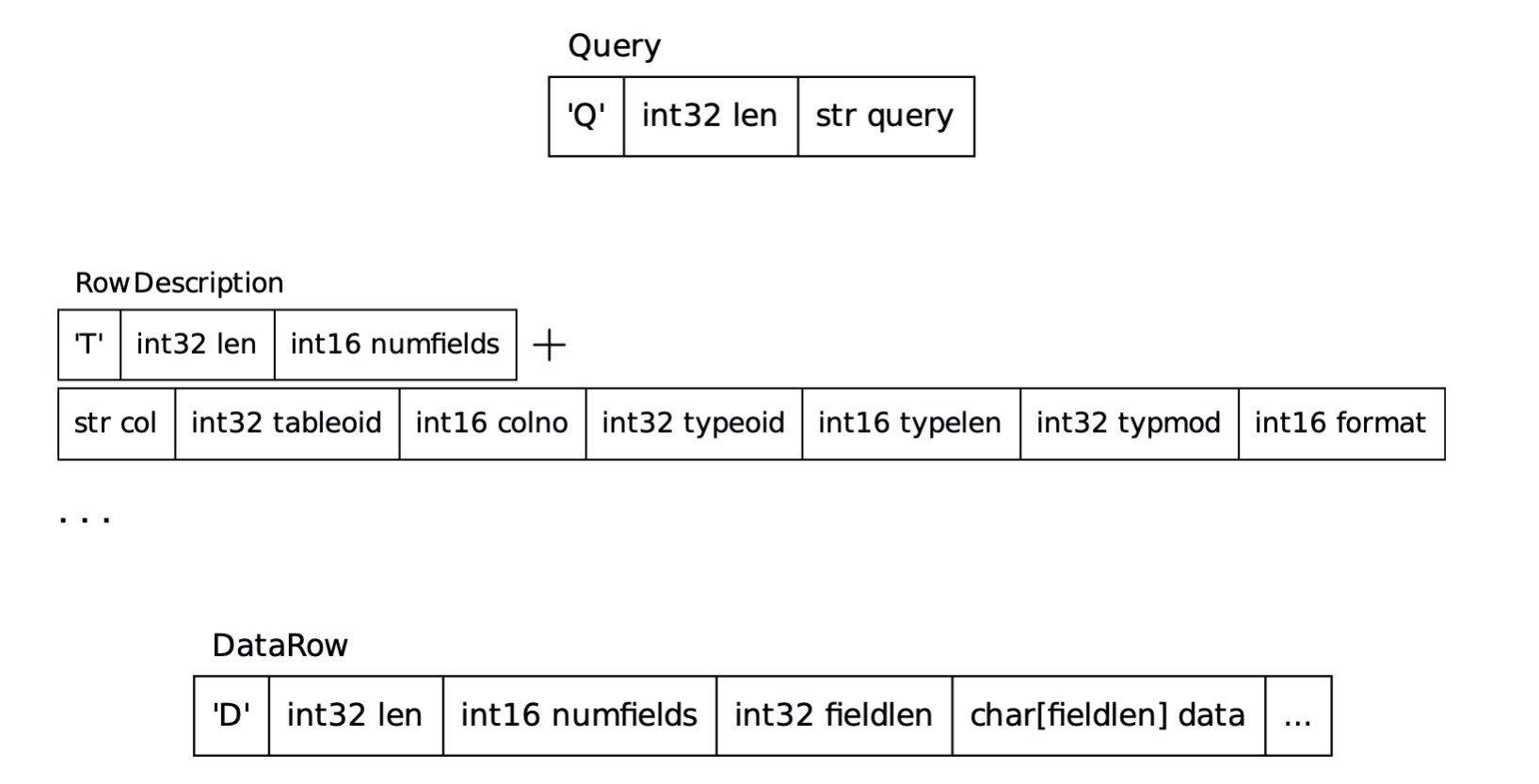
DataRow (B)
接下来的是每一列的字段对:
Describe (F)
EmptyQueryResponse (B)
ErrorResponse (B)
消息体由一个或多个字段组成,以null结尾,字段可以任何顺序出现,对每个字段应该有:
Execute (F)
Flush (F)
FunctionCall (F)
下面是每个参数的字段对:
在这些参数后,跟随的字段:
FunctionCallResponse (B)
NoData (B)
NoticeResponse (B)
消息体由一个或多个字段构成,跟随0表示结束符。字段可以用任何顺序显示,每个字段为:
NotificationResponse (B)
ParameterDescription (B)
下面对每个参数:
ParameterStatus (B)
Parse (F)
然后对每个参数:
ParseComplete (B)
PasswordMessage (F)
PortalSuspended (B)
Query (F)
ReadyForQuery (B)
RowDescription (B)
然后就是各个字段了
SSLRequest (F)
StartupMessage (F)
协议版本号之后就是多个键值对,最后一个键值对结尾要有null字符,键值对参数可以用任何顺序出现, user 是必须的,其他都可选。
Sync (F)
Terminate (F)
5 错误与提示信息字段 [Error and Notice Message Fields](https://link.zhihu.com/?target=http%3A//www.postgresql.org/docs/8.3/static/protocol-error-fields.html) 本节描述ErrorResponse和NoticeResponse报文中的字段。每个字段类型有一个单一字节记号(token)。注意每个给定字段至少出现在一个报文中。 S(Severity) :严重程度,字段内容是ERROR、FATAL、PANIC(在错误信息中)、WARNING、NOTICE、DEBUG、INFO、LOG(在notice信息中)或本地翻译。 C(Code) :错误的SQLSTATE代码,非本地化的 M(Message) :人类可读的错误信息,一般很短且只有1行 D(Detail) :可选的第二错误信息,包含问题的详细描述,可能多行 H(Hint) :可选的问题建议,建议不同于detail的是包含建议,可能多行 P(Position) :字段值的ASCII码整数,引用错误查询语句的光标位置,第一个字符是1,以字符引用,而不是字节 p(internal position) :定义类似于P字段,只不过用于引用内部生成命令的错误位置,当这个字段显示则q字段也总是显示 q(internal query) :内部生成的查询命令,例如PL/pgSQL函数 W(Where) :一段索引正文,包括调用栈和当前处理语言函数的内部查询,每行一个 F(File) :发生错误的源码文件名 L(Line) :发生错误的源码行号 R(Routine) :发生错误的源码常规 客户端选择如何显示这些信息,一般至少应该对较长的行来折行,以及分段。 7.3 密码确认 客户端连接服务器,服务器如果要求密码,则客户端会不发送任何数据包立刻断开,等待用户输入完密码以后重新连接。至少psql命令就是如此。 实际的MD5密码生成方法为: result='md5'+md5sum(md5sum(password+username)+saltstr) 7.4 错误码 一个没有找到表的基本错误信息 'S\xe9\x94\x99\xe8\xaf\xaf\x00C42P01\x00M\xe5\x85\xb3\xe7\xb3\xbb "testtest" \xe4\xb8\x8d\xe5\xad\x98\xe5\x9c\xa8\x00Fnamespace.c\x00L273\x00RRangeVarGetRelid\x00\x00' 。其中分解开就是每一小段以一个字母开头,随后是NULL结尾字符串。最后再加一个NULL。这些开头的字母如上面讲解的。 其中C(CODE)字段存储的是SQLSTATE,这是个5字节数组。这5个字节中可以包含数字和大写字母,前2个字符代表基本错误类,后3个字符表示错误子类。成功的SQLSTATE是"00000"。这些都是SQL标准定义的。建议以后都使用SQLSTATE而不是各个数据库自己的错误码。 一些SQLSTATE示例: [http://www.postgresql.org/docs/8.3/static/errcodes-appendix.html](https://link.zhihu.com/?target=http%3A//www.postgresql.org/docs/8.3/static/errcodes-appendix.html) SQLSTATE与错误码: [Documentation: 8.3: Error Handling](https://link.zhihu.com/?target=http%3A//www.postgresql.org/docs/8.3/static/ecpg-errors.html) 几个常用的:
7.5 结果集的定义 使用RowDescription包。 一个结果集定义 \x00\x01name\x00\x00\x00@\x03\x00\x02\x00\x00\x04\x13\xff\xff\x00\x00\x00D\x00\x00 。其中字段定义如下:
实际这是一个VARCHAR类型的字段。即类型代码1043对应varchar类型。具体的类型映射表可以进入PGSQL自己查询,使用 SELECT typname,oid FROM pg_type; ,我使用8.3.11,其中有269个返回结果。列出几个常用的:
|


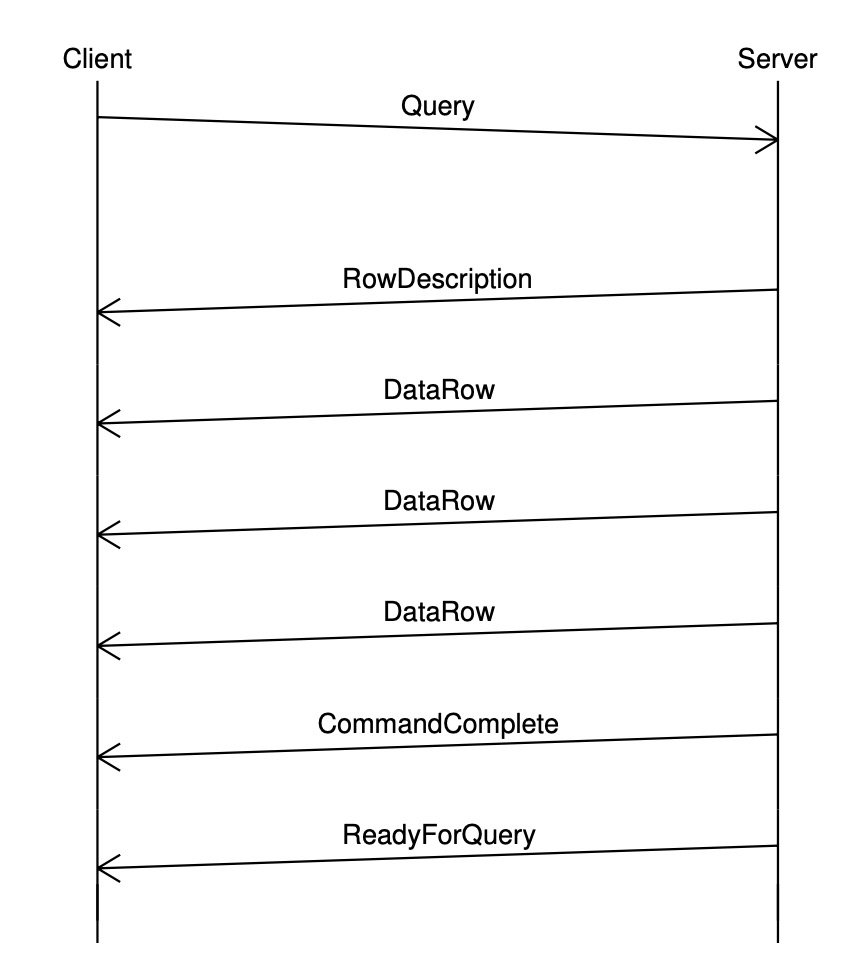

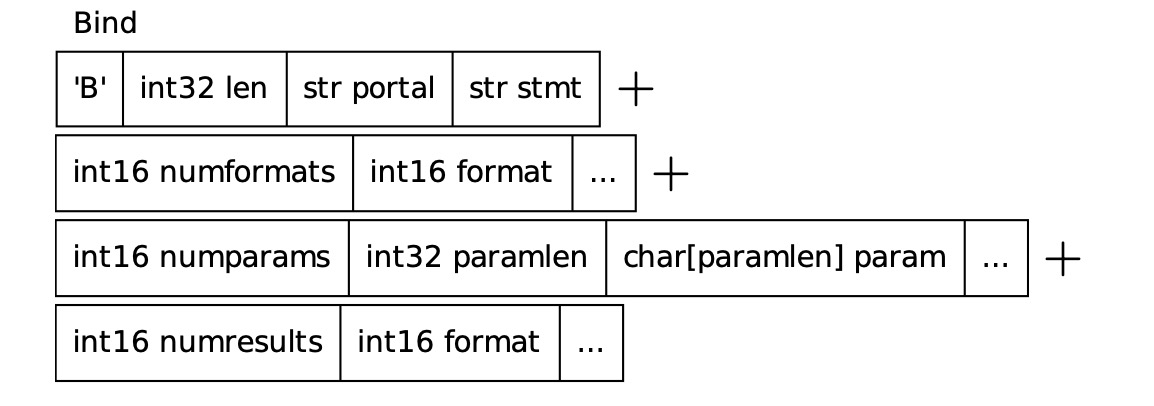

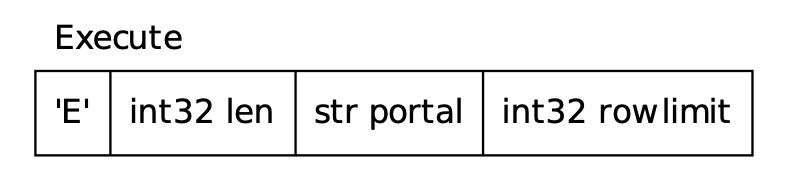
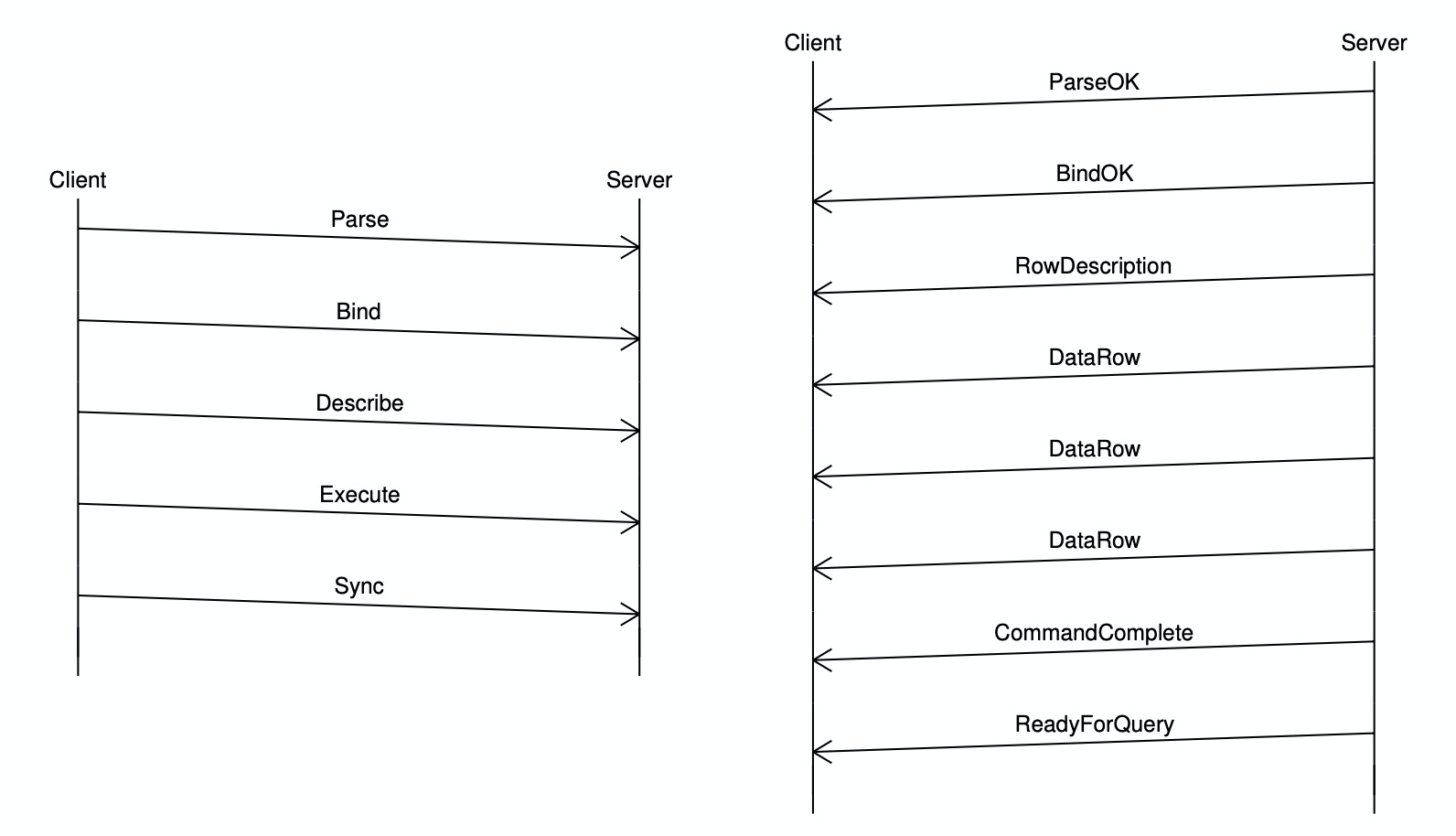
|
大概看了一下,Postgre的消息比mysql实在友好太多了。整个登录阶段可以一次交互搞定。 |
我单位数据库都是基于都是postgresql,应用workflow高性能就需要从协议层入手。但我们对于workflow 框架协议部分底层不能很熟悉,所以想得到你们的指定!
The text was updated successfully, but these errors were encountered: