7 funções simples do JavaScript que farão você ter uma ideia de como as máquinas podem "aprender" literalmente.
Em outros idiomas: Русский, English
Você também pode se interessar por 🤖 Experimentos interativos de Machine Learning (em inglês)
NanoNeuron é uma versão bem simples do conceito de Neurônio em uma Rede Neural. NanoNeuron é treinado para converter valores de graus Celsius em Fahrenheit.
O código de exemplo NanoNeuron.js contém 7 simples funções JavaScript (sobre predição de modelo, cálculo de custo, propagação e retropropagação, e treinamento) que irá te dar a visão de como as máquinas podem literalmente "aprender". Sem bibliotecas de terceiros, sem conjuntos de dados externos ou dependências, apenas simples e puramente funções JavaScript.
☝🏻Essas funções NÃO são, de nenhuma forma, um guia completo para aprendizado de máquina ("machine learning" em inglês). Um monte de conceitos de machine learning foram desconsiderados e muito simplificados! Essa simplificação foi feita com o propósito de dar ao leitor apenas um entendimento básico da visão de como as máquinas podem aprender e por fim para tornar possível para o leitor reconhecer que isso não é um "aprendizado MÁGICO de máquina" mas sim um "aprendizado MATEMÁTICO de máquina" 🤓.
Provavelmente você já ouviu falar sobre Neurônios no contexto de Redes Neurais. NanoNeuron é isso mas de forma simples e vamos implementar desde o início. Para efeitos de simplicidade nós não iremos construir uma rede de NanoNeuron. Teremos tudo funcionando no mesmo lugar, fazendo algumas predições mágicas para nós. Só pra você saber, vamos ensinar esse NanoNeuron a converter (predizer) a temperatura em graus Celsius para Fahrenheit.
A propósito, a fórmula para converter graus Celsius em Fahrenheit é essa:

Mas por enquanto nosso NanoNeuron não sabe disso...
Vamos implementar nossa função de modelo do NanoNeuron. Ela implementa uma dependência linear básica entre x e y que se parece com y = w * x + b. Basicamente, nosso NanoNeuron é uma "criança" na "escola" aprendendo a desenhar uma linha reta nas coordenadas XY.
Variáveis w, b são parâmetros do modelo. NanoNeuron só conhece esses dois parâmetros da função linear. Eles são algo que NanoNeuron irá "aprender" durante o processo de treinamento.
A única coisa que o NanoNeuron pode fazer é imitar a dependência linear. No método predict() é aceito um dado de entrada x e prediz a saída y. Nenhuma mágica aqui.
function NanoNeuron(w, b) {
this.w = w;
this.b = b;
this.predict = (x) => {
return x * this.w + this.b;
}
}(...espera... regressão linear é você?) 🧐
A temperatura em graus Celsius pode ser convertida para Fahrenheit usando a seguinte fórmula: f = 1.8 * c + 32, onde c é a temperatura em graus Celsius e f a temperatura calculada em Fahrenheit.
function celsiusToFahrenheit(c) {
const w = 1.8;
const b = 32;
const f = c * w + b;
return f;
};Queremos que o nosso NanoNeuron imite essa função (para aprender que w = 1.8 e b = 32) sem conhecer esses parâmetros antecipadamente.
Assim é como a função de conversão de graus Celsius para Fahrenheit irá parecer:

Antes do treinamento nós precisamos treinar e testar os dados baseando-se na função celsiusToFahrenheit(). Os conjuntos de dados consistem em pares de valores de entrada e valores de saída corretamente calculados.
Na vida real, na maioria dos casos, esses dados são coletados ao invés de gerados. Por exemplo, podemos ter um conjunto de imagens de números desenhados à mão e o conjunto com os números que explicam qual é o número escrito em cada imagem.
Usaremos os dados de exemplo de TREINAMENTO para treinar nosso NanoNeuron. Antes dele crescer e ser capaz de fazer decisões sozinho, precisamos ensiná-lo o que é certo e o que é errado usando os exemplos de treinamento.
Usaremos os exemplos de TESTE para avaliar o quanto nosso NanoNeuron performa bem nos dados que ele nunca viu durante o treinamento. Esse é o ponto onde podemos ver que a nossa "criança" cresceu e pode tomar decisões sozinha.
function generateDataSets() {
// xTrain -> [0, 1, 2, ...],
// yTrain -> [32, 33.8, 35.6, ...]
const xTrain = [];
const yTrain = [];
for (let x = 0; x < 100; x += 1) {
const y = celsiusToFahrenheit(x);
xTrain.push(x);
yTrain.push(y);
}
// xTest -> [0.5, 1.5, 2.5, ...]
// yTest -> [32.9, 34.7, 36.5, ...]
const xTest = [];
const yTest = [];
// Ao começar com 0,5 e usar o mesmo incremento de 1 como usamos para o conjunto
// de treinamento, temos certeza que teremos dados diferentes para comparar.
for (let x = 0.5; x < 100; x += 1) {
const y = celsiusToFahrenheit(x);
xTest.push(x);
yTest.push(y);
}
return [xTrain, yTrain, xTest, yTest];
}Precisamos ter alguma métrica que nos mostre o quão perto nosso modelo de predição está dos valores corretos. O cálculo do custo (o engano) entre o valor correto calculado de y e a prediction, que o nosso NanoNeuron criou, será feito usando a seguinte fórmula:
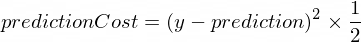
Esse é uma simples diferença entre dois valores. O quanto mais perto os valores estão um do outro, menor a diferença. Estamos usando uma potência de 2 aqui apenas para se livrar dos números negativos de forma que (1 - 2) ^ 2 será o mesmo que (2 - 1) ^ 2. Divisão por 2 acontece apenas para simplificar depois a fórmula de retropropagação (veja abaixo).
A função de custo nesse caso, será tão simples quanto:
function predictionCost(y, prediction) {
return (y - prediction) ** 2 / 2; // ex.: -> 235.6
}Propagação ("forward propagation" em inglês) significa fazer uma predição de todos os exemplos de treinamento para os conjuntos de dados xTrain e yTrain e para calcular o custo médio dessas predições no meio do caminho.
Vamos apenas deixar nosso NanoNeuron dizer sua opinião nesse momento, permitindo-o adivinhar como converter a temperatura. Ele deve estar estupidamente errado nessa fase. O custo médio nos mostrará o quão errado nosso modelo está agora. Esse valor de custo é realmente importante visto que alterando os parâmetros NanoNeuron w e b e fazendo a propagação novamente, estaremos aptos a avaliar depois se nosso NanoNeuron se tornou esperto ou não conforme os parâmetros mudam.
O custo médio será calculado usando a seguinte fórmula:
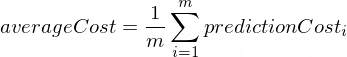
Onde m é o número de exemplos de treinamento (no nosso caso: 100).
Esta é a forma como devemos implementar no código:
function forwardPropagation(model, xTrain, yTrain) {
const m = xTrain.length;
const predictions = [];
let cost = 0;
for (let i = 0; i < m; i += 1) {
const prediction = nanoNeuron.predict(xTrain[i]);
cost += predictionCost(yTrain[i], prediction);
predictions.push(prediction);
}
// Estamos interessados no custo médio
cost /= m;
return [predictions, cost];
}Quando conhecemos o quão certo ou errado nossas predições do NanoNeuron estão (baseado no custo médio a este ponto) o que devemos fazer para tornar essas predições mais precisas?
A retropropagação nos dá a resposta para essa questão. retropropagação (Backward propagation em inglês) é o processo de avaliar o custo da predição e ajustar os parâmetros do NanoNeuron w e b para que as próximas e futuras predições sejam mais precisas.
Isso é onde o aprendizado de máquina se parece com mágica 🧞♂️. O conceito chave aqui é a derivada que nos mostra qual passo dar para chegar perto do custo mínimo da função.
Lembre-se, encontrar o custo mínimo da função é o objetivo final do processo de treinamento. Se encontrarmos ambos valores de w e b de forma que o custo médio da nossa função seja pequeno, isso significa que o modelo NanoNeuron fez predições ótimas e precisas.
Derivada é um grande e separado tópico que não iremos cobrir neste artigo. Wikipedia pode te ajudar a entender melhor sobre isso.
Uma coisa sobre as derivadas que irá te ajudar a entender como a retropropagação funciona é que a derivada é ela representa a inclinação da reta tangente ao gráfico desta função em um determinado ponto.

Origem da imagem: MathIsFun
Por exemplo, no gráfico acima, você pode ver que se estivermos no ponto (x=2, y=4) então a inclinação nos diz para ir para a esquerda e para baixo para obter a função mínima. Note também que quanto maior a inclinação, mais rápido nos movemos para o mínimo.
As derivadas da nossa função averageCost (custo médio em inglês) para os parâmetros w e b se parecem com:
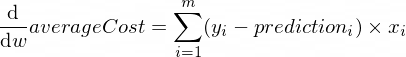
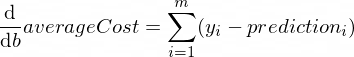
Onde m é o número de exemplos de treinamento (no nosso caso: 100).
Você pode aprender mais sobre as regras das derivadas e como obter uma derivada de funções complexas aqui ou na indicação do autor original (em inglês).
function backwardPropagation(predictions, xTrain, yTrain) {
const m = xTrain.length;
// No começo não conhecemos de que forma nossos parâmetros 'w' e 'b' precisam ser alterados.
// Portanto vamos configurar cada parâmetro para 0.
let dW = 0;
let dB = 0;
for (let i = 0; i < m; i += 1) {
dW += (yTrain[i] - predictions[i]) * xTrain[i];
dB += yTrain[i] - predictions[i];
}
// Estamos interessados em deltas médios de cada parâmetro.
dW /= m;
dB /= m;
return [dW, dB];
}Agora que sabemos como avaliar a exatidão do nosso modelo para todo o conjunto de exemplos (propagação), nós precisamos também saber como fazer pequenos ajustes nos parâmetros w e b do nosso modelo (retropropagação). Mas o problema é que se rodarmos apenas uma vez a propagação e a retropropagação, não será o suficiente para o nosso modelo aprender qualquer lei/tendência dos dados de treinamento. Você deve comparar isso com um dia da escola primária para a criança. Ela deve ir para a escola não apenas uma vez, mas dia após dia e ano após ano para aprender algo.
Então precisamos repetir as propagações do nosso modelo várias vezes. Isto é exatamente o que a função trainModel() faz. É como um "professor" para nosso modelo do NanoNeuron:
- ela irá passar um tempo (
epochs) com o nosso ligeiro modelo do NanoNeuron e tentará treiná-lo/ensiná-lo, - usará "livros" específicos (os conjuntos de dados
xTraineyTrain) para treinar, - irá forçar nossa criança a aprender pesado (rápido) usando um parâmetro de ajuste
alpha.
Uma nota sobre a taxa de aprendizado alpha. Ela é simplesmente um multiplicador dos valores de dW e dB que calculamos durante a retropropagação. Assim, as derivadas nos apontam para a direção que precisamos para obter a função de custo mínimo (indicadores dW e dB) e isso nos mostra também o quão rápido precisamos ir naquela direção (valores absolutos de dW e dB). Então precisamos multiplicar o tamanho dos passos de alpha para ajustar nosso movimento ao mínimo, mais rápido ou mais devagar. Algumas vezes se usarmos um valor alto para alpha, vamos simplesmente passar do mínimo e nunca vamos encontrá-lo.
A analogia com o professor pode ser que quanto mais ele força nossa "criança nano" a ser mais rápida, ela irá aprender, mas se forçarmos demais, a "criança" terá um ataque de nervos e não será capaz de aprender nada 🤯.
Aqui é como vamos fazer para atualizar nossos parâmetros w e b do modelo:


E aqui está nossa função de treinamento:
function trainModel({model, epochs, alpha, xTrain, yTrain}) {
// Esse é o histórico de aprendizado do NanoNeuron.
const costHistory = [];
// Vamos começar enumerando as épocas
for (let epoch = 0; epoch < epochs; epoch += 1) {
// Propagação
const [predictions, cost] = forwardPropagation(model, xTrain, yTrain);
costHistory.push(cost);
// retropropagação
const [dW, dB] = backwardPropagation(predictions, xTrain, yTrain);
// Ajustar os parâmetros do nosso NanoNeuron para aumentar a acurácia do nosso modelo de predições.
nanoNeuron.w += alpha * dW;
nanoNeuron.b += alpha * dB;
}
return costHistory;
}Agora vamos usar as funções que criamos acima.
Vamos criar nossa instância do modelo do NanoNeuron. Nesse momento o NanoNeuron não sabe que valores deve usar nos parâmetros w e b. Então vamos colocar um valor qualquer em w e b.
const w = Math.random(); // ex: -> 0.9492
const b = Math.random(); // ex: -> 0.4570
const nanoNeuron = new NanoNeuron(w, b);Gerar os conjuntos de dados do treinamento e o de testes.
const [xTrain, yTrain, xTest, yTest] = generateDataSets();Vamos treinar nosso modelo com um pequeno incremento (0,0005) por passo para 70.000 épocas. Você pode brincar com esses parâmetros, eles foram definidos empiricamente.
const epochs = 70000;
const alpha = 0.0005;
const trainingCostHistory = trainModel({model: nanoNeuron, epochs, alpha, xTrain, yTrain});Vamos checar o quanto a função de custo mudou durante o treinamento. Esperamos que o custo após o treinamento seja menor que antes. Isso significa que o NanoNeuron se tornou esperto. O oposto também é possível.
console.log('Custo antes do treinamento:', trainingCostHistory[0]); // ex: -> 4694.3335043
console.log('Custo depois do treinamento:', trainingCostHistory[epochs - 1]); // ex: -> 0.0000024Isso é como o custo do treinamento muda através das épocas. No eixo x é a época multiplicada por 1000.
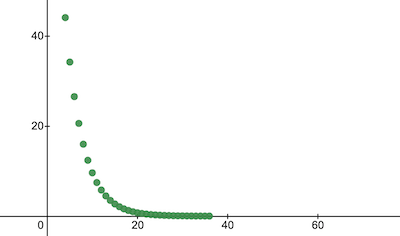
Vamos dar uma olhada nos parâmetros do NanoNeuron para ver o que ele aprendeu. Esperamos que os parâmetros w e b do NanoNeuron sejam similares com os que temos na função celsiusToFahrenheit() (w = 1.8 e b = 32) visto que treinamos o NanoNeuron para imitar isso.
console.log('Parâmetros NanoNeuron:', {w: nanoNeuron.w, b: nanoNeuron.b}); // ex: -> {w: 1.8, b: 31.99}Avalie a acurácia do modelo usando os dados de teste para ver o quanto o NanoNeuron se dá bem com predições de dados desconhecidos. É esperado que os custos das predições no conjunto de testes seja próximo do custo de treinamento. Isso pode significar que nosso NanoNeuron performa bem em dados que ele conhece e os que ele não conhece.
[testPredictions, testCost] = forwardPropagation(nanoNeuron, xTest, yTest);
console.log('Custo com novos dados de teste:', testCost); // ex: -> 0.0000023Agora, visto que nossa "criança" NanoNeuron performou bem na "escola" durante o treinamento e ele pode converter graus Celsius em Fahrenheit corretamente, mesmo para dados que nunca viu, podemos chamá-lo de "esperto" e perguntá-lo algumas coisas. Esse era o objetivo final de todo nosso processo de treinamento.
const tempInCelsius = 70;
const customPrediction = nanoNeuron.predict(tempInCelsius);
console.log(`NanoNeuron "acha" que ${tempInCelsius}°C em Fahrenheit é:`, customPrediction); // -> 158.0002
console.log('Resposta correta é:', celsiusToFahrenheit(tempInCelsius)); // -> 158Muito próximo! Para nós humanos, nosso NanoNeuron é bom, mas não ideal :)
Bom aprendizado para você!
Você pode clonar esse repositório e executá-lo localmente:
git clone https://github.com/trekhleb/nano-neuron.git
cd nano-neuronnode ./NanoNeuron.jsOs seguintes conceitos de machine learning foram pulados e simplificados para uma explicação mais simples.
Normalmente você tem um grande conjunto de dados. Dependendo do número de exemplos no conjunto, você pode querer dividi-lo em 70/30 para treino/teste. Os dados no conjunto devem ser embaralhados aleatoriamente antes da divisão. Se o número de exemplos é grande (ex: milhões) então a divisão acontece em proporções próximas a 90/10 ou 95/5 para treino/teste.
Normalmente você não observa o uso de apenas um neurônio independente. O poder está na rede neural desses neurônios. A rede pode aprender coisas muito mais complexas. NanoNeuron sozinho se parece mais com uma simples regressão linear do que uma rede neural.
Antes do treinamento, seria melhor normalizar os dados de entrada (em inglês).
Para redes neurais, cálculos vetorizados (matriz) trabalham muito mais rápido do que laços for. Normalmente as propagações (frente e trás) trabalham muito rápido se implementadas de forma vetorizada e calculadas usando, por exemplo uma biblioteca Python Numpy.
A função de custo que estamos usando nesse exemplo é muito simplificada. Deveria ter componentes logarítmicos (em inglês). Alterando a função de custo também irá alterar suas derivadas então o passo de retropropagação também deveria usar fórmulas diferentes.
Normalmente a saída do neurônio deveria passar por uma função de ativação como a Sigmoid ou a ReLU ou outras.