Natural language processing is a field of computer science and linguistics concerned with the interactions between computers and human (natural) languages. In its simplest form, NLP is about developing algorithms that can automatically understand and produce human language. The long-term goal of NLP is to create computational models of human language that can be used to perform a wide variety of tasks. These tasks include automatic translation, summarization, question answering, information extraction, and many others. NLP research is highly interdisciplinary, involving researchers from fields such as linguistics, cognitive science, artificial intelligence, and computer science.
There are many different methods used in natural language processing, including rule-based methods, statistical methods, and neural computed methods. Rule-based methods are usually based on hand-crafted rules that are written by NLP experts. These methods can be very effective for specific tasks, but they are often limited in their scope and require a lot of effort to maintain. Statistical methods are based on using large amounts of data to train computational models. These models can then be used to automatically perform various NLP tasks. Neural networks are a type of machine learning algorithm that is particularly well-suited for NLP tasks. Neural networks have been used to create state-of-the-art models for tasks such as machine translation and classification.
💬 Co:here
Co:here is a powerful neural network, which can generate, embed, and classify text. In this tutorial we will use Co:here to classify descriptions. To use Co:here you need to create account on Co:here and get API key.
We will be programming in Python, so we need to install cohere library by pip
pip install cohereFirstly, we have to implement cohere.Client. In arguments of Client should be API key, which you have generated before, and version 2021-11-08. I will create the class CoHere, it will be useful in the next steps.
class CoHere:
def __init__(self, api_key):
self.co = cohere.Client(f'{api_key}', '2021-11-08')
self.examples = []The main part of each neural network is a dataset. In this tutorial, I will use a dataset that includes 1000 descriptions of 10 classes. If you want to use the same, you can download it here.
The downloaded dataset has 10 folders in each folder is 100 files.txt with descriptions. The name of files is a label of description, e.g.sport_3.txt.
In this field, tasks are to read descriptions and labels from files and to create data, which contains description and label as one sample of data. Cohere classifier requires samples, in which each sample should be designed as a list [description, label].
In the beginning, we need to load all data, to do that. We create the function load_examples. In this function we will use three external libraries:
os.path to go into the folder with data. The code is executed in a path where is a python's file.py. This is an internal library, so we do not need to install it.
numpy this library is useful to work with arrays. In this tutorial, we will use it to generate random numbers. You have to install this library by pip pip install numpy.
glob helps us to read all files and folder names. This is an external library, so the installation is needed - pip install glob.
The downloaded dataset should be extracted in the folder data. By os.path.join we can get universal paths of folders.
folders_path = os.path.join('data', '*')In windows, a return is equal to data\*.
Then we can use glob method to get all names of folders.
folders_name = glob(folders_path)folders_name is a list, which contains window paths of folders. In this tutorial, these are the names of labels.
['data\\business', 'data\\entertainment', 'data\\food', 'data\\graphics', 'data\\historical', 'data\\medical', 'data\\politics', 'data\\space', 'data\\sport', 'data\\technologie']Size of Co:here training dataset can not be bigger than 50 examples and each class has to have at least 5 examples. With loop for we can get the names of each file. The entire function looks like that:
import os.path
from glob import glob
import numpy as np
def load_examples():
examples_path = []
folders_path = os.path.join('data', '*')
folders_name = glob(folders_path)
for folder in folders_name:
files_path = os.path.join(folder, '*')
files_name = glob(files_path)
for i in range(50 // len(folders_name)):
random_example = np.random.randint(0, len(files_name))
examples_path.append(files_name[random_example])
return examples_pathThe last loop is taking randomly 5 paths of each label and appending them into a new list examples_path.
Now, we have to create a training set. To make it we will load examples with load_examples(). In each path is the name of a class, we will use it to create samples. Descriptions need to be read from files, a length can not be long, so in this tutorial, the length will be equal to 100. To list texts is appended list of [descroption, class_name]. Thus, a return is that list.
def examples():
texts = []
examples_path = load_examples()
for path in examples_path:
class_name = path.split(os.sep)[1]
with open(path, 'r', encoding="utf8") as file:
text = file.read()[:100]
texts.append([text, class_name])
return textsWe back to CoHere class. We have to add two methods - to load examples and to classify input.
The first one is simple, co:here list of examples has to be created with the additional cohere's method - cohere.classify.Example.
def list_of_examples(self):
for e in examples():
self.examples.append(Example(text=e[0], label=e[1]))The second method is to classify the method from cohere. The method has serval arguments, such as:
model size of a model.
inputs list of data to classify.
examples list of a training set with examples
All of them you can find here.
In this tutorial, the cohere method will be implemented as a method of our CoHere class. An argument of this method is a list of descriptions to predict.
def classify(self, inputs):
return self.co.classify(
model='medium',
inputs=inputs,
examples=self.examples
).classificationsThe return is input, prediction of input, and a list of confidence. Confidence is a likelihood list of each class.
cohere.Classification {
input:
prediction:
confidence: []
}import cohere
from loadExamples import examples
from cohere.classify import Example
class CoHere:
def __init__(self, api_key):
self.co = cohere.Client(f'{api_key}', '2021-11-08')
self.examples = []
def list_of_examples(self):
for e in examples():
self.examples.append(Example(text=e[0], label=e[1]))
def classify(self, inputs):
return self.co.classify(
model='medium',
taskDescription='',
outputIndicator='',
inputs=inputs,
examples=self.examples
).classificationsTo create an application, in which will be a text input box and a likelihood display, we will use Stramlit. This is an easy and very useful library.
Installation
pip install streamlitWe will need two text inputs for co:here API key and for text to predict.
In docs of streamlit we can find methods:
st.header() to make a header on our app
st.test_input() to send a text request
st.button() to create button
st.write() to display the results of cohere model.
st.progress() to display a progrss bar
st.column() to split an app
st.header("Your personal text classifier - Co:here application")
api_key = st.text_input("API Key:", type="password") #text box for API key
description = [st.text_input("Description:")] #text box for text to predict
cohere = CoHere(api_key) #initialization CoHere
cohere.list_of_examples() #loading training set
if st.button("Classify"):
here = cohere.classify(description)[0] #prediction
col1, col2 = st.columns(2)
for no, con in enumerate(here.confidence): #display likelihood for each label
if no % 2 == 0: # in two columns
col1.write(f"{con.label}: {np.round(con.confidence*100, 2)}%")
col1.progress(con.confidence)
else:
col2.write(f"{con.label}: {np.round(con.confidence * 100, 2)}%")
col2.progress(con.confidence)To run the streamlit app use command
streamlit run name_of_your_file.pyThe created app looks like this
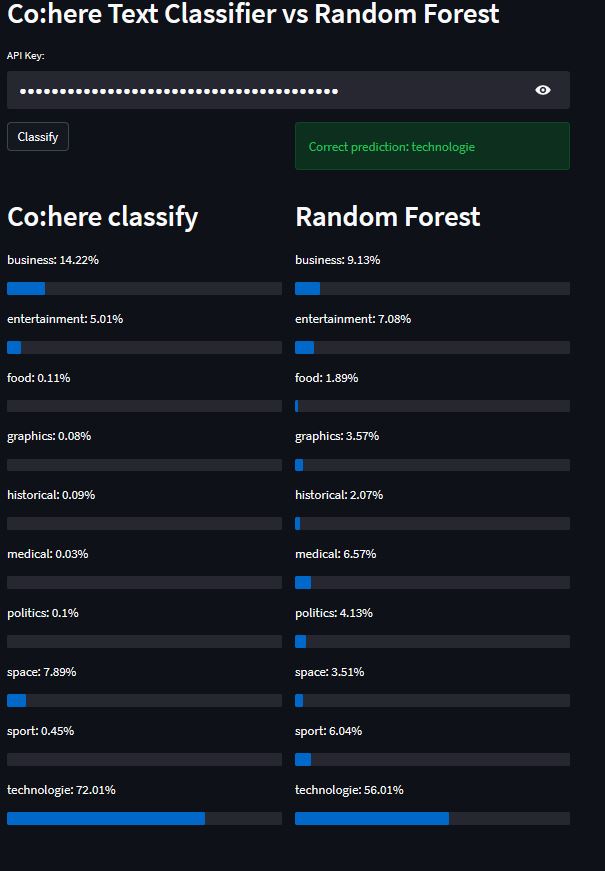
Co:here models can be used not only to generate the text but also for classification. In this tutorial, we were able to classify a short text, with a small dataset. There were 50 examples for 10 classes. This was enough to keep the likelihood of prediction at a high level. The big dataset in some scenarios can be hard to produce, so Co:here model can be a great solution for it.
Stay tuned for future tutorials!
Thank you! - Adrian Banachowicz, Data Science Intern in New Native