How to do CI/CD with Azure Databricks and get the initial Databricks token.
If you are automating your Databricks workspace creation in Azure you will probably run into an issue where you need a Databricks token to make REST calls to the Databricks API. The ARM template should ideally return to you an initial token, but it does not. You need to log into the Databricks Workspace UI and create a token, which disrupts your CI/CD pipeline. So, I created the below "workaround" which still involves a person, but keeps your pipeline automated.
- Create a Azure DevOps project
- Create a Resource group for a Key Vault and Azure Function
- Seed the KeyVault with a secret (e.g. DatabricksInitialToken = "EMPTY")
- Create an Azure Function that reads the secret (this will be a CI/CD gate which will pause our pipeline)
- In order to set the original very first Databricks token, a person must login to Databricks to generate a token and then set the value in Key Vault (we might be able to automate this with Selenium... but logging into Azure AD via a headless browser, can be tricky.)
- Create a release pipeline that creates Databricks, checks key vault for the Databricks token via a Gate, then interacts with the Databricks REST API
-
In Azure create a resource group named DatabricksInitialToken (I did East US).
If you do another region you need to update the CreateGroup.sh (the Databricks REST endpoint) -
In Azure create a key vault named DatabricksInitialToken in resource group DatabricksInitialToken
- Open key vault and select Secrets
- Click Generate/Import
- For name enter: DatabricksInitialToken
- For value enter: EMPTY (this needs to match the if..then test in the Azure Function)
-
In Azure create a function app (consumption model) named DatabricksInitialToken in resource group DatabricksInitialToken
- Select to code in Portal
- Select HTTP/Webhook
- Click on DatabricksInitialToken | Platform features
- Select Managed Service Identity
- Enable this
- Now go back to your Key Vault
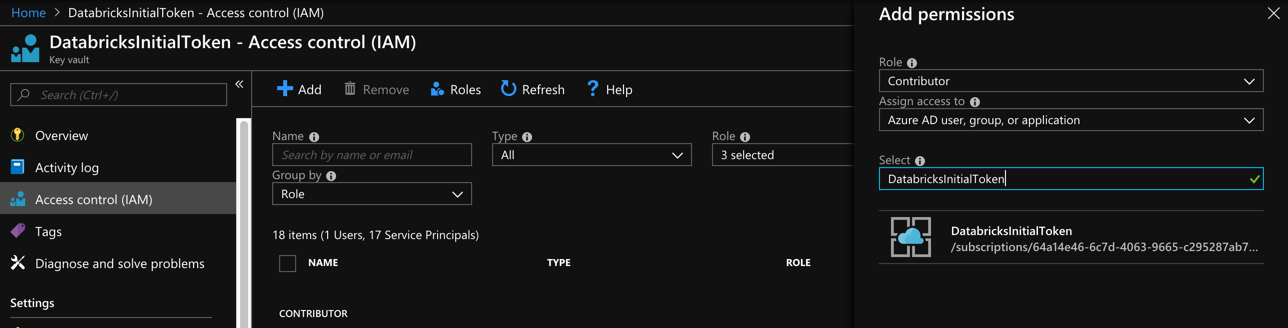
- Click on Access Control
- Click on Add
- Select Contributor (or lower)
- Enter DatabricksInitialToken for the name
- Select your Function App
- In your Key Vault
- Click on Access Policies
- Select Secret Management (or lower, we just need to read a secret)
- For Service Principle search for DatabricksInitialToken and select
- Click okay then save
- Go to your Azure Function and paste the AzureFunction.cs code into your function app (you might have to change some of the names)
-
Upload code to your VSTS repo (azuredeploy.json, azuredeploy.parameters.json, CreateGroup.sh)
-
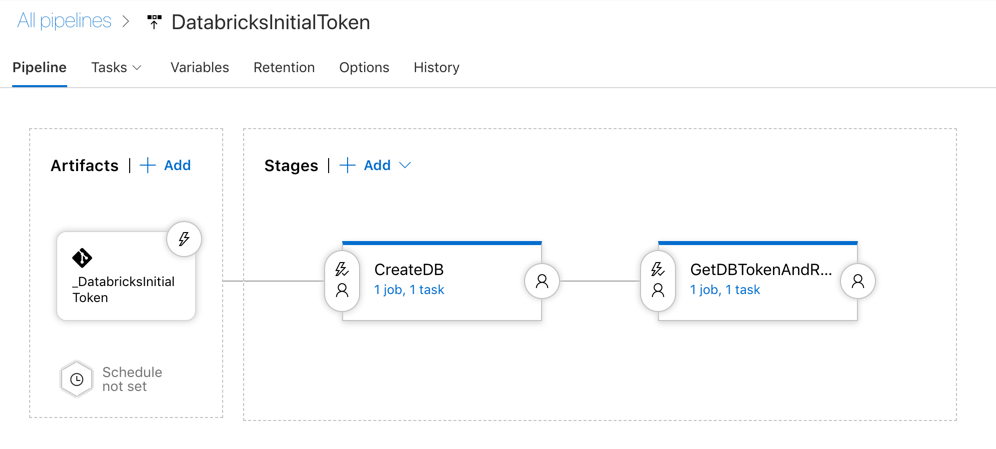
Create a release pipeline
- Tie to your VSTS Git repo (typically I do a build pipeline and publish artifacts, but we are "cheating" here)
- Create a Stage (empty job) named CreateDB
- Add the "Azure Resource Group Deployment" task
Get the ARM template for a Databricks workspace (also in this repo)
https://github.com/Azure/azure-quickstart-templates/tree/master/101-databricks-workspace
- Authorize your subscription (you might need to use a service principle under project | service connections)
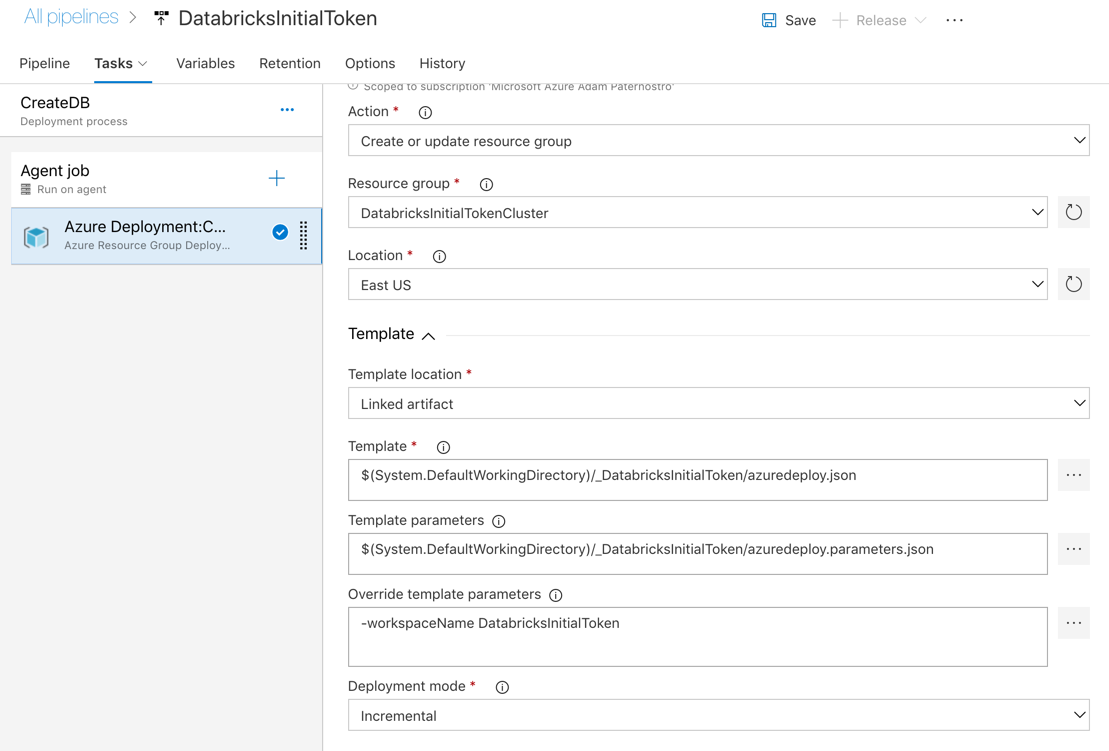
- For resource group name enter: DatabricksInitialTokenCluster (we do not want to deploy into our DatabricksInitialToken resource group, you could if you really wanted to, this is just keeping them seperate)
- Select East US for location
- Select the template file: azuredeploy.json
- Select the parameters file: azuredeploy.parameters.json
- In the "Override template parameters" entier: -workspaceName DatabricksInitialToken
- Save, Run and check (it should create a Databricks Azure Workspace!)
- Add a new Stage (empty job) named GetDGetDBTokenAndRunScriptBToken
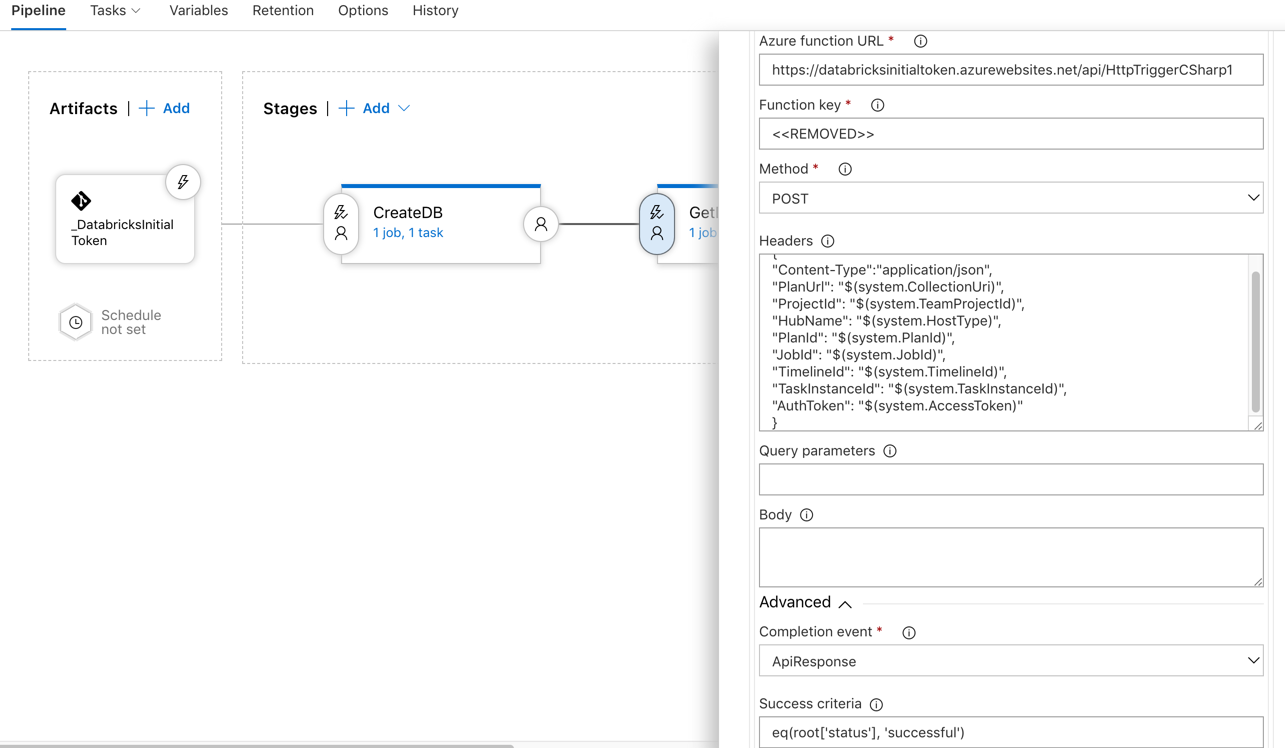
- Add a gate (click the little lightning bolt)
- Select your function app
- Get your function app URL and code (you get this at the top of your function app, you need to seperate the URL and the code)
- Under Advanced select API response
- For Success Criteria enter: eq(root['status'], 'successful')
- You can set your "The delay before evaluation" to 0 minutes
- You can set your Evaluation Options "The time between re-evaluation of gates" to 5 minutes
- Save, Run and check (it should fail since the key vault's secret is set to EMPTY)
- Open your Databricks workspace "MyClusterName"
- Click on user settings (top right user icon)
- Generate a new token
- Open your key vault DatabricksInitialToken
- Update the secret value of DatabricksInitialToken with the token just generated
- You can run your Azure Function and it should return successful
- Edit your pipeline
- Click on Variables
- Click on Variables groups
- Link your Key Vault to a variable group by clicking Manage Variable Groups
- Under your GetDGetDBTokenAndRunScriptBToken stage
- For Agent select Hosted Linux Agent
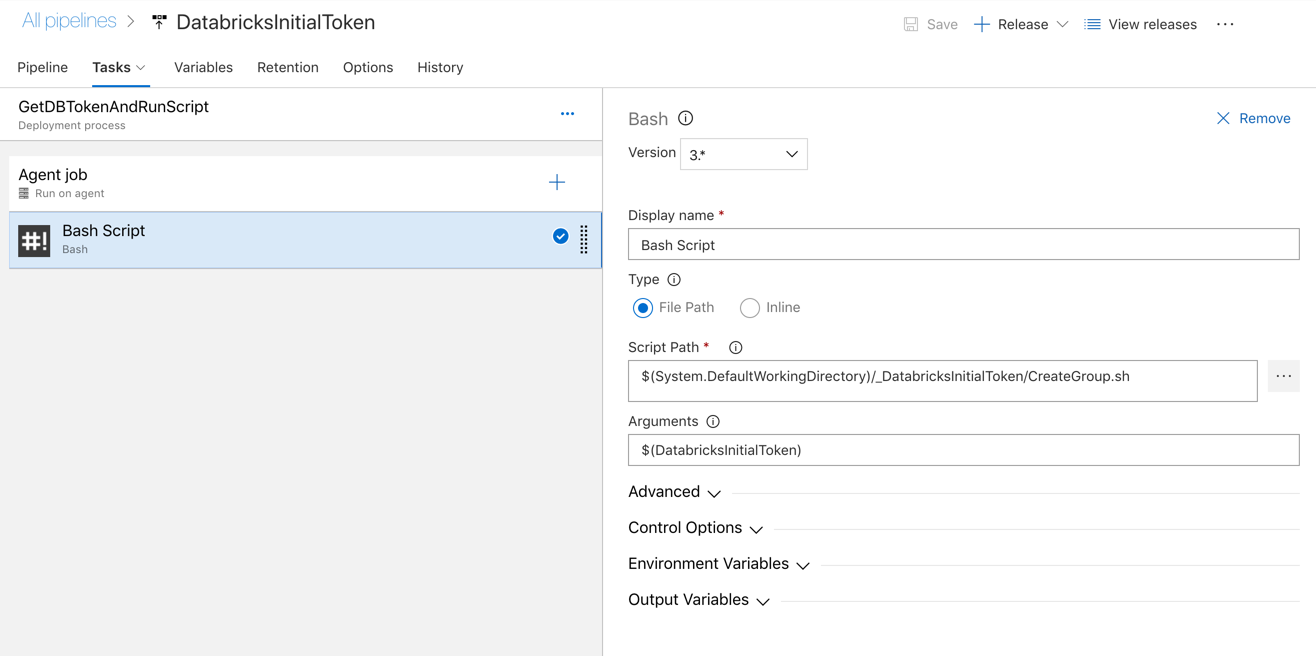
- Add a Bash Script task
- Select the script CreateGroup.sh
- NOTE: This can be any type of script at this point: deploy notebooks, JARs, etc...
- For parameters enter $(DatabricksInitialToken)
- NOTE: So one thing to note is that using Key Vault means the values are read in "realtime" and are not read at the beginning of the pipeline. Variables in VSTS are typically persevered with your pipleline, so if you re-execute a prior Release, the proceses uses the variables set at the time of the initial run.
- Save, Run and check (it should work)
- Run this command to check and delete the group created in Databricks
DatabricksToken=<<REPLACE TOKEN> curl -X GET https://eastus.azuredatabricks.net/api/2.0/groups/list \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $DatabricksToken" // We want to re-run the pipeline so delete the group curl -n \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $DatabricksToken" \ -X POST -d @- https://eastus.azuredatabricks.net/api/2.0/groups/delete <<JSON { "group_name": "VSTSGroup" } JSON - Go to your Key Vault and change the secret to EMPTY
- Run your pipeline
- The gate should fail (I set my gate retry interval to 5 minutes, so I have to wait 5 minutes)
- While waiting... go update your Key Vault and set the secret to your Databricks token
- The gate should pass on the next evaluation attempt
- The script should run and create the VSTS group (you can check if the group got created using the above curl script, if you not have curl installed go to shell.azure.com and use the Bash prompt)
- Run this command to check and delete the group created in Databricks
- Have the Azure Function read the secret name from the POST body so you can for many different workspaces
- See my script for rotating Databricks tokens and combine this method with the rotation technique! https://github.com/AdamPaternostro/Azure-Databricks-Token-Rotation