Retrieval-augmented generation is a technique used in natural language processing that combines the power of both retrieval-based models and generative models to enhance the quality and relevance of generated text.
Retrieval-augmented generation has 2 main componenets:
- Retrieval models: These models are designed to retrieve relevant information from a given set of documents or a knowledge base. (for further details check Information Retrieval Lecture from Stanford here)
- Generative models: Generative models, on the other hand, are designed to generate new content based on a given prompt or context.
Retrieval-augmented generation combines these two approaches to overcome their individual limitations. In this framework, a retrieval-based model is used to retrieve relevant information from a knowledge base or a set of documents based on a given query or context. The retrieved information is then used as input or additional context for the generative model. The generative model can leverage the accuracy and specificity of the retrieval-based model to produce more relevant and accurate text. It helps the generative model to stay grounded in the available knowledge and generate text that aligns with the retrieved information.
-
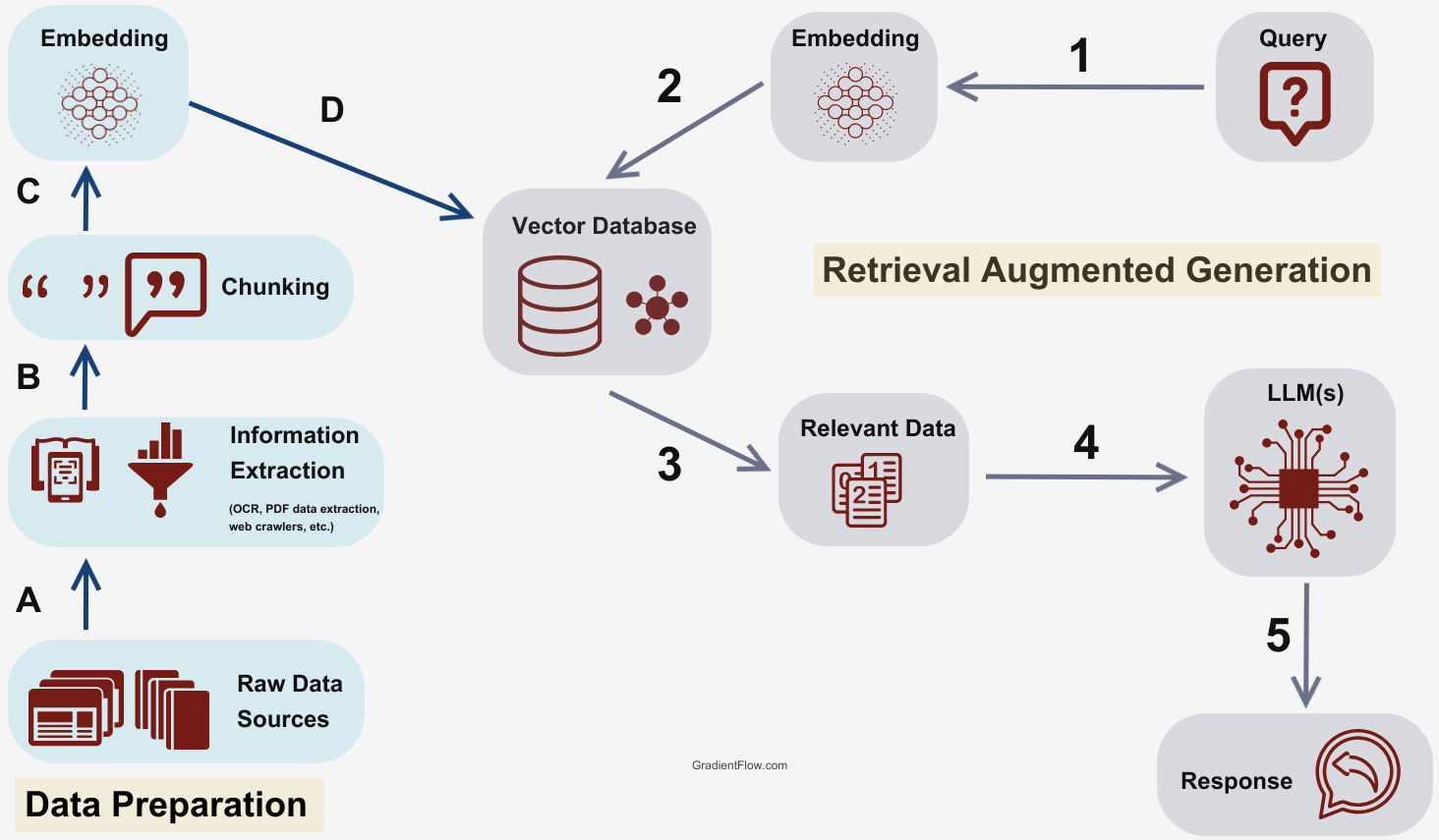
Data preparation:
- Source data: This data serves as the knowledge reservoir that the retrieval model scans through to find relevant information.
- Data chunking: Data is divided into manageable “chunks” or segments. This chunking process ensures that the system can efficiently scan through the data and enables quick retrieval of relevant content.
- Text-to-vector conversion (Embeddings): Converting the textual data into a format that the model can readily use. When using a vector database, this means transforming the text into mathematical vectors via a process known as “embedding.”
- Links between source data and embeddings: The link between the source data and embeddings is the linchpin of the RAG architecture. A well-orchestrated match between them ensures that the retrieval model fetches the most relevant information, which in turn informs the generative model to produce meaningful and accurate text.
-
Retrieval augmented generation
- User query: The user inputs a query asking for something.
- Embedding: convert the user query to embedding for better search.
- Search-index: Search for relevant context to the user query input in the index.
- Generation: Feed both user query input and retrieved context to LLM to generate an answer.
- Source data: This data serves as the knowledge reservoir that the retrieval model scans through to find relevant information.
- Data chunking: Data is divided into manageable “chunks” or segments. This chunking process ensures that the system can efficiently scan through the data and enables quick retrieval of relevant content.
- Text-to-vector conversion (Embeddings): Converting the textual data into a format that the model can readily use. When using a vector database, this means transforming the text into mathematical vectors via a process known as “embedding.”
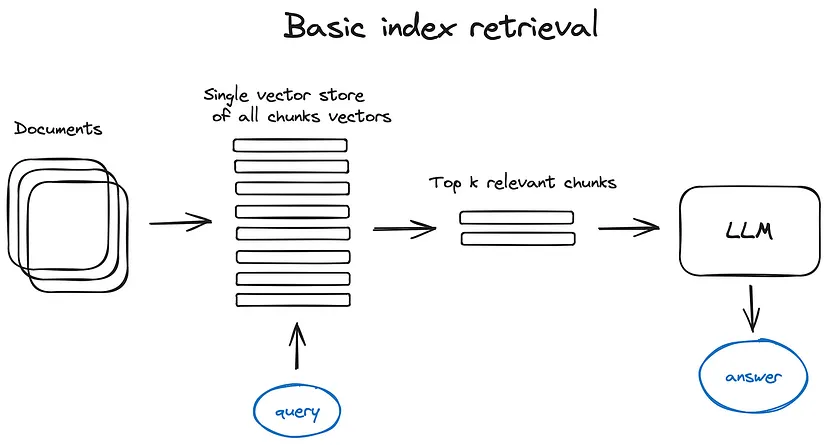
- Search-index:
- Vector store index: basic search index as explained before in basic RAG (You can use consine similarity)
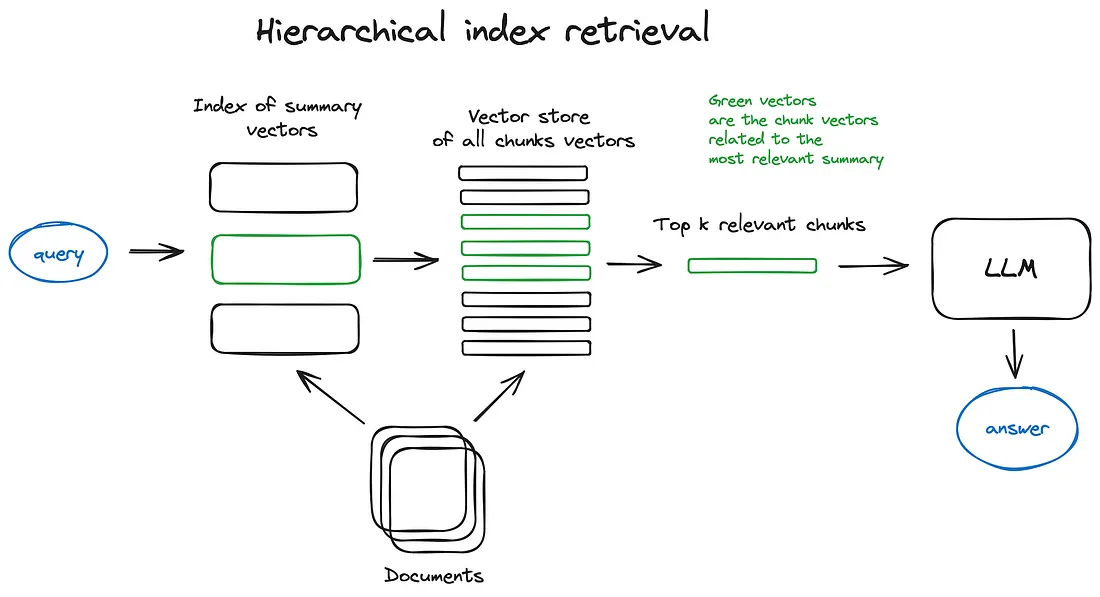
- Hierarchical indices: Create 2 indices one composed of summaries and the other one composed of document chunks, to search, first filter out the relevant docs bu summaries then searching inside this relevant group.
- Hypothetical Document Embeddings (HyDE): Basic search (vector store index) can lead to many irrelevant documents being fed to the LLM without being provided the right context for an answer. Solution is to use HyDE, use LLM to generate hypothetical answer, embed that answer, use this embedding to query the vector database. The hypothetical answer may be wrong, but it has more chance to be semantically similar to the right answer.
- Context enrichment: the idea is to use smaller chunks then add surrounding context for better search quality.
-
Sentence Window Retrieval: find the most relevant single sentence, then extend the context window by k sentences before and after, then send this extended context to LLM.

-
Auto-merging Retrieval: docs are split into smaller (child) chunks referring to larger (parent) chunks. First fetch smaller chunks during retrieval, if more than n chunks in top k retrieved chunks are linked to the same parent, we retrieve that larger (parent) node.

-
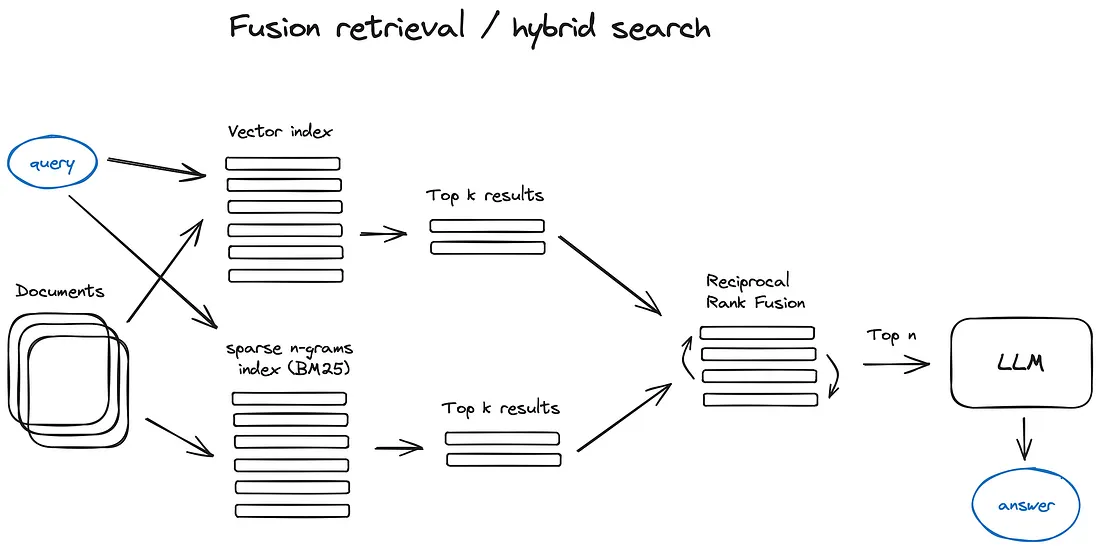
- Fusion retrieval or hybrid search: take the best out of both worlds sparse retrieval algorithms (e.g. BM25) & vector search and combine it in one result. Reciprocal Rank Fusion algorithm is also used to rerank the retrieved results for the final output.
- Vector store index: basic search index as explained before in basic RAG (You can use consine similarity)
- Reranking and Filtering: Once we have our retrieved results, now it is time to make some transformation (filtering, reranking, etc.). There is a variety of available Postprocessors (llama-index Postprocessors), that filter our results based on similarity score, keywords, metadata or reranking them with other models like an LLM.
- Query Transformations: modification to user input in order to improve retrieval quality.
- e.g. if the query is complex LLM can decompose it into sevral sub queries.
- Step-back prompting: uses LLM to general more query.
- Query re-writing: uses LLM to reformulate initial query in order to improve retrieval.
- e.g. if the query is complex LLM can decompose it into sevral sub queries.
- Chat Engine: if you are building chat engine you should consider dialogue context (memory of the previos prompts). One way to do though is query compression technique for example:
- Context Chat Engine: first retrieve context relevant to user's query, then send it along side with chat history from memory buffer (have a look on my repo langchain).
- Condense Plus Context Mode: the chat history and last message are condensed into a new query, then this query goes to the index and the retrieved context is passed to LLM with the original user prompt to generate an answer.