Udacity Data Engeneering Nanodegree Program - My Submission of Project: Data Pipelines
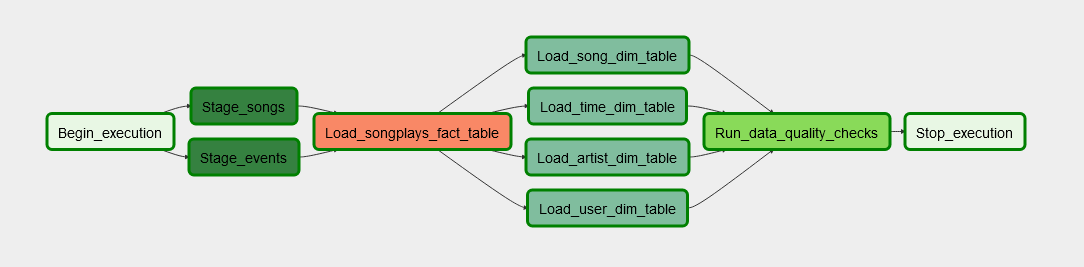
The goal of this project is to write an automated, scheduled ETL pipeline via Apache Airflow that transfers data from sets in Amazon S3 into Amazon Redshift, loads them into a star schema (1 fact and 4 dimenson tables) and eventually applies some data quality checks.
The raw data is in Amazon S3 and contains
- *song_data*.jsons ('artist_id', 'artist_latitude', 'artist_location', 'artist_longitude', 'artist_name', 'duration', 'num_songs', 'song_id', 'title', 'year') - a subset of real data from the Million Song Dataset.
- *log_data*.jsons ('artist', 'auth', 'firstName', 'gender', 'itemInSession', 'lastName', 'length', 'level', 'location', 'method', 'page', 'registration', 'sessionId', 'song', 'status', 'ts', 'userAgent', 'userId') - simulated activity logs from a music streaming app based on specified configurations.
Make sure you have an AWS secret and access key, a running Amazon Redshift Cluster in region us-west-2 and a running Airflow Webserver with the parameter dags_folder in /home/user_name/AirflowHome/airflow.cfg pointing to this repo's code.
In the Airflow Webserver GUI go to Admin -> Connections and create:
A connection to AWS
- Conn Id: Enter
aws_credentials. - Conn Type: Enter
Amazon Web Services. - Login: Enter your Access key ID from the IAM User credentials.
- Password: Enter your Secret access key from the IAM User credentials.
A connection to Redshift
- Conn Id: Enter
redshift. - Conn Type: Enter
Postgres. - Host: Enter the endpoint of your Redshift cluster, excluding the port at the end. You can find this by selecting your cluster in the Clusters page of the Amazon Redshift console. See where this is located in the screenshot below. IMPORTANT: Make sure to NOT include the port at the end of the Redshift endpoint string.
- Schema: Enter
dev. This is the Redshift database you want to connect to. - Login: Enter the user name you created when launching your Redshift cluster.
- Password: Enter the password you created when launching your Redshift cluster.
- Port: Enter
5439.
Trigger the DAGs create_tables to create all tables and trigger the DAGs delete_tables to delete them.
Trigger the DAG sparkify_data_pipeline import the raw sets from Udacity's S3 above and store data in the following star schema:
- songplays (songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent) - records in log data associated with song plays
- users (user_id, first_name, last_name, gender, level) - users in the app
- songs (song_id, title, artist_id, year, duration) - songs in music database
- artists (artist_id, name, location, latitude, longitude) - artists in music database
- time (start_time, hour, day, week, month, year, weekday) - timestamps of records in songplays broken down into specific units
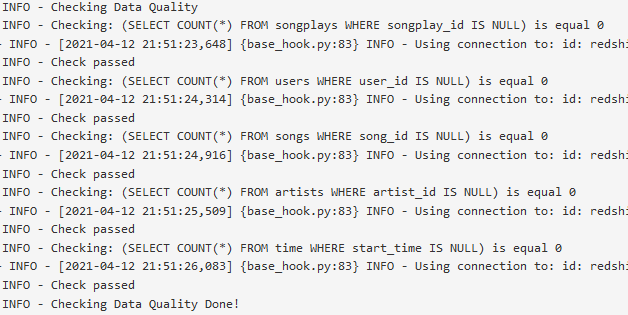
Five checks are applied to optionally tables of the star schema:
- Checking if songplay_id is unique in songplays
- Checking if user_id is unique in users
- Checking if song_id is unique in songs
- Checking if artist_id is unique in artists
- Checking if start_time is unique in time
As ignore_fails=False is set, the task und consequently the DAG would fail, if any of the checks fails.
The output is given in the logs of the DAGs task Run_data_quality_checks: