Released on June 16, 2020
By utilizing an existing privacy breaking algorithm which inverts gradients of models to reconstruct the input data, the data reconstructed from inverting gradients algorithm reveals the vulnerabilities of models in representation learning.
In this work, we utilize the inverting gradients algorithm proposed in Inverting Gradients - How easy is it to break Privacy in Federated Learning? to reconstruct the data that could lead to possible threats in classification task. By stacking one wrongly predicted image into different batch sizes, then use the stacked images as input of the existing gradients inverting algorithm will result in reconstruction of distorted images that can be correctly predicted by the attacked model.

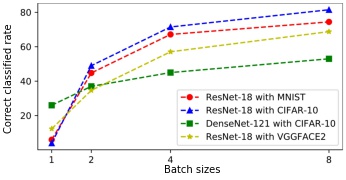
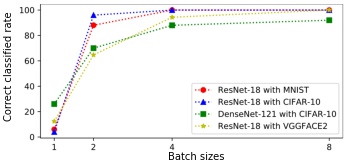
Required libraries:
Python>=3.7
pytorch=1.5.0
torchvision=0.6.0python main.py --model "resnet18" --data "cifar10" stack_size 4 -ls 1001,770,123 --save True --gpu TrueImplementation for ResNet-18 trained with CIFAR10 can be found HERE and with VGGFACE2 can be found HERE
You can download pretrained model from HERE then replace the torchvision models.
- Inverting Gradients - How easy is it to break Privacy in Federated Learning?
- Deep Leakage From Gradients
- PyTorch models trained on CIFAR-10 dataset
If you find this work useful for your research, please cite
@inproceedings{Gleakage,
title={From Gradient Leakage To Adversarial Attacks In Federated Learning},
author={Lim, Jia Qi and Chan, Chee Seng},
booktitle={2021 IEEE International Conference on Image Processing (ICIP)},
year={2021},
}
Suggestions and opinions on this work (both positive and negative) are greatly welcomed. Please contact the authors by sending an email to
jiaqi0602 at gmail.com or cs.chan at um.edu.my.
The project is open source under BSD-3 license (see the LICENSE file).
©2021 Universiti Malaya.