Building a full Visual SLAM pipeline to experiment with different techniques. The repository also includes a ROS2 interface to load the data from KITTI odometry dataset into ROS2 topics to facilitate visualisation and integration with other ROS2 packages.
This video shows the ROS2 KITTI data handling node in work with its different depth densification methods.
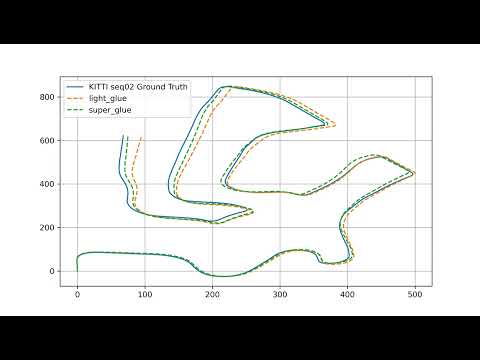
This video shows visual odometry running on sequence 2 from KITTI odometry dataset. It compares using LightGlue and SuperGlue as feature matchers. Both are using SuperPoint as a feature extractor and descriptor and depth images created (and densified) from lidar readings.
Odomtery is obtained with PnP. You can see slight drifts the more the sequence goes, but it's worth mentioning that ABSOLUTELY no corrections or loop clousres are used!
This video shows a comparison between different feature extractors and feature matchers running running on the same dataset.

git clone https://github.com/MarkNaeem/VSLAM-playground.gitcd VSLAM-payground/python3 -m pip install -e .git submodule initgit submodule update- You can directly build the ROS2 package inside the given workspace and source it, or copy the node to your own workspace.
- To build in the given ros2_ws folder, run
colcon build --symlink-installinside the ros2_ws folder, thensource install/setup.bash.
Notes:
- Make sure to modify
definitions.pyin vslam to point at your KITTI dataset folder. - Don't forget to go into LightGlue folder and run the install command there
python3 -m pip install -e . - Make sure to modify the path to your KITTI dataset folder in
init.launch.py.
The ROS2 node (for now) is only to read and load the KITTI data on ROS2 topics efficiently.
Installation is as described above. I started testing the node with a Python script, but the performance was a bit poor. The C++ node is a lot more optimised and much faster.
You can run the node via the launch file, which will load the parameters and run an rviz2 node.ros2 launch vslam-playground-ros init.launch.py
Or run the (C++ or Python) nodes onlyros2 run vslam-playground-ros [ data_publisher (C++) | data_publisher.py (Python) ]
The following table describes the parameters used in the C++ kitti_data_publisher node of vslam-playground-ros.
| Parameter Name | Type | Description | Default Value |
|---|---|---|---|
base_directory |
String | The base directory where the dataset is stored. | |
sequence_number |
String | The sequence number of the dataset being processed. | "00" |
start_point |
Integer | The starting point index in the dataset for processing. | 0 |
publish_rate |
Float | The rate at which the data is published (in Hz). | 10.0 |
max_size |
Integer | The maximum number of elements in the internal maps for images, depth, and point clouds. | 100 |
num_image_loader_threads |
Integer | The number of threads allocated for loading images. | 1 |
num_depth_loader_threads |
Integer | The number of threads allocated for loading depth information. | 3 |
depth_densification_method |
String | Method used for densifying the depth information. (radius, flann, inpaint [ns, telea]) | 'radius' |
densification_radius |
Integer | The radius used in the depth densification process. (used in radius and inpaint methods) | 5 |
publish_test_pcl |
Boolean | Flag to determine whether a point cloud after densification should be published. | True |
- Implement densification functions in CUDA.
- Include bilinear and cubic interpolation in depth densification.
- Introduce right camera images and camera_info from the dataset.
- Add depth alignment with the right camera.
- Parameterize Configuration: Use ROS 2 parameters for configuring of file paths, data tracks, publishing frequencies, and thread counts.
- Optimize Queue Processing: Use condition variables to efficiently manage worker thread wake-up for processing new data entries in queues.
- Add a start point to allow starting from anywhere within the given sequence.
- Improve Error Handling: Implement robust error handling throughout the node, particularly where utility functions are called that may throw exceptions.
- Parametrise init.launch.py parameters (so we don't have to modify the file to change them).