Lightweight demo using the Anthropic Python SDK to experiment with Claude's Search and Retrieval capabilities over a variety of knowledge bases (Elasticsearch, vector databases, web search, and Wikipedia). In this demo, we explore an alternative to tradional retrieval-augmented generation (RAG) techniques.
The repository contains the following directories:
| Directory | Description |
|---|---|
| claude_retriever | Contains the core search and retrieval logic using Claude's API. |
| examples | Provides example notebooks and scripts showing how to use claude_retriever with various search tools. |
| tests | Includes unit and integration tests for the embedders, utils, and search tools. |
This retrieval demo uses Python 3.10. Install it if you don't already have it.
Clone the repository:
git clone https://github.com/anthropic/claude-retriever-demo.git
Navigate into the demo directory:
cd claude-retriever-demo
It's recommended to use a virtual environment. Create and activate one:
python3 -m venv venv
source venv/bin/activate
Install the demo:
pip install -e .
For conda or other virtual environment managers, once you've cloned the repo, create a new environment:
conda create --name retrieval
conda activate retrieval
Install requirements:
conda install pip
pip install -r requirements.txt
You'll need to add some environment variables, at minimum:
| Environment Variable | Description |
|---|---|
| ANTHROPIC_API_KEY | API key for Anthropic's Claude. You can apply for an API key here. |
Once set, refer to the example notebooks in /examples to start testing retrieval workflows.
At a high level, the Retrieval Demo works as follows:
- Set up a
SearchToolobject that can take natural queries and return formatted search results. - Initialize a
ClientWithRetrievalobject, which inherits from theClientobject in the base Anthropic SDK. It accepts aSearchToolobject. - Perform retrieval via the
completion_with_retrievalmethod which is similar the basecompletionmethod, but Claude will issue queries and use the SearchTool to better solve the task given to it. This is the quickest way to experiment with retrieval.
We also offer two methods that are used within completion_with_retrieval that can also be used standalone:
retrieve: Theretrievemethod allows you to make a single call to get Claude to gather relevant information for a given question task. This provides greater steerability of the RAG pipeline by allowing for you to use the search results downstream and apply additional post-processing.answer_with_results: Theanswer_with_resultsmethod performs the traditional retrieval-augmented generation step and uses Claude to provide an answer to a query given search results as context.
This method comprises the traditional synthesis step in most RAG pipelines today. Here we provide Claude the search results and ask it to synthesize an answer to the user's question.
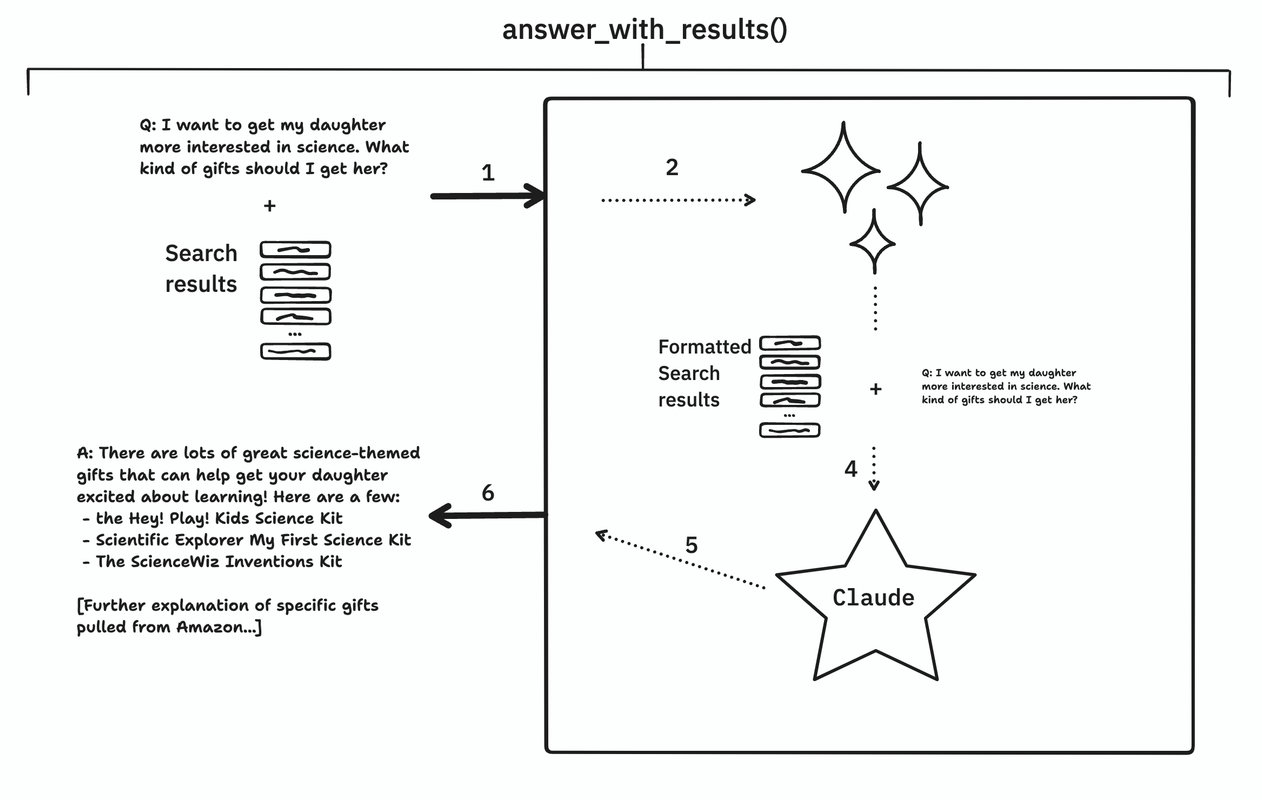
- The user's question and the search results are passed into the method.
- If the
format_search_resultsparameter is set toTruethen we reformat the search results into the format that Claude has been finetuned to expect. - The formatted search results plus the original question are passed to Claude to generate a completion.
- Claude reads over the search results to extract relevant information and synthesizes an answer to the user's question.
- The Claude-generated answer is returned.
To integrate Claude into your traditional RAG pipeline, you can call the answer_with_results() method by itself. Set the format_search_results parameter to True and pass in a list of your raw search results (in the form of a list[str]) to the method.
The traditional RAG pipeline only uses LLMs for answering after search results are gathered from the knowledge base. The retrieve() method leverages Claude's capabilities earlier in the process.
retrieve() allows Claude to iteratively search the knowledge base to gather relevant information until it decides enough has been collected to answer the question. Through this approach, we use Claude to assist in gathering more relevant information than would be possible if we only relied on the inital user question as the search query.
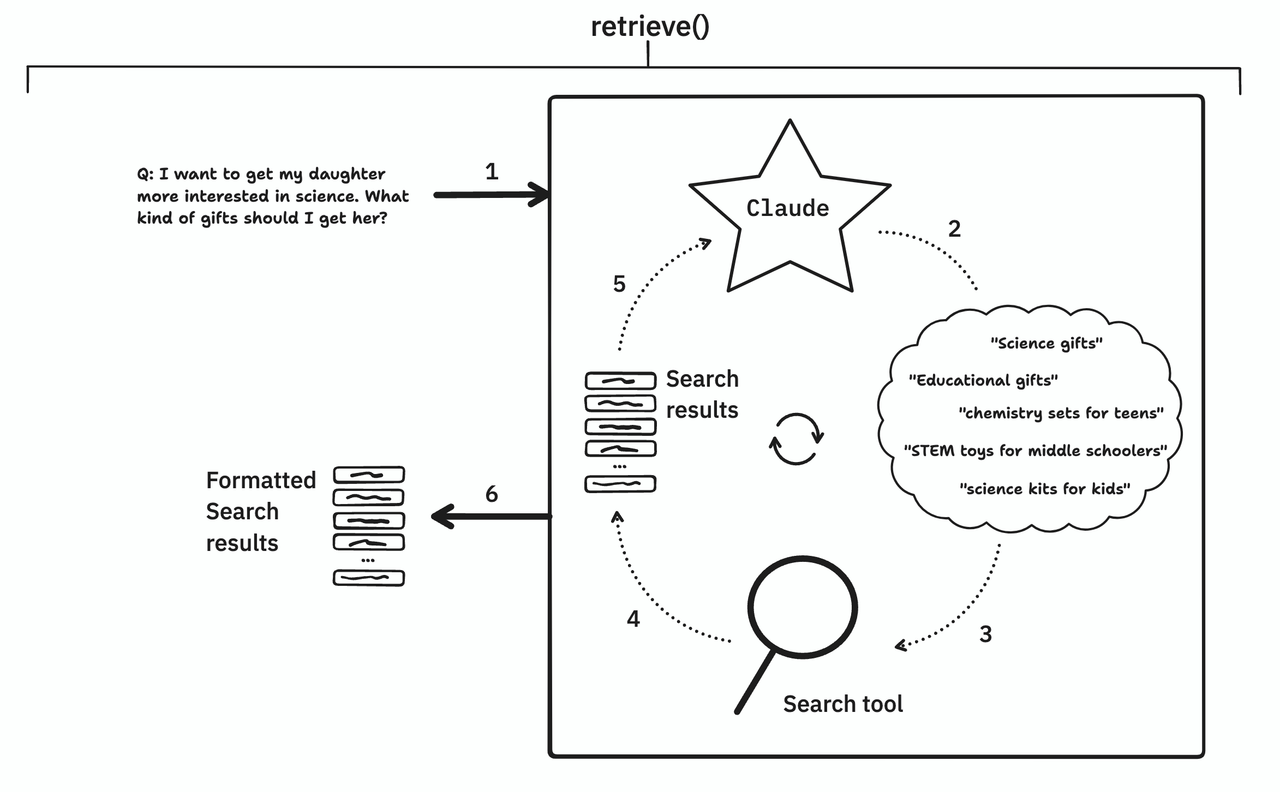
Here is the flow:
- The original query is passed to Claude.
- Claude generates natural language search queries based on the original query.
- The searches are passed to the search tool. Documents are returned.
- Claude receives the search results.
- Claude evaluates if enough information has been gathered.
- Claude continues searching up to
max_searches_to_try. - Once done, the final set of search results are cleaned (deduplicated, formatted) and returned.
It's important to note that retrieve() returns the search results rather than a final answer. This allows you to do further processing on the results downstream. The modular nature provides more control over the search process.
A search tool takes natural language queries and returns results relevant to the queries from an information source.
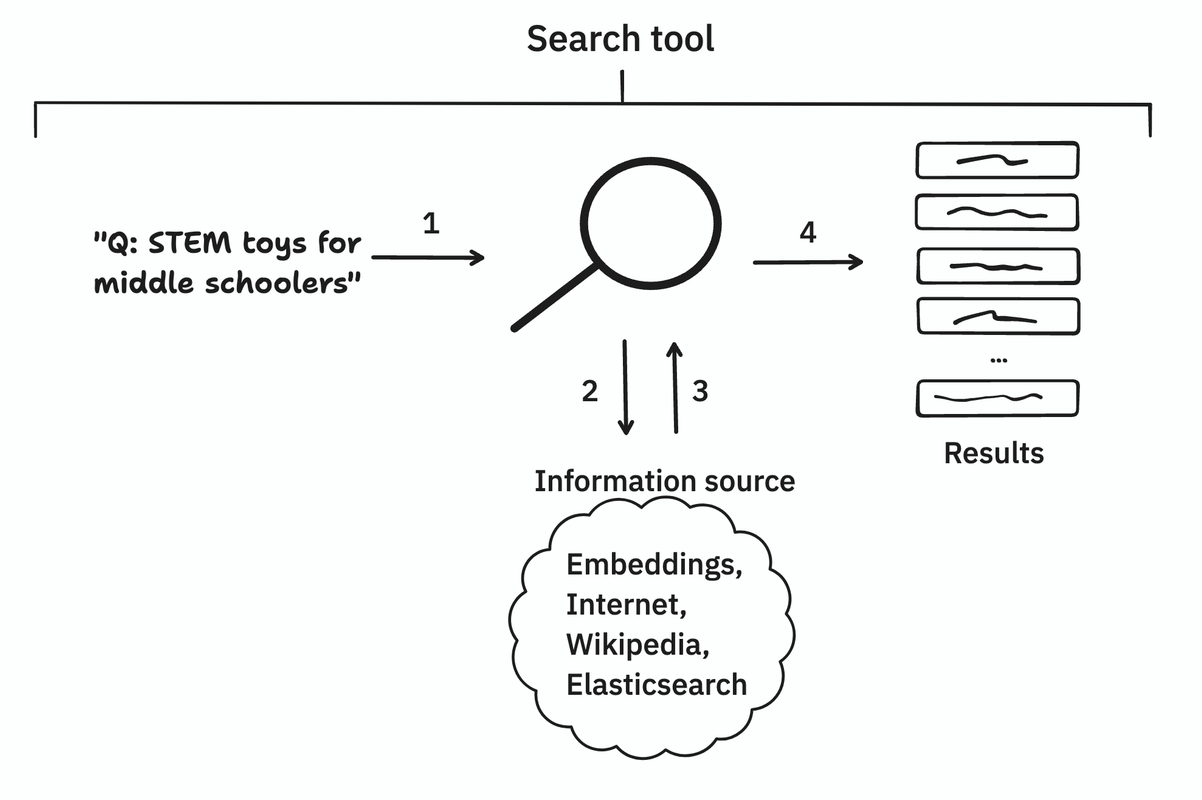
The demo contains examples of common search tools:
- Web search (via Brave, augmenting Claude with up-to-date info from the web)
- Wikipedia search (augmenting Claude with a full knowledge base)
- Embedding search (via Pinecone or local, augmenting Claude with chunks of any dataset)
- Enterprise search (via ElasticSearch, augmenting Claude with full documents of any dataset)
It is straightforward to add new SearchTools to the demo as well by creating a new Python file for the tool in the /searcher/searchtools/ folder.
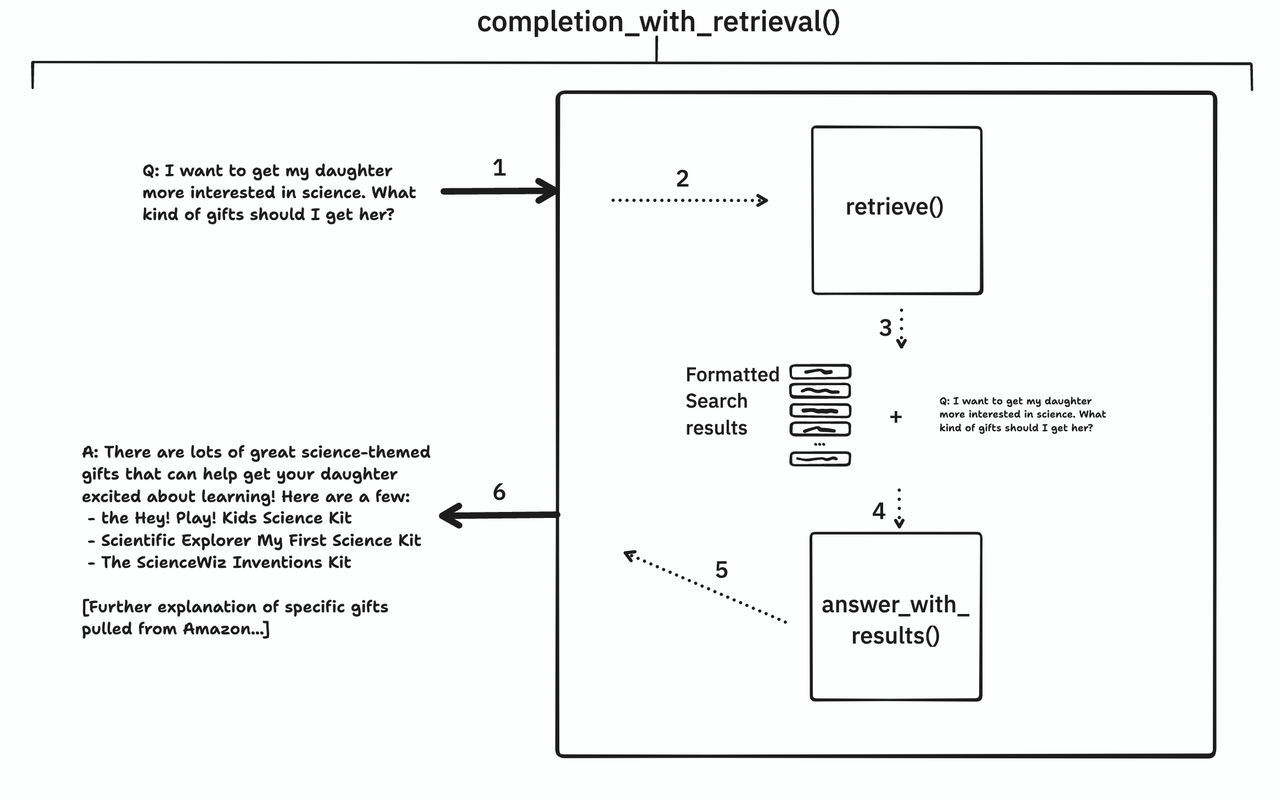
ClientWithRetrieval method completion_with_retrieval() combines the retrieve and answer_with_results methods. It works through the following steps:
- The user's original question is passed to Claude as the query.
- The
retrievemethod is called and Claude begins to gather the relevant search results. retrievereturns the relevant search results.- The search results plus the user's original question are passed to the
answer_with_resultsmethod. answer_with_resultsuses the information within the search results to answer the question.- The final answer is returned to the user.
Let’s take a look at what Claude’s actual responses and outputs look like when using the Retrieval Demo using the example from the previous section.
Say we execute this method:
client = ClientWithRetrieval(api_key=os.environ['ANTHROPIC_API_KEY'], search_tool=amazon_products_search_tool)
augmented_response = client.completion_with_retrieval(
query="I want to get my daughter more interested in science. What kind of gifts should I get her?",
model=ANTHROPIC_MODEL,
n_search_results_to_use=3,
max_searches_to_try=5,
max_tokens_to_sample=1000)
The query is appended to a template that instructs Claude about the search task and the available search tool. Claude reads this prompt and understands it should perform searches.
Claude formulates an initial search query and outputs:
<search_query>science gifts</search_query>
The demo code running on the client extracts the search term "science gifts" and calls the linked search tool. The tool returns results which are added between <search_results> tags:
<search_results>
<item index="1">
<page_content>
Product Name: LeapFrog Dino's Delightful Day Alphabet Book, Green
About Product: Letters and words are woven into the story in alphabetical order with phonetic sounds to introduce ABCs to your little one through a charming tale | Flip through the 16 interactive pages to hear the story read aloud, or enjoy musical play by jamming to a melody with fun sounds and musical notes | Press the light-up button to hear letter names, letter sounds and words from the story | Number buttons along Dino's back introduce counting and recognizing numbers from one to ten | This complete story with beginning, middle and end exposes your child to early reading skills. 2AA batteries are included for demo purposes, replace new batteries for regular use. Product dimensions: 12.3" Wide x 12.5" Height x 2.7" Depth
Categories: Toys & Games | Learning & Education | Science Kits & Toys
</page_content>
</item>
<item index="2">
<page_content>
Product Name: Tiger Tribe Dinosaurs Colouring Set
About Product: Small book, big fun; explore the Prehistoric world of dinosaurs as you use the 10 vibrantly colored markers to color in and design your favorite dynos | Beautifully illustrated coloring set Jam packed with markers, stickers, and coloring pages, all in a perfectly portable package | Contains a 48-page coloring book, 10 high quality markers, 5 sticker sheets and two special storage drawers to stash your stuff | Cleverly designed book-like box has compartments to keep everything neat and organized; innovative magnet closure keeps it all together | For boys and girls ages 3+
Categories: Toys & Games | Arts & Crafts
</page_content>
</item>
</search_results>
This is appended to the original prompt and Claude's <search_query> output. The process repeats until max_searches_to_try is reached. Finally, Claude uses the provided <search_results> to generate a final answer.
Examples of all the search integrations are in this Colab.
You can see this example in the examples/ folder here.
We have pre-defined a WikipediaSearchTool to show how to augment Claude with all the knowledge of Wikipedia:
from claude_retriever.searcher.searchers import WikipediaSearchTool
wikipedia_search_tool = WikipediaSearchTool()
client = claude_retriever.ClientWithRetrieval(api_key=os.environ['ANTHROPIC_API_KEY'],
search_tool = wikipedia_search_tool)
query = "Do NBA players typically get the recommended amount of sleep for adults?"
# get the search results that can be use to answer a query:
search_results = client.retrieve(
query=query,
stop_sequences=[anthropic.HUMAN_PROMPT, "END_OF_SEARCH"],
model="claude-2.0",
n_search_results_to_use=1, # Use only the top search result, so Claude can adapt queries quickly
max_searches_to_try=3, # Reducing this number will make the search process faster, but less likely to get the best results
max_tokens_to_sample=1000)
# or get Claude's answer informed by the search results:
answer = client.completion_with_retrieval(
prompt=prompt,
model="claude-2.0",
n_search_results_to_use=1, # Get a single result each time so Claude can quickly adapt its searches
max_searches_to_try=3, # Increasing this number allows Claude to run more searches as it looks for information
max_tokens_to_sample=1000)You can see this example in the examples/ folder here using local vectorstores. You can see this example in the examples/ folder here using remote vectorstores.
A common external knowledge base is a set of documents. In this example, we will chunk and embed local documents and save them to a (local) vectorstore, then retrieve from that vectorstore when answering queries.
# Create a vector store and populate it with documents
from claude_retriever.searcher.vectorstores.local import LocalVectorStore
from claude_retriever.utils import embed_and_upload
input_file = "documents_to_embed.jsonl" # Each line of this file should be a JSON object with a "text" field
disk_path = "local_vector_store.jsonl" # The vector store will be saved to this file
vector_store = LocalVectorStore(disk_path=disk_path)
embed_and_upload(input_file, vector_store, tokens_per_chunk=384, batch_size=128)
# Create a search tool for the vector store
from claude_retriever.searcher.searchers import EmbeddingSearchTool
tool_description='The search engine will search over the Test database, and return for each product its title, description, and a set of tags.' # This provides instructions to Claude on how to use the search tool
search_tool = EmbeddingSearchTool(
tool_description=tool_description,
vector_store=vector_store
)client = claude_retriever.ClientWithRetrieval(api_key=os.environ['ANTHROPIC_API_KEY'],
search_tool = search_tool)
query = "I want to get my daughter more interested in science. What kind of gifts should I get her?"
# get the search results that can be use to answer a query:
search_results = client.retrieve(
query=query,
stop_sequences=[anthropic.HUMAN_PROMPT, "END_OF_SEARCH"],
model="claude-2.0",
n_search_results_to_use=1, # Use only the top search result, so Claude can adapt queries quickly
max_searches_to_try=3, # Reducing this number will make the search process faster, but less likely to get the best results
max_tokens_to_sample=1000)
# or get Claude's answer informed by the search results:
answer = client.completion_with_retrieval(
query=query,
model="claude-2.0",
n_search_results_to_use=1, # Get a single result each time so Claude can quickly adapt its searches
max_searches_to_try=3, # Increasing this number allows Claude to run more searches as it looks for information
max_tokens_to_sample=1000)You can see this example in the examples/ folder here.
Through Retrieval, Claude can now access the internet by using the BraveSearchTool. All you need to do is provide a Brave API key (you can register an account here). Here's an example of using the BraveSearchTool:
from claude_retriever.searcher.searchtools.websearch import BraveSearchTool
# Create a searcher
brave_search_tool = BraveSearchTool(brave_api_key=os.environ["BRAVE_API_KEY"], summarize_with_claude=True, anthropic_api_key=os.environ["ANTHROPIC_API_KEY"])
client = claude_retriever.ClientWithRetrieval(api_key=os.environ['ANTHROPIC_API_KEY'],
search_tool = search_tool)
query = "I want to get my daughter more interested in science. What kind of gifts should I get her?"
# get the search results that can be use to answer a query:
search_results = client.retrieve(
query=query,
stop_sequences=[anthropic.HUMAN_PROMPT, "END_OF_SEARCH"],
model="claude-2.0",
n_search_results_to_use=1, # Use only the top search result, so Claude can adapt queries quickly
max_searches_to_try=3, # Reducing this number will make the search process faster, but less likely to get the best results
max_tokens_to_sample=1000)
# or get Claude's answer informed by the search results:
answer = client.completion_with_retrieval(
query=query,
model="claude-2.0",
n_search_results_to_use=1, # Get a single result each time so Claude can quickly adapt its searches
max_searches_to_try=3, # Increasing this number allows Claude to run more searches as it looks for information
max_tokens_to_sample=1000)You can see this example in the examples/ folder here using local vectorstores.
Retrieval with Claude supports Elasticsearch as well through the ElasticsearchCloudSearchTool. Here's an example of using a search tool created for an index that contains data of a list of Amazon products:
from claude_retriever.searcher.searchtools.elasticsearch import ElasticsearchCloudSearchTool
AMAZON_SEARCH_TOOL_DESCRIPTION = 'The search engine will search over the Amazon Product database, and return for each product its title, description, and a set of tags.'
amazon_search_tool = ElasticsearchCloudSearchTool(tool_description=AMAZON_SEARCH_TOOL_DESCRIPTION,
elasticsearch_cloud_id=cloud_id,
elasticsearch_api_key_id=api_key_id,
elasticsearch_api_key=api_key,
elasticsearch_index=index_name)
client = claude_retriever.ClientWithRetrieval(api_key=os.environ['ANTHROPIC_API_KEY'],
search_tool = search_tool)
query = "I want to get my daughter more interested in science. What kind of gifts should I get her?"
# get the search results that can be use to answer a query:
search_results = client.retrieve(
query=query,
stop_sequences=[anthropic.HUMAN_PROMPT, "END_OF_SEARCH"],
model="claude-2.0",
n_search_results_to_use=1, # Use only the top search result, so Claude can adapt queries quickly
max_searches_to_try=3, # Reducing this number will make the search process faster, but less likely to get the best results
max_tokens_to_sample=1000)
# or get Claude's answer informed by the search results:
answer = client.completion_with_retrieval(
query=query,
model="claude-2.0",
n_search_results_to_use=1, # Get a single result each time so Claude can quickly adapt its searches
max_searches_to_try=3, # Increasing this number allows Claude to run more searches as it looks for information
max_tokens_to_sample=1000)See also the Retrieval explainer doc for a guide on how to set up your Elasticsearch API key and upload your documents to Elasticsearch.