This is the official implementation for the NeurIPS paper:
Lingjiao Chen, Matei Zaharia, James Zou, FrugalML: How to Use ML Prediction APIs More Accurately and Cheaply.
This ReadMe briefly explains what FrugalML is and how to install it. Besides using FrugalML for all provided datasets, it also shows how to use and evaluate FrugalML for new datasets.
Prediction APIs offered for a fee are a fast-growing industry and an important part of machine learning as a service. While many such services are available, the heterogeneity in their price and performance makes it challenging for users to decide which API or combination of APIs to use for their own data and budget.
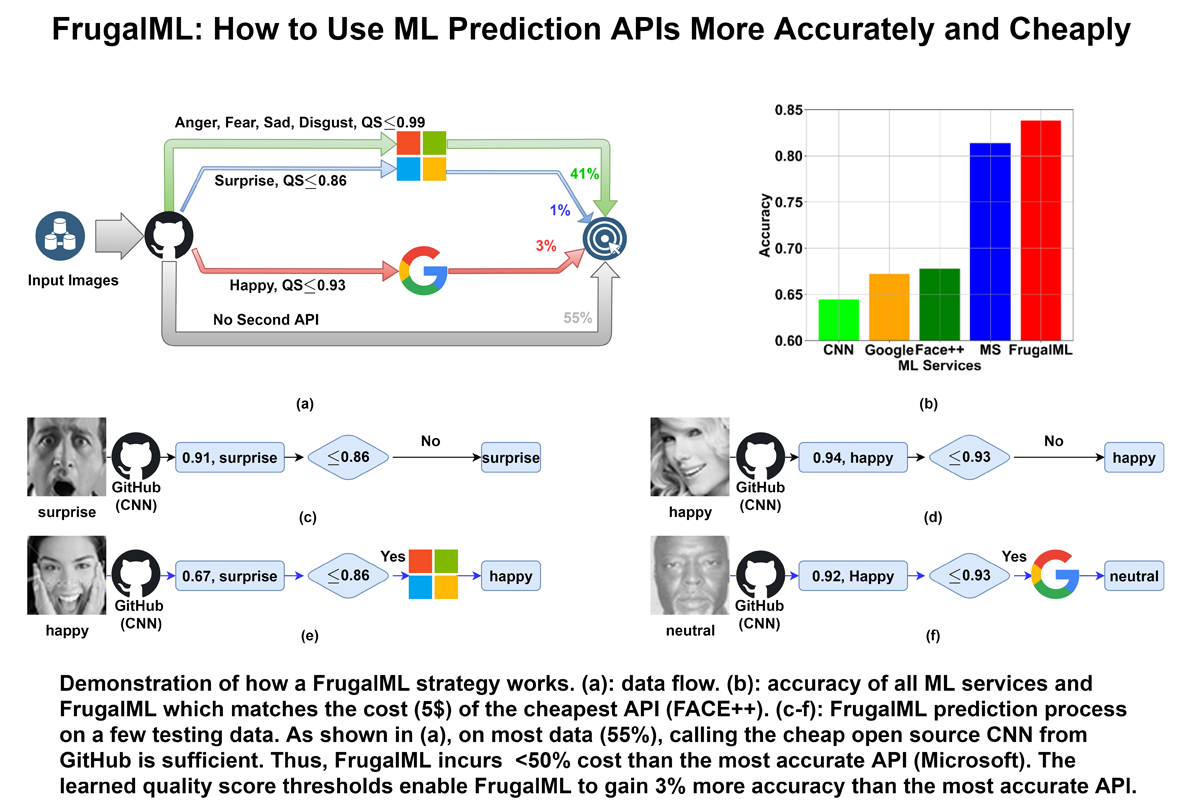
FrugalML is a principled framework towards addressing the above challenge. It jointly learns the strength and weakness of each API on different data, and performs a provably efficient optimization to automatically identify the best sequential strategy to adaptively use the available APIs within a budget constraint. Using real world APIs from Google, Microsoft, Amazon, IBM, Baidu and other providers for various tasks and datasets, FrugalML can achieve up to 90% cost reduction while matching the accuracy of the best single API, or up to 5% better accuracy while matching the best API's cost.
This code was tested with python3.8. To install FrugalML, simply clone the repository:
git clone https://github.com/lchen001/FrugalML
and then execute
pip3 install -r requirements.txt
There are two main ways to use FrugalML. The first is to obtain one strategy given a budget. The second is to evaluate FrugalML's accuracy and budget trade-offs.
The details are as follows.
(All the following code need be executed under the src folder.)
Execute
python3 optimizer_test.py --method=FrugalML --datapath=../dataset/mlserviceperformance_RAFDB --budget=5
Here, method can be FrugalML, FrugalMLQSonly, or FrugalMLFixBase, where the later two are simplified version of FrugalML. datapath specifies the directory holding the dataset. budget can be any possitive number larger than the cheapest API's cost.
Execute
python3 optimizer_evaluate.py --task=fer --dataname=RAFDB --datapath=../dataset/mlserviceperformance_RAFDB --train_ratio=0.5 --baseid=100
Here, task can be fer (for facial emotion recognition), sa (sentiment analysis), or s2t (speech to text). datapath specifies the directory holding the dataset. train_ratio specifies the ratio of data used for training. baseid is the manually choosen base service used for the two simplified versions. This command might take a few hours to finish, as it runs for several budget values.
Once finished, the results are stored under output directory.
To visualize the result, please run
python3 visualizetools.py --dataname RAFDB \
--optimizer_name '100' '0' '1' '2' 'FrugalML' 'FrugalMLQSonly' 'FrugalMLFixBase' \
--optimizer_legend 'GitHub (CNN)' 'Google Vision' 'Face++' \
'MS Face' 'FrugalML' 'FrugalML(QS Only)' 'FrugalML (Base=GH)' \
--skip_optimizer_shift_x 1 -4 0.8 0.8 \
--skip_optimizer_shift_y -0.004 0.016 0.005 -0.012 \
--show_legend True \
--randseedset 1 5 10 50 100 \
--datasize 15339 \
--train_ratio_set 0.01 0.05 0.1 0.2 0.3 0.5
Here, dataname must be the same as the dataname when running optimizer_evaluate.py. optimizer_name is the list of all individual APIs' ids and FrugalML as well as the simplified versions. skip_optimizer_shift_x and skip_optimizer_shift_y control the coordinate of the legend for individual APIs. The generated figures are stored at figures.
More examples for running FrugalML can be at test_examples.sh, evaluate_examples.sh, and visualize_examples.sh.
We provide 12 datasets which contain 612,139 samples annotated by commercial APIs. FERPLUS, EXPW, RAFDB, and AFFECTNET are facial emotion recognition datasets. YELP, IMDB, WAIMAI, and SHOP are for sentiment analysis. DIGIT, AUDIOMNIST, COMMAND, and FLUENT are speech to text dataset. For more details about the raw data, please refer to our main paper
We first introduce the dataset format, using RAFDB as one example. The dataset is located at dataset/mlserviceperformance_RAFDB/. meta.csv contains the meta data information, including the ML APIs used, their IDs and associated cost per 10,000 data points.
For each API, seven files are provided. The same row in those seven files correpsonds to the same data point. For a given data point, the corresponding information includes image name, the predicted labels, the originally predicted labels, the confidence score, the true label, the reward (i.e., if the predicted label equals the true label), and the total reward (the sum of rewards on all data points).
Interested in using FrugalML for your own dataset? Of course! Simply prepare the meta.csv file to indicate which APIs are used, how much they cost, and their assigned IDs. Then generate the API's performance data files as explained above.
Finally, enjoy FrugalML on your own dataset!
If you find our work useful in your research, please cite:
@inproceedings{Chen2020FrugalML,
author = {Lingjiao Chen
and Matei Zaharia
and James Zou},
title = {FrugalML: How to Use ML Prediction APIs More Accurately and Cheaply},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year={2020}
}
Apache 2.0 © Lingjiao Chen.