Convert Evernote internal relative note links to Bear note links
![]()
![]()
![]()
![]()
![]()
Install Git, Python and Pipenv, then run the following commands in your terminal:
~
❯ git clone git@github.com:br3ndonland/el2bl.git ~/el2bl
~
❯ cd ~/el2bl
~/el2bl
❯ pipenv install --dev
~/el2bl
❯ pipenv shell
~/el2bl
el2bl-hash ❯ pre-commit install
~/el2bl
el2bl-hash ❯ python el2bl.pyWhat one ought to learn is how to extract patterns! You don't bother to memorize the literature-you learn to read and keep a shelf of books. You don't memorize log and sine tables; you buy a slide rule or learn to punch a public computer! … You don't have to know everything. You simply need to know where to find it when necessary.
From Stand on Zanzibar by John Brunner, Continuity 3
In the prescient 1968 science fiction novel Stand on Zanzibar, author John Brunner envisioned the coming Information Age. Brunner realized that the keys to success would be externalizing and finding information.
There is simply too much information for us to remember in biological memory (our brains), so we write it down and externalize it. In the past, paper books were the medium of choice, and today, we delegate the storage of information to computing machines. We use computer memory to store information, and operating systems to interact with memory.
We also need search engines to find information stored in computer memory. Search engines have become particularly important on the World Wide Web. The early days of the World Wide Web featured search engines with page results manually curated and organized by humans, but it became impossible for humans to organize that much information. Humans wrote algorithms (computer instructions), such as Google's PageRank, to organize information more efficiently, and search engines to locate the organized information for users. Google's stated mission is to "organize the world's information and make it universally accessible and useful." We all use search engines on the internet now.
Internet search engines can't do everything though. Note apps enable users to create searchable personal knowledgebases. Entering information into a note app creates an externalized mind, where information is retained and rapidly searched, and where disparate information sources can be connected in new ways. Clipping articles into a note app removes ads and formatting, stores the articles to read later, and helps assess sources of information over time. This is becoming more and more important, because we're presented with feeds that are manipulated by BUMMER algorithms.
Back in 2011, Evernote helped me digitize the information in my life and start externalizing my mind. By 2019, after eight years of extensive use, I had 5500 notes that formed a valuable personal knowledgebase. I had also experienced many bugs and frustrations over those eight years, and wanted to switch to a new note app.
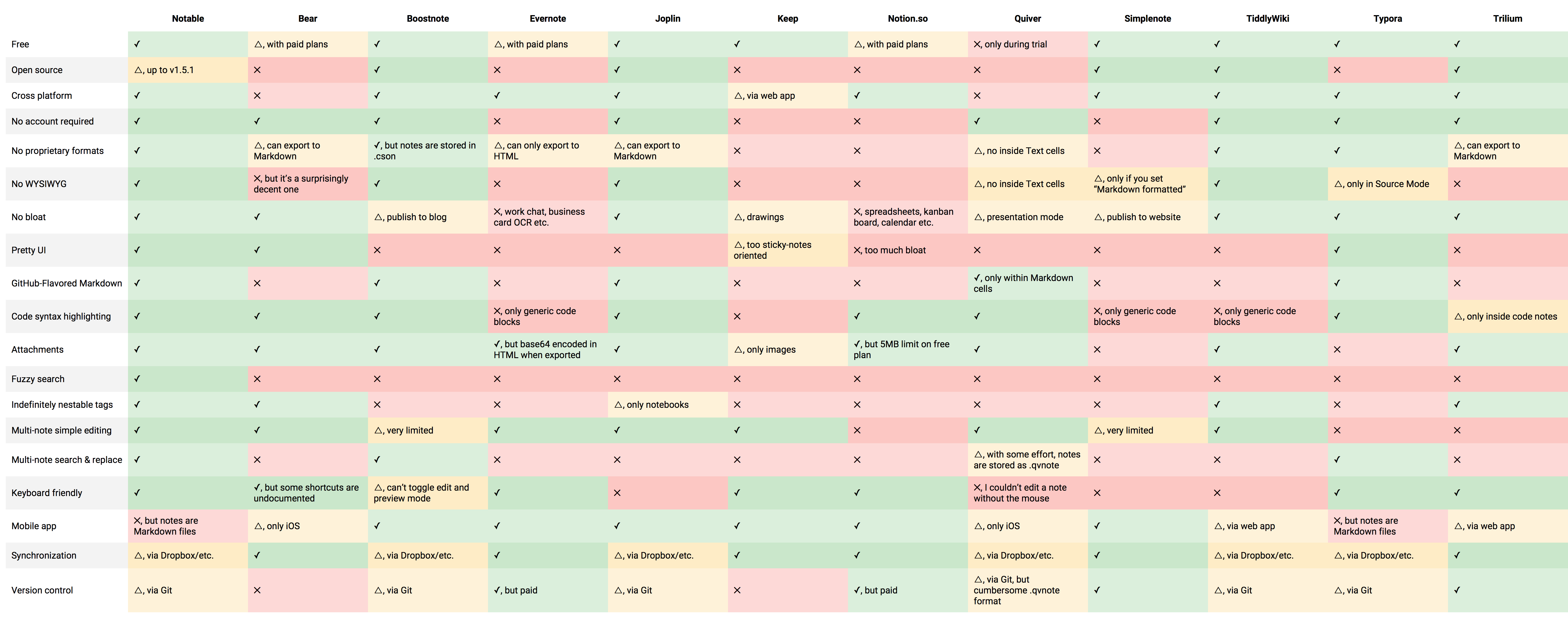
I definitely knew I wanted to ditch the Evernote XML format (sort of HTML-in-XML) and switch to Markdown. There are many note apps that use Markdown now, so it wasn't an issue. For some Markdown note app options, check out Notable's comparison chart and my Markdown guide.
{kind=link}
Another key feature I was looking for was note linking. Note links lead from one note to another within Evernote. Each note has its own link. Over time, note links create a personal encyclopedia or mind map of the connections among your notes, and enable quick navigation within the app. I therefore wanted to preserve the many note links I had created over the years. However, all the note apps I tried shared the same problem: Evernote note links aren't converted on import.
I first attempted to switch to Joplin, but settled on Bear because of how it handles note links.
I tried out Joplin, but found that internal note links import as Evernote links, not Joplin links. This is a critical issue for me. Links sometimes also just lead to the top note result in the notebook, rather than the specific note needed. To investigate this, I filed GitHub issue #585. The developer, Laurent Cozic, didn't even know you could make internal note links. Not a good sign. Laurent closed the issue because "Evernote doesn't export the note IDs."
The Evernote Developer API article on note links explains that relative links contain the note GUID. However, the .enex export doesn't attach the note GUID to the notes, so it's only possible for the Evernote source code (which is not open-source) to connect the GUID with the correct note.
One of the best Markdown note apps I came across was Bear. I was happy with the features and user experience overall, but it still failed to convert Evernote note links into Bear note links. I decided to reach out to Bear support to see if there was any way I could use it. Here's a support ticket I sent to Bear 20190301 (received by Bear Sat, Mar 2, 2019 at 02:10 AM):
I have been a heavy Evernote user for eight years. I've never been happy with it, and would love to switch to Bear. My main problem is note links (pointing to another note within Evernote). The note links are extremely important for me because they create a sort of mind map or personal Wikipedia that allows me to connect all my information. I have many internal/relative note links, and when imported into Bear, the links remain pointed at Evernote instead of Bear notes. The links look like this:
evernote:///view/6168869/s55/a51fb62f-8696-46ec-88d1-cceb38b2a2ed/a51fb62f-8696-46ec-88d1-cceb38b2a2ed/The "s55" might point to a database shard, and then I guess there's some sort of note ID after that. This is probably something Evernote handles on the back-end, and there might not be any way to know what the links actually point to in an exported .enex file.
The Evernote Developer API article on note links explains that relative links contain the note GUID. However, the .enex export doesn't include the GUIDs with the notes.
I attached a .enex file containing two notes with relative links in case this helps. I had used it to test import into another note app, Joplin. See Joplin issue #585 for a similar discussion.
Is there anything I can do? I probably have tens of thousands of these links in my 5500 notes, and it's just not feasible to correct the links after import into Bear. If I could figure out how to output the GUID, I could add it to each note's metadata and write a script to convert it to Joplin. I'm a developer and would be happy to run a script over the .enex prior to import if that helps.
Thanks for your help, and keep up the good work.
Here's the response:
Hi Brendon
Thank you for reaching us out.
Unfortunately, these links will not be converted into the bear note links due to different workflow and separate API that Bear and Evernote use. Please refer to this link for the notes linking in the Bear app https://bear.app/faq/Tags%20&%20Linking/How%20to%20link%20notes%20together/
Please let us know if you have any more concerns/questions.
Thank you.
Pretty lame, but I wasn't deterred by this response. After working with Bear a bit more, I was buoyed when I realized it has a key feature: creating note links by placing note titles within double brackets, like [[Note title]]. Much as the Evernote source code matches up note GUIDs with the correct notes, the Bear source code locates the note using the title within the double brackets, and links the note appropriately.
This means that changing note titles could break the links. As of Bear 1.7, this isn't a problem, because Bear automatically updates note links when note titles change.
I decided to write a Python script that would convert Evernote note links to Bear note links.
- The code in this repository was written with Microsoft Visual Studio Code (VSCode).
- My full VSCode config is available in this public GitHub Gist. If you would like to use these settings, you can fork the gist into your account, and pull in the settings with the Settings Sync extension.
-
Code was version-controlled with Git, using the following general Git practices:
- Imperative, capitalized commit title limited to 50 characters and without a period at the end
- Blank line between commit title and body
- Commit body wrapped at 72 characters
- When branching:
- The
masteranddevelopbranches are generally long-running branches. - Short-lived feature branches are merged to
develop, then deleted. - The only commits to
masterare production-ready merges fromdevelop.
- The
-
Here's a sample commit message based on the practices above:
Imperative commit title limited to 50 characters # Blank line - More detailed commit message body - List of key points and updates that the commit provides - Lines need to be manually wrapped at 72 characters -
Git pre-commit hooks are managed with pre-commit. After cloning the repository, enter the Python virtual environment and install pre-commit:
pipenv shell pre-commit install
- Markdown was written with the Markdown All in One VSCode extension, and autoformatted with Prettier using the Prettier VSCode extension.
- The Prettier pre-commit hook was installed.
-
Pipenv was used to manage the development virtual environment for this project.
-
Install Pipenv with a system package manager like Homebrew, or with the Python package manager
pip. -
Use Pipenv to install the virtual environment from the Pipfile with
pipenv install --dev --pre.-
The
devflag was used to accommodate the Black autoformatter (see code style below). -
When generating a Pipfile.lock containing dev packages, the
--preflag allows pre-releases into the lock file. A line will be added to the Pipfile (TOML format):[pipenv] allow_prereleases = true
-
Package versions can be specified in the Pipfile.
[packages] # Install version 4.7.1 and do not upgrade beautifulsoup4 = "==4.7.1" # Install version 4.4.0 or above beautifulsoup4 = ">=4.4.0"
-
Further information can be found in the Pipenv docs.
-
-
Activate the virtual environment with
pipenv shell.
-
-
VSCode can be configured to recognize the Pipenv virtual environment. See Using Python environments in VS Code.
- Command Palette -> Python: Select Interpreter. Select virtual environment.
- Command Palette -> Python: Create Terminal. Creates a terminal and automatically activates the virtual environment. If the virtual environment is set as the interpreter for the workspace, new terminal windows will automatically start in the virtual environment.
- Python code was autoformatted with Black.
- Black limits line length to 88 characters.
- Black is still considered a pre-release. As described in Pipenv, pre-releases must be installed with the
--devflag (pipenv install black --dev), then added to the Pipfile.lock with pre-releases allowed. - The Black Git pre-commit hook has been installed for this project.
- The first step is to locate a set of Evernote export files. I used the
osmodule for this. - File paths can be verified with
os.path.exists(). - Directories can be created with
os.mkdir().
- The
withstatement was introduced in PEP 343, and provides context management for working with files. As explained in the Python Tricks context managers article and the Python Tricks file i/o article, the advantage of using thewithstatement over simplyfile.open()is that it creates a context under which file operations can occur and be automatically concluded. - To save output to a new file, I used a nested
withstatement, and included"x"for exclusive creation mode, which creates the new file. For a helpful demo of a nestedwithstatement, see Corey Schafer's YouTube tutorial on Python file objects. - I also looked into
fileinput, but decided against it. Brian Okken wrote a blog post about usingfileinputfor find and replace, back in 2013. I consideredfileinputafter reading his post, but didn't particularly like it.fileinputalso doesn't have strong community support, as this StackOverflow user says:If you really want to redirect stdout to your file for some reason, it's not hard to do it better than fileinput does (basically, use try..finally or a contextmanager to ensure you set stdout back to it's original value afterwards). The source code for fileinput is pretty eye-bleedingly awful, and it does some really unsafe things under the hood. If it were written today I very much doubt it would have made it into the stdlib. – craigds Dec 18 '14 at 22:06
-
I decided to try out Beautiful Soup. Beautiful Soup is usually used to parse webpages, as described in this DigitalOcean tutorial, but Evernote notes are basically webpages, so Beautiful Soup makes sense here. There are a few other options described in The Hitchhiker's Guide to Python scenario guide to XML parsing, which strangely does not mention Beautiful Soup.
-
-
This is not straightforward, because Evernote XML is a blend of XML and HTML, and many parsers depend on a valid HTML tree.
-
I first tried parsing XML, using
xml, the XML parser inlxml. I couldn't match links, and HTML elements were being read like<div>instead of<div>. -
I had some success with
lxml(the HTML parser inlxml). It was lenient enough to read the XML parts, and parse the document into valid HTML. Thelxmlparser made it easy to match Evernote note links:-
I started by learning about the different kinds of filters.
-
I used an
hrefattribute filter and a regular expression filter to identify Evernote note links. This method avoids replacing URLs that are not Evernote note links, such as https://evernote.com/, and Evernote note links outside of anchor tags, such as the text "the links are converted toevernote:///." The function looked like this:def note_link(href): """Identify note link URIs using href attribute and regex""" return href and re.compile(r"evernote://").search(href)
-
I then passed the
note_link()function intosoup.find_all()to locate all note links, extracted the strings (note titles) from the links using the string argument, and replaced the links with the titles within double brackets.for link in soup.find_all(href=note_link): string = link.string.extract() bear_link = link.replace_with(f"[[{string}]]")
-
I could then print the output and see the note links properly replaced within the notes. The full function looked like this:
def convert_links(file): """Convert links in .enex files to Bear note link format. """ with open(file) as enex: def note_link(href): """Identify note link URIs using href attribute and regex""" return href and re.compile(r"evernote://").search(href) soup = BeautifulSoup(enex, "lxml") for link in soup.find_all(href=note_link): string = link.string.extract() bear_link = link.replace_with(f"[[{string}]]") with open(f"{os.path.dirname(file)}/bear/{file.name}", "x") as new_enex: new_enex.write(str(soup))
-
-
The problem was that, in order to parse the document,
lxmlwas modifying the formatting by adding<html>and<body>tags and removing theCDATAsections. Trying to import files modified in this way crashes Bear. -
I had similar problems with
html5lib. The html5lib parser also forces some formatting by adding comments around the XML portions. -
I then went back to the default Python
html.parser. Thehtml.parserdoesn't modify formatting, but because the Evernote export is not valid HTML, it's not able to parse the tags likelxmldoes. For example, here's the result of modifyingconvert_links(file)to print the tags Beautiful Soup finds in the document:with open(file) as enex: soup = BeautifulSoup(enex, "html.parser") for tag in soup.find_all(True): print(tag.name)
en-export note title content created updated tag note-attributes author source reminder-order note title content created updated tag note-attributes author source source-url reminder-order -
The note body is located within the
contenttag. -
I considered selectively parsing the
contenttag with SoupStrainer. -
At this point, I realized I could just rely on
reto match and replace regular expressions, rather than trying to get Beautiful Soup to work with tags.
-
-
After opening a file, Evernote links can be located with regular expressions (regex).
-
The Python
repackage provides helpful features for regex operations. RegExr can be used to test out regex. -
Raw string notation (
r"") enables developers to enter regular expressions into Python code without having to escape special characters, as described in theredocumentation. -
An Evernote note link can be matched with:
re.compile(r'(<a href="evernote.*?>)(.*?)(</a>?)')
and replaced with
re.sub(r'(<a href="evernote.*?>)(.*?)(</a>?)', r"[[\2]]", soup)
When replacing the match,
r"[[\2]]"includes a backreference to the second capture group (the string inside the note link). This tellsreto retain the second capture group. The question mark is particularly important in the second capture group,(.*?). Without the question mark, Python will continue through the remainder of the string to the last occurrence of the third capture group(</a>?), rather than stopping at the first occurrence. -
I used a second regular expression to strip H1 tags out of the notes. Many clipped news articles include the article title within H1 tags, but in Bear, the note title serves as H1, so headers in the note body should begin with H2. Again here, I used a backreference to the second capture group to retain the text within the H1 tags. To run both the
re.sub()operations, I just overwrote the object created from the firstre.sub().soup_sub = re.sub(r'(<a href="evernote.*?>)(.*?)(</a>?)', r"[[\2]]", soup) soup_sub = re.sub(r"(<h1>?)(.*?)(</h1>?)", r"\2", soup_sub)
-
The
soup_subobject can then be written to a new file using the nestedwithstatement.with open(file) as enex: soup = str(BeautifulSoup(enex, "html.parser")) soup_sub = re.sub(r'(<a href="evernote.*?>)(.*?)(</a>?)', r"[[\2]]", soup) soup_sub = re.sub(r"(<h1>?)(.*?)(</h1>?)", r"\2", soup_sub) with open(f"{os.path.dirname(file)}/bear/{file.name}", "x") as new_enex: new_enex.write(soup_sub)
Success! I tagged the repository at commit 788a00e as v0.1.0.
-
v0.1.0 converted most of the links in my Evernote exports, but missed some. Further inspection showed that Evernote was inserting additional tags between the opening anchor tag a and the href, like:
<a style="font-weight: bold;" href="evernote:///">Title</a> -
v0.2.0 correctly matches Evernote links, even if additional tags have been inserted into the anchor tag. The regex only needed a minor update to overlook the additional tags inside the anchor tag, from
(<a href="evernote.*?>)(.*?)(</a>?)to(<a.*?href="evernote.*?>)(.*?)(</a>?). Here'sconvert_links(file)after the update:def convert_links(file): """Convert links in .enex files to Bear note link format. --- - Read contents of file with Beautiful Soup, and convert to string - Replace Evernote note link URIs, but not other URIs, with Bear note links - Remove H1 tags from note body - Write to a new file in the bear subdirectory """ with open(file) as enex: soup = str(BeautifulSoup(enex, "html.parser")) soup_sub = re.sub(r'(<a.*?href="evernote.*?>)(.*?)(</a>?)', r"[[\2]]", soup) soup_sub = re.sub(r"(<h1>?)(.*?)(</h1>?)", r"\2", soup_sub) with open(f"{os.path.dirname(file)}/bear/{file.name}", "x") as new_enex: new_enex.write(soup_sub)
-
I also tried another pattern matching package, Pampy (Pattern Matching for Python, GitHub | PyPI). Pampy helps flexibly match patterns and make code more readable. There are some use cases for which Pampy could be quite helpful (for example, matching dictionaries and tuples).
-
I heard about Pampy on Python Bytes episode 107 (December 7, 2018).
-
I wrote up a preliminary function to match links in a .enex Evernote export file:
def match_link(file): """Match link in .enex file with Pampy. """ try: path = input("Please provide the file path to your Evernote exports: ") if os.path.exists(path): print(f"Valid file path: {path}") if not os.path.exists(f"{path}/bear"): os.mkdir(f"{path}/bear") for file in os.scandir(path): if file.name.endswith(".enex") and file.is_file(): with open(file) as enex: return match( enex, re.compile(r'(<a href="evernote.*?>)(.*?)(</a>?)'), lambda link_start, title, link_end: print(f"Link title: {title}"), ) else: print(f"{path} is not a valid path.") except Exception as e: print(f"An error occurred:\n{e}\nPlease try again.")
-
After working with Pampy, I didn't find that it addressed my needs in this project. Finding all matches, replacing matches, and working with strings were not as easy as they should be.
I chose Python for this project, but for a comparable JavaScript/TypeScript implementation, see notable/dumper, particularly enex.ts.