![]()
This repository is designed to demonstrate a simple yet complete machine learning solution that uses a BERT model for text sentiment analysis using a TensorFlow Extended end-to-end pipeline, and making use of some of the best practices from the MLOps domain, it will cover steps from data ingestion until model serving and consuming it either with REST or gRPC requests.
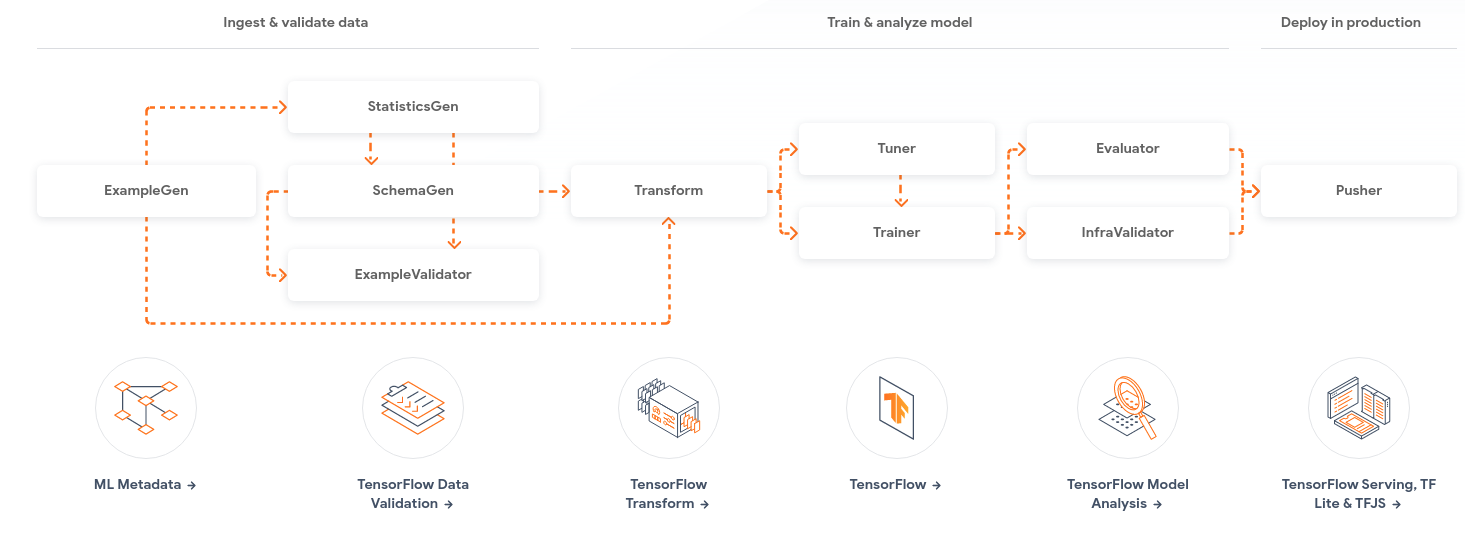
The end-to-end TFX pipeline will cover most of the main areas of a machine learning solution, from data ingestion and validation to model training and serving, those steps are further described below, this repository also aims to provide different options for managing the pipeline, this will be done using orchestrators, the orchestrators covered will be AirFlow, KubeFlow and an interactive option that can be used at Google Colab for demonstration purposes.
ExampleGenis the initial input component of a pipeline that ingests and optionally splits the input dataset.- Reads the
IMDBdataset stored as aCSVfile and spits the data into train (2/3) and validation (1/3).
- Reads the
StatisticsGencalculates statistics for the dataset.- Generate statistics for text and label distribution.
SchemaGenexamines the statistics and creates a data schema.ExampleValidatorlooks for anomalies and missing values in the dataset.- Validates the input data based on the
SchemaGen's schema.
- Validates the input data based on the
Transformperforms feature engineering on the dataset.- Input missing data and do basic data pre-processing.
Tuneruseskerastunerto perform hyperparameters tuning for the model.- The optimal hyperparameters will be used by the
Trainer
- The optimal hyperparameters will be used by the
Trainertrains the model.- Train the custom pre-trained
BERTmodel, this model also has a built-in text tokenizer.
- Train the custom pre-trained
Resolverperforms model validation.- Resolve a model to be used as a baseline for model validation.
Evaluatorperforms deep analysis of the training results and helps you validate your exported models, ensuring that they are "good enough" to be pushed to production.InfraValidatorused as an early warning layer before pushing a model into production. The name "infra" validator came from the fact that it is validating the model in the actual model serving "infrastructure".- Evaluate the model's accuracy over the complete dataset and across different data slices, also evaluate new models against a baseline.
Pusherdeploys the model on a serving infrastructure.- Export the model for serving if the new model improved over the baseline.
At the modeling part, we are going to use the BERT model, for better performance we will use transfer learning, this means that we are using a model that was pre-trained on another task (usually a task that is more generic or similar), from the pre-trained model we will use all layers until the output of the last embedding, to be more specific only the output from the CLS token, shown in the image below, then we add a classifier layer at the top, this classifier layer will be responsible for classifying the input text as being positive or negative, this task is also known as sentiment analysis, and is very common in natural language processing.

The dataset used for training and evaluating the model is the known IMDB review dataset, this dataset has 25,000 movies reviews, being either negative (label 0) or positive (label 1), this dataset was slightly processed to be used here, labels have been encoded to be integers (0 or 1), and for faster experimentation, the data was reduced to have only 5,000 samples.