本项目用C++实现了Raft一致性算法,并在此基础上实现了一个Fault-tolerant Key/Value Service. 严格来说这里实现的Raft协议是不完整的,日志压缩和成员变更都没有实现。
本项目依赖我的另一个项目melon 和Protocol Buffers。
首先将melon clone到本地,然后在melon主目录下新建build目录,进入build目录执行:
cmake ..
make
make install
提前安装好Protocol Buffers,然后将cherry clone到本地,进入src目录执行:
protoc -I=. --cpp_out=. args.proto
将args.proto文件编译成cpp代码。 然后在cherry主目录下新建build目录,进入build目录执行:
cmake ..
make
raft算法之所以简单的原因之一是它将问题分解成三个子问题,分别是:
- Leader选举
- Log复制
- 安全性保证
raft协议中每个server都要维护一些状态,并且对外提供两个RPC调用分别是RequestVote RPC和AppendEntries RPC用于选举和log复制。 要想理解raft,其实就是搞明白:
- leader和follower需要维护哪些变量,每个变量的含义
- leader什么时候发送AppendEntries RPC,携带哪些参数,follower收到请求后做什么?leader收到响应后做什么?
- candidate什么时候发送RequestVote RPC,携带哪些参数,follower收到请求后做什么?candidate收到响应后做什么?



raft所有的操作都是为了保证如下这些性质。
- Election Safety: at most one leader can be elected in a given term.
- Leader Append-Only: a leader never overwrites or deletes entries in its log; it only appends new entries.
- Log Matching: if two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index.
- Leader Completeness: if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms.
- State Machine Safety: if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index.
暂时可以先不看,需要知道的是raft所有的规则都是为了保证上面的这些性质,而这些性质又是保证raft正确的前提。
Election Safety性质说的在某个term中最多只能选出一个leader。 有如下这些规则:
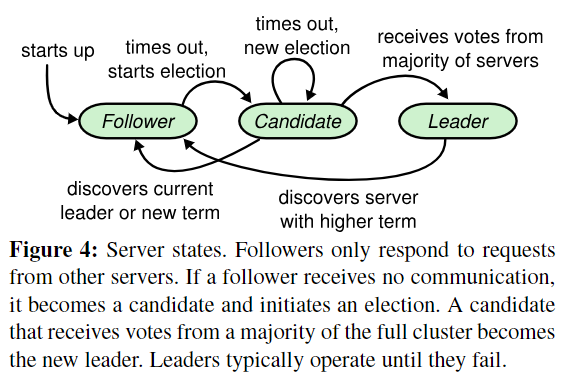
- raft将时间划分为term,每个term都有一个number,每个term以选举一个leader开始。
- 每个server有三种状态:leader, follower, candidate。
- 作为follower:有一个称为election timeout的倒计时,如果在倒计时内没有收到有效的AppendEntries RPC,将转换为candidate,增加自己的term number,投自己一票,然后通过RequestVote RPC通知集群中的其他server进行投票。当半数以上的RequestVote RPC返回true后,这个candidate将转换为leader。
- 某个server收到RequestVote RPC后如何确定要不要投赞同票?同时满足以下三个条件则投赞同,RequestVote RPC返回成功:
- 在当前周期内还没有投过票
- candidate中term不小于自己的term
- "选举限制"(这是论文在5.4 Safety这一小节给的一个restriction补充) :想要获得投票,candidate的logs必须比当前follower的logs更up-to-date。如何比较两个logs的up-to-date程度?最后一个log entry的term大的更up-to-date, 如果term一样,index越大越up-to-date。(这一restriction保证了Leader Completeness Property,这个属性说的是:作为leader必须要有已经被commit的log,很容易理解,leader作为log分发的源头,如果leader自己都没办法保证自己的log包含了所有已经commit的log,那么怎么保证其他的follower的log能正确)
- 作为leader:周期性的发送AppendEntries RPC。
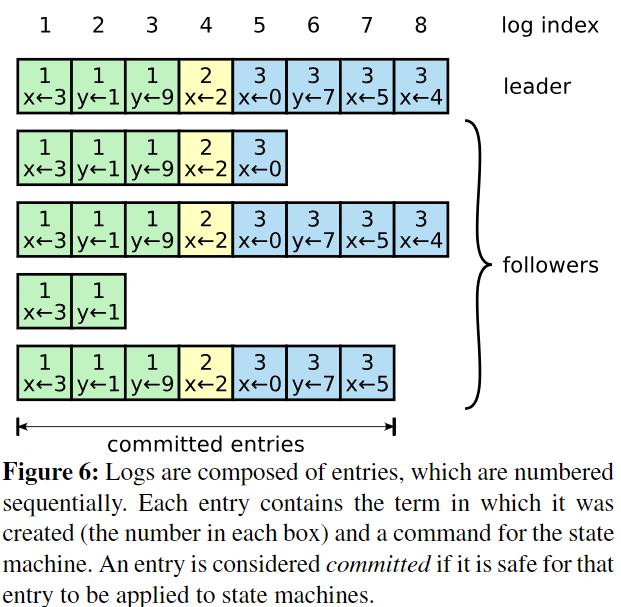
Logs由Entries组成,每个Entry包含一个term和命令,格式如下:
- leader接收客户端的Entry,将Entry添加自己的logs中。
- leader周期性使用AppendEntries RPC将新的entry备份到其它server。
- follower收到AppendEntries RPC后做什么?进行一致性检查。
follower收到AppendEntries RPCs后,会进行一致性检查。 leader为每个follower维护一个nextIndex变量,新上位的leader的nextIndex初始化为当前logs的最后一个log的index+1。
假设leader的logs为:[index1, term=1, cmd1],[index=2, term=3, cmd2], [index=3, term=3, cmd3] 假设某个follower的log为:[index1, term=1, cmd1],[index=2, term=1, cmd4]
第一次leader的AppendEntries RPC发给某个follower的log为[index=3, term=3, cmd3]这一个log entry,那么AppendEntries RPC同时会携带preLogIndex和preLogTerm两个参数,preLogIndex为要发送的log的前一个index,这里是2。preLogTerm为leader index为1位置的log的term,这里是3。
follower在收到AppendEntries RPC后,根据参数中的prevLogIndex,检查自己的log的prevLogIndex处的Entry的term和参数中的prevLogTerm是否相同,如果相同则将参数中的entries拷贝到自己的log中并且返回true,否则返回false。
follower在收到leader的AppendEntries RPC后,进行一致性检查,根据参数prevLogIndex=2,发现自己的index为2的log的term为1,和参数preLogTerm(这里是3)不一致。所以什么也不做返回false。 leader收到响应后如果发现是false,调整参数然后重新发送AppendEntries RPC。leader将要发送的log改为[index=2, term=3, cmd2], [index=3, term=3, cmd3],preLogIndex参数变为了1,preLogTerm参数变为了1。 follower在收到这个AppendEntries RPC后,发现自己的index为1的log的term为1,和参数preLogTerm(这里是1)一致。于是就将preLogIndex(这里是1)后的Log([index=2, term=1, cmd4])删除,将AppendEntries RPC参数中的log [index=2, term=3, cmd2], [index=3, term=3, cmd3]加到自己的log后。 现在follower的log变为了:[index1, term=1, cmd1],[index=2, term=3, cmd2], [index=3, term=3, cmd3]。和leader一致。
Entry如果已经确定可以安全apply到状态机的情况下,将被标志为commited。看上面state图中,每个server都维护两个变量commitIndex和lastApplied。这两个变量都是初始化为0,比如Figure 6中leader的commitIndex就是6,这个值会在 AppendEntries RPC中以leaderCommit参数通知followers修改自己的commitIndex。
commitIndex和lastApplied有什么区别呢?lastApplied总是<=commitIndex,commitIndex表明的是到commitIndex为止可以被apply,lastApplied表明的是到lastApplied为止已经被apply。
什么情况下Entry可以被commit?满足以下两个条件:
- A log entry is committed once the leader that created the entry has replicated it on a majority of the servers.(leader将该entry拷贝到大部分server中)
- 不能commit term比当前leader的term小的Entry。和前面leader选举限制一样,这也是论文在5.4 Safety这一小节给的一个restriction。不是很好理解,论文在5.4.2节给出了解释。
如下图:
(a):S1是leader(term=2),entry 2只拷贝到了S2就奔溃了。 (b):S5成为新的leader(term=3),并且接收了entry 3,但是还没进行拷贝也崩溃了。 (c):S1重新成为leader(这时term=4),并且将entry 2拷贝到了S3。如果没有条件2的限制,只看条件1,Entry 2已经被复制到了大部分的server中,就可以被commit了。那么问题来了,如果Entry 2被commit后S1又奔溃了,这时S5重新成为leader(根据上文给出的选举规则,S5最后一个Entry的term是3,可以获得S2, S3, S4和自己的投票,所以可以成为leader),并将Entry 3拷贝到其它的server(情况(d)),并且commit,这样之前commit的Entry 2就被覆盖了,这是绝对不允许的,已经被commit的Entry不能被覆盖。再次回到情况(c),这时如果S1不仅复制了Entry 2还复制了Entry 4(term=4)(情况(e)),这种情况下同时满足条件1和条件2,所以可以commit Entry 2和Entry 4,因为和之前不同的是,如果S1现在奔溃了,S5不可能成为leader(S5的最后一个Entry的term=3,S1, S2, S3都会拒绝投票,因为它们的logs更up-to-date),也就不可能出现commit的Entry被覆盖的情况。
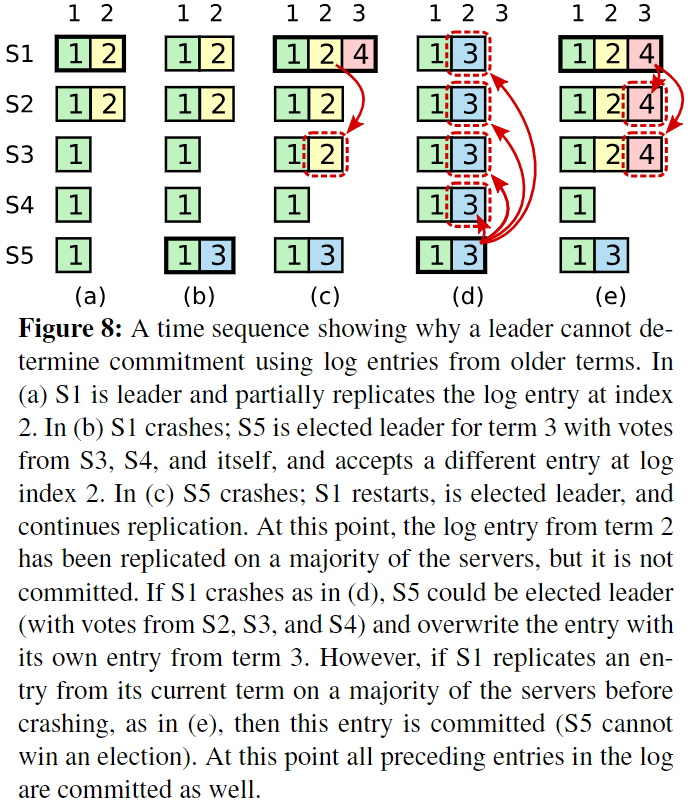
这个图画的有点歧义,我总结下,(c)如果不考虑条件2的限制,可能会出现(d),(d)是不允许出现的。(c)如果同时考虑条件1和条件2,那么可能出现(e),(e)是合法的,绝不可能出现(d)这种情况。所以条件2是必要的。
论文中指出raft正确性已经使用TLA+ specification language进行了证明,顺便搜了下这个TLA+ specification language,由Leslie Lamport发明,用来验证设计的正确性的语言,这个Leslie Lamport也是NB的一塌糊涂,Paxos算法也是他设计出来的。我没有仔细研究严格的证明,只是以一种不严格的方式试图解释下为什么raft可以保证一致性。
raft中所有的log都是由leader流向follower的,所以你leader首先得保证拥有所有的committed log吧,这就是Leader Completeness属性。那么如何保证Leader Completeness属性呢。我认为以下这些规则保证了该属性:
- Entry需要被大部分server接收才能被commit。
- leader需要大部分server投赞成票才能成为leader。
- "选举限制":想要获得投票,candidate的logs必须比当前follower的logs更up-to-date。
可以用反证法来证明: 假设Leader Completeness属性不成立,term T的leader(T) commit了一个Entry,但是新的term U的leader(U)没有包含该Entry。 leader(T)已经commit了该Entry,所以该Entry肯定被大部分server接受了,leader(T)成为leader肯定收到了大部分server的投票,那么必定存在一个server既接受了该这个Entry也投了leader(U)一票。显然该server包含的log比leader(T)的要up-to-date,所以和规则3矛盾,所以假设不成立,Leader Completeness属性成立。
保证了源头log的正确性后,拷贝过程中也要保证和leader的log一致。Log Matching属性保证了这一点,该属性描述的是:如果两个server中logs中的某个index对应的log entry的term相同,那么这个index以及之前对应的log entry都应该保证一样。一致性检查规则可以保证该属性。
raft这些性质中最重要的就是保证State Machine Safety属性,该属性描述的是任何一个server在某个index apply一个Entry,其它server不会在该index处apply一个不同的Entry。Leader Completeness + Log Matching可以推出State Machine Safety。
本项目的测试思路参考了MIT 6.824的测试思路。 在本地用一个进程内的多个Raft对象进行模拟,PolishedRpcClient将melon::RpcClient做了个封装,对外提供setConnected()方法,以此模拟某个Raft对象断开网络连接的场景。具体见test/Config.cpp。
检查启动后每个term内有且只有一个Leader,在没有网络问题的情况下term不变。
RaftA(√) RaftB(√) RaftC(√)
假设RaftA是leader1,切断leader1的网络连接。
RaftA(X) RaftB(√) RaftC(√)
此时应该在RaftB和RaftC中选举新的leader,假设是RaftB,称为leader2。
将RaftA重新连接,此时不应该干扰新的leader2,同时RaftA会变成Follower。
RaftA(√) RaftB(√) RaftC(√)
同时断开leader2也就是RaftB和RaftC的网络。
RaftA(√) RaftB(X) RaftC(X)
检测此时没有新的leader被选出。
将RaftC重新连接,此时应该有新的leader被选出。
RaftA(√) RaftB(X) RaftC(√)
最后再将RaftB重新连接,不影响上一步新选出的leader的地位。
全程没有网络断开的情况,向leader发送三个cmd,检查所有raft的日志达到一致。
RaftA(√) RaftB(√) RaftC(√)
假设RaftA是leader1,向leader1发送一个命令,检查三个Raft达成一致。
切断某个Follower的连接,比如RaftB。
RaftA(√) RaftB(X) RaftC(√)
再次向leader1发送一个命令,检查RaftA和RaftC达成一致。
将RaftB重新连接,然后向leader1发送一个命令,检查三个Raft达成一致。
RaftA(√) RaftB(√) RaftC(√) RaftD(√) RaftD(√)
假设RaftA是leader1,向leader1发送一个命令,检查5个Raft达成一致。
切断RaftB, RaftC, RaftD三个Follwer的网络,然后向RaftA发送一个命令,检查RaftA和RaftD不会commit该命令。
RaftA(√) RaftB(X) RaftC(X) RaftD(X) RaftD(√)
重新连接RaftB, RaftC, RaftD的网络,此时可能选出了一个新的leader2。
RaftA(√) RaftB(√) RaftC(√) RaftD(√) RaftD(√)
向leader2发送一个命令,检查五个Raft达成一致。
RaftA(√) RaftB(√) RaftC(√)
假设最开始RaftA是leader。先向leader发送一个命令101。此时状态应该如下:
RaftA(√, 【101】) RaftB(√, 【101】) RaftC(√, 【101】)
此时断开RaftA的网络,然后向RaftA发送三个命令102, 103, 104:
RaftA(X, 【101,102,103,104】) RaftB(√, 【101】) RaftC(√, 【101】)
因为RaftA断开了网络所以102,103,104不会commit,同时RaftB和RaftC间会选举新的leader。假设是RaftB。
向RaftB发送一个命令103。
RaftA(X, 【101,102,103,104】) RaftB(√, 【101,103】) RaftC(√, 【101,103】)
这个103会被RaftC接收,并且commit。
此时断开RaftB的网络,重连RaftA的网络。
RaftA(√, 【101,102,103,104】) RaftB(X, 【101,103】) RaftC(√, 【101,103】)
因为RaftC的日志比RaftA的日志更up to date,所以会成为新的leader。同时会将自己的日志拷贝给RaftA。
RaftA(√, 【101,103】) RaftB(X, 【101,103】) RaftC(√, 【101,103】)
最后将RaftB也重新连接,在向RaftC发送104,三个raft达成一致,最后的状态应该如下:
RaftA(√, 【101,103,104】) RaftB(√, 【101,103,104】) RaftC(√, 【101,103,104】)
RaftA(√) RaftB(√) RaftC(√) RaftD(√) RaftD(√)
假设最开始RaftA是leader1,将RaftB, RaftC, RaftD断开网络连接。
向RaftA发一些命令,这些命令不应该被commit。
RaftA(√) RaftB(X) RaftC(X) RaftD(X) RaftD(√)
将RaftA和RaftD断开连接,重新连接RaftB, RaftC, RaftD。
RaftA(X) RaftB(√) RaftC(√) RaftD(√) RaftD(X)
此时RaftB, RaftC,RaftD中会选出一个新的leader2,假设是RaftB,向RaftB发送一些命令,这些命令会被RaftC, RaftD接收,并commit。
此时再次断开RaftC和RaftD中的其中一个的网络连接,假设是RaftC。
RaftA(X) RaftB(√) RaftC(X) RaftD(√) RaftD(X)
此时向RaftB发送一些命令,这些命令不会被commit。
这时重新连接RaftA, RaftC, RaftD,断开RaftB, RaftD。
RaftA(√) RaftB(X) RaftC(√) RaftD(X) RaftD(√)
此时RaftC应该成为新的leader,RaftC发送一些命令,这些命令会被commit。
最后将RaftB,RaftD重连。
RaftA(√) RaftB(√) RaftC(√) RaftD(√) RaftD(√)
以上这些测试,我都在本地跑过了150次。
TODO:
- 日志压缩。
- 完善测试用例。
参考资料: