The oxford flower-102 dataset contains pictures of 102 classes of flowers, wherein each class contains 40 to 250 images. In total, there are 8189 images distributed across these 102 classes which makes it look not so much of a good task for conventional classification techniques. This repository contains information regarding each of those aspects, data reading, pre-processing, data visualization, conventional CNN's, their limitaions, transfer learning and their best tips. Also, we will see how to use this code for any other purpose.
First off, in Data Visualization notebook, we see that the dataset contains flowers in different colours, orientation, position, size, translation. Thus, data augmentation is a key step in this problem. Next up, the fine details are better capture with more resolution. Thus, its ideal to experiment with 224x224 dimension images. However, I have experimented at different times with 64x64 and 128x128 due to the limitation of resources. 
Next up, we build (and see) a normal CNN with 3 Convolution layers, each followed by pool layers and Dropout at each step. Finally, the output flattened and connected to a couple of fully connected layers. In Cross Validation, we see that we can easily find the idea number of iterations (and similarly other parameters), but the model fails to generalize and yields 44% accuracy on unseen test cases. Data Augmentation and Ensemble methods won't effect the results by large scale. Plots of Normal CNN training showing training and cross validation loss and accuracy are shown below. 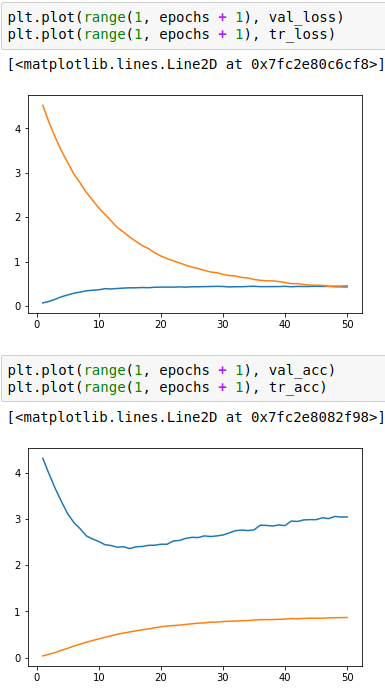
Finally, we bet on Transfer Learning and Fine tuning, which is a great approach if the available data is small and similar to the base model. Since, the bicos data is very much similar to some classes in the Imagenet. Thus, using VGG16 can be of great help. To further boost the performance, I use several image augmentation techniques (rotation, skewing, flip, translate, scale etc) in the batch generator. Finally, we perform a cross validation to perform the parameter search and return the best model. (Code is given, however, I couldnt report the performance due to resource constraints, However, with a single train, validation split, the transfer learning and data augmentation model reaches 72% accuracy, which can be easily improved by better parameter search and cross validation. Also, when we move to larger image size, the performance of the model is bound to increase. Shown below is the Transfer Learning training log (without parameter tuning) 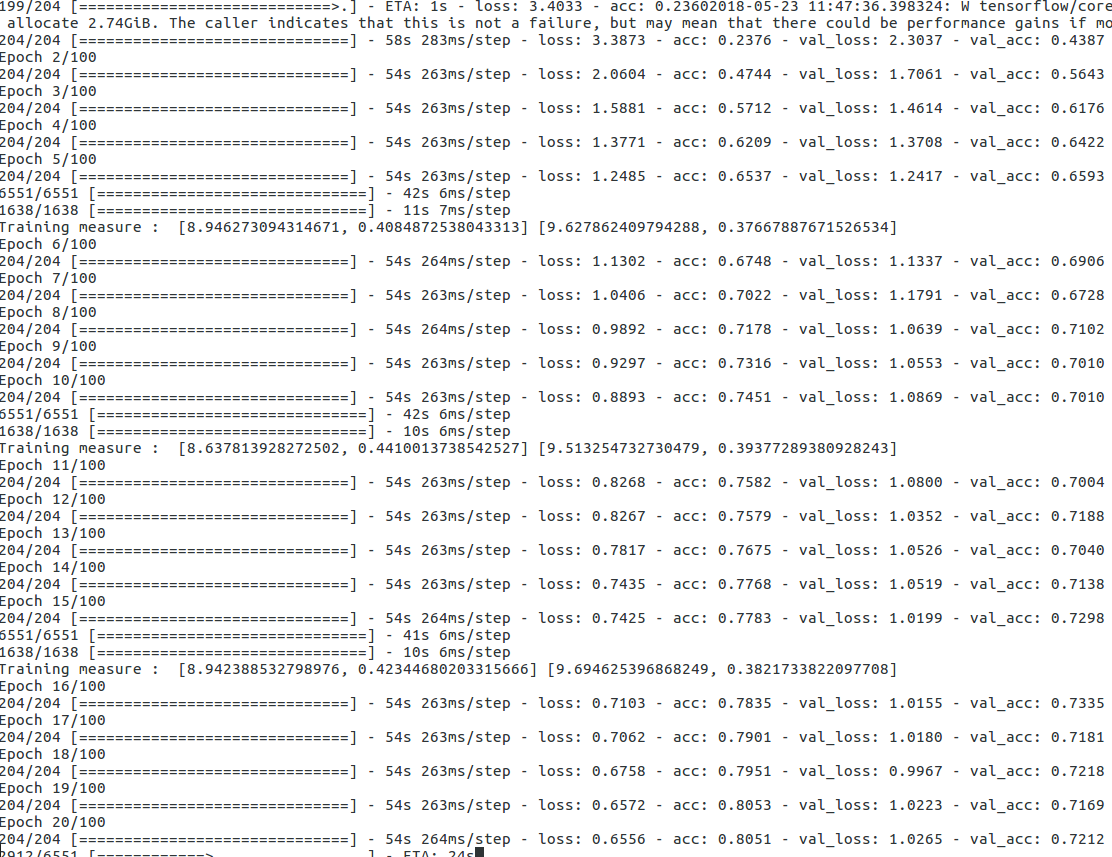
The structure of the repository is simple, a python file "data.py" for data transformation and data files generation in different shapes, which will be used as is by the models and other jupyer notebooks, so that the reader can go through the code and the output.
First off, collect the dataset run the data.py file using command python data.py which will generate necessary files. Then explore and run Data Visualization.ipynb, Basic CNN.ipynb and Transfer Learning and fine tuning with data augmentation.ipynb. Also, ignore the Initial Tensorflow attempt of CNN.ipynb as it contains my initial attempt of building the model using tensorflow, but there were some version incompatibility in internal libraries and some bugs which were causing memory overflow errors. I will surely handle this issue in near time.
- Since the number of images is less and number of classes are high, training from scratch fails abruptly
- Using VGG16 highly increases the performance as the imagenet and this dataset has many similar images (hence features).
- Using Data Augmentation further boosts the performance
- Cross-validation helps in parameter tuning of all aspects
- Since the number of images is less, fine-tuning probably won't help much, however, its one in the todo list (easy to code but resource constraint) Future Work
- Generalization error should be assessed properly on unseen data as validation performance can be misleading. For this, we divide the data into train and test. Further, divide the train data into train and validation (or cross-validation depending on the usage). However, the final performance must be reported on the test set.
- tSNE doesn't helps much in visualization and understanding (this) dataset
- Last but not the least, we can also take output of some intermediate layers and train a simpler model (like SVM) to handle case if the data distribution is different from the one on which base model was trained. Future Work