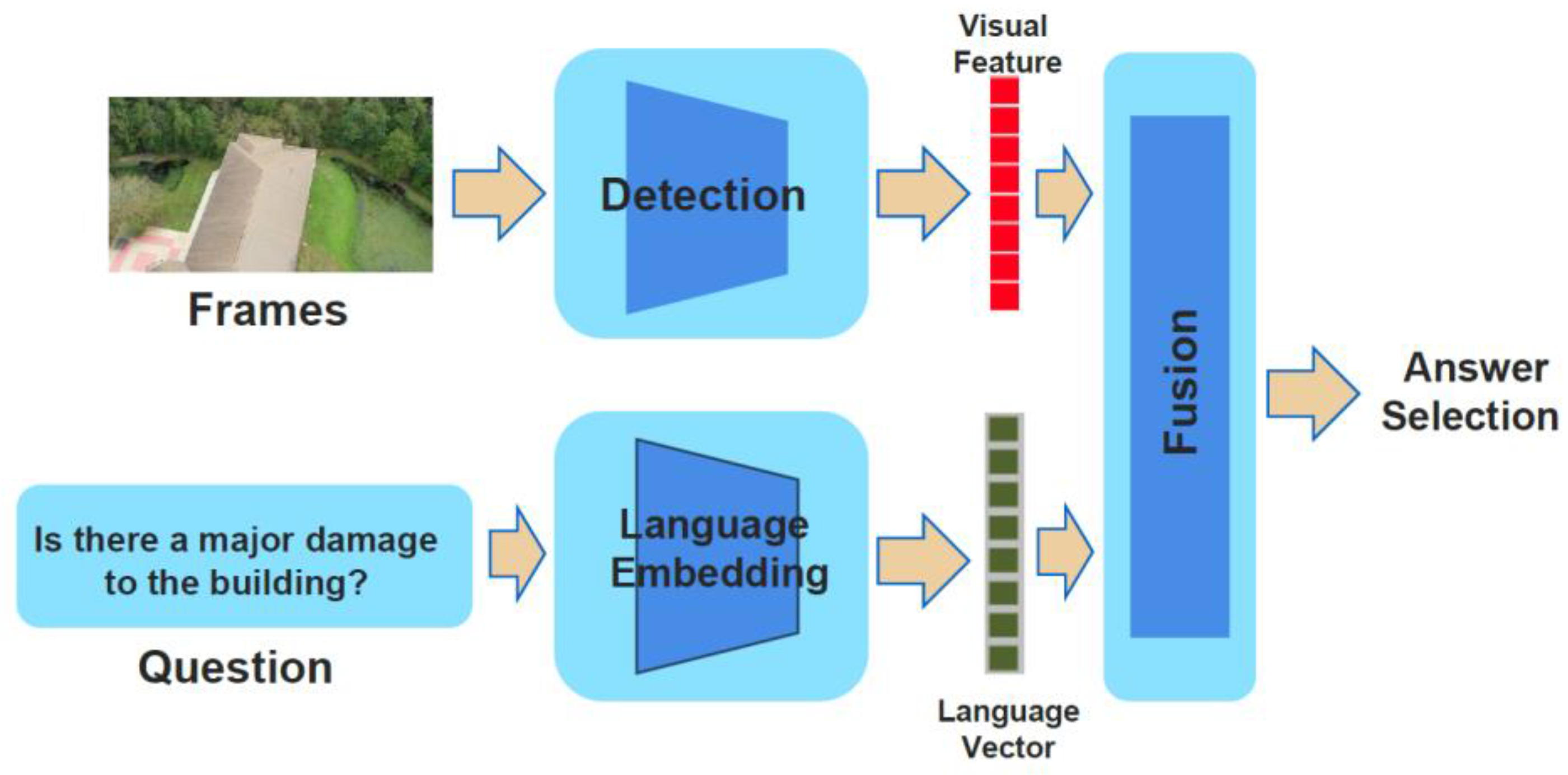
- Image Encoder: ResNet50
- Text Encoder: BiLSTM
- Image Encoder:
Vision Transformer,ViTMAE - Text Encoder:
RoBERTa base model
python train_vqa_basic_trainer.py \
--visual-pretrained "google/vit-base-patch16-224" \
--text-pretrained "roberta-base" \
--device "cuda:0"
| Models | Val acc | Test acc |
|---|---|---|
| ResNet50 + LSTM | 0.5358 | - |
| VisTrans + RoBERTa (pooler_output) | 0.6690 | 0.6636 |
| VisTrans + RoBERTa (last_hidden_state output) | 0.6931 | 0.6874 |
- Public models
- Inference code
- Compare with other models