A distributed massive data engine for vertical search in C++.
-
Flexible configuration. SF1R could be highly configurable to support either distributed or non-distributed search engine. For Asia languages, different kinds of morphlogical analyzer or dedicated tokenizer could be applied as well to be adapted to different situations. Each SF1R instance could be configured to support multiple collections, while the concept of collection could be compared with "Table" in
RDBMS. Collections could managed totally dynamically without stopping the server instance. -
Commercially proved . SF1R has been fully proved under commercial environments with both complicated situations and ultra high concurrency. In order to satisfy different kinds of requirements, three kinds of indices are supported within SF1R, including Lucene like file based inverted index, pure memory based inverted index with ultra high decompression performance, and succinct self index. This is a practical deployment for a search cloud with both distributed and non-distributed verticals, all of them are behind a single nginx based http reverse proxy to provide unified entry.
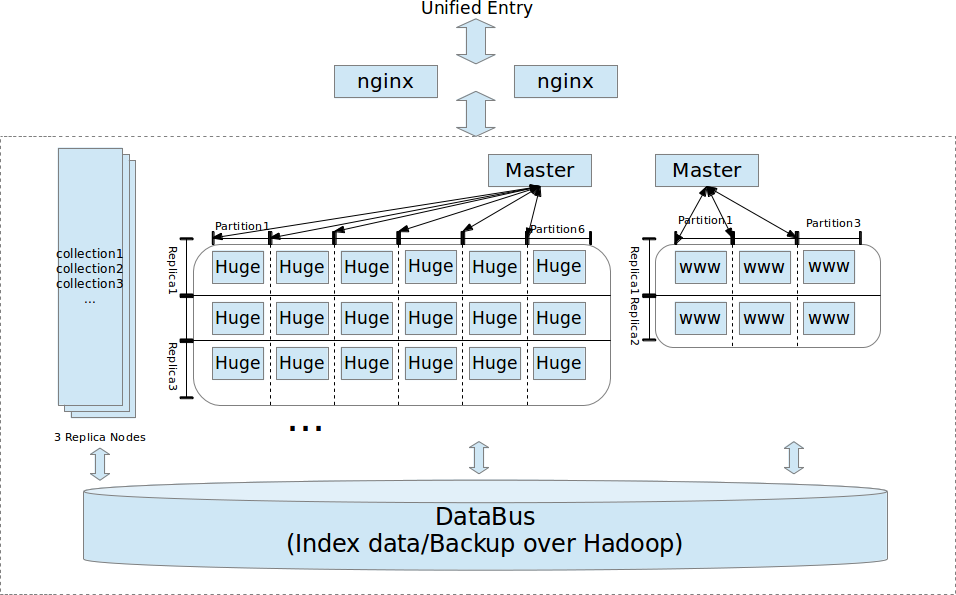
-
Mining components extendable. In the early stage of SF1R, there are tens of mining components attached, such as
duplicate detection,taxonomy generation,query recommendation,collaborative filtering,...,etc. To keep the repository as lite as possible, we made some refinements to remove most mining components. However, the architecture of SF1R has guaranteed the flexibility to introduce any of them, actually, one of index---succinct self index, it was encapsulated using mining component for conveniences.
The Chinese documents could be accessed here, while we also prepared the English technical report.
We've just switched to C++ 11 for SF1R recently, and GCC 4.8 is required to build SF1R correspondingly. We do not recommend to use Ubuntu for project building due to the nested references among lots of libraries. CentOS / Redhat / Gentoo / CoreOS are preferred platform. You also need CMake and Boost 1.56 to build the repository .Here are the dependent repositories list:
-
cmake: The cmake modules required to build all iZENECloud C++ projects.
-
izenelib: The general purpose C++ libraries.
-
icma: The Chinese morphological analyzer library.
-
ijma: The Japanese morphological analyzer library.
-
ilplib: The language processing libraries.
-
idmlib: The data mining libraries.
Besides, there are some third party repositores required:
-
Tokyocabinet: The tokyocabinet key-value library is seldomly used, but we had an unified access method encapsulation.
-
Google Glog: The logging library provided by Google.
-
Thrift: This is optional, if you want to have SF1R being able to connect to Cassandra, Thrift is required, and we have prepared C++
Cassandraclient in izenelib.
Additionally, there are two extra projects:
-
nginx: The nginx based reverse proxy for SF1R. This is the first nginx project to be able to connect with Zookeeper to get aware of SF1R's node topology.
-
Ruby driver: The ruby client for SF1R, also it contains a web API sender for testing purpose.
To use SF1R, you should have configuration files located in the config directory. After that:
$ cd bin
$ ./CobraProcess -F configPlease see the documents for further usage.
The SF1R project is published under the Apache License, Version 2.0: http://www.apache.org/licenses/LICENSE-2.0