{kind=link}
Source code and dataset for ACL 2018 paper: Document Dating using Graph Convolution Networks.
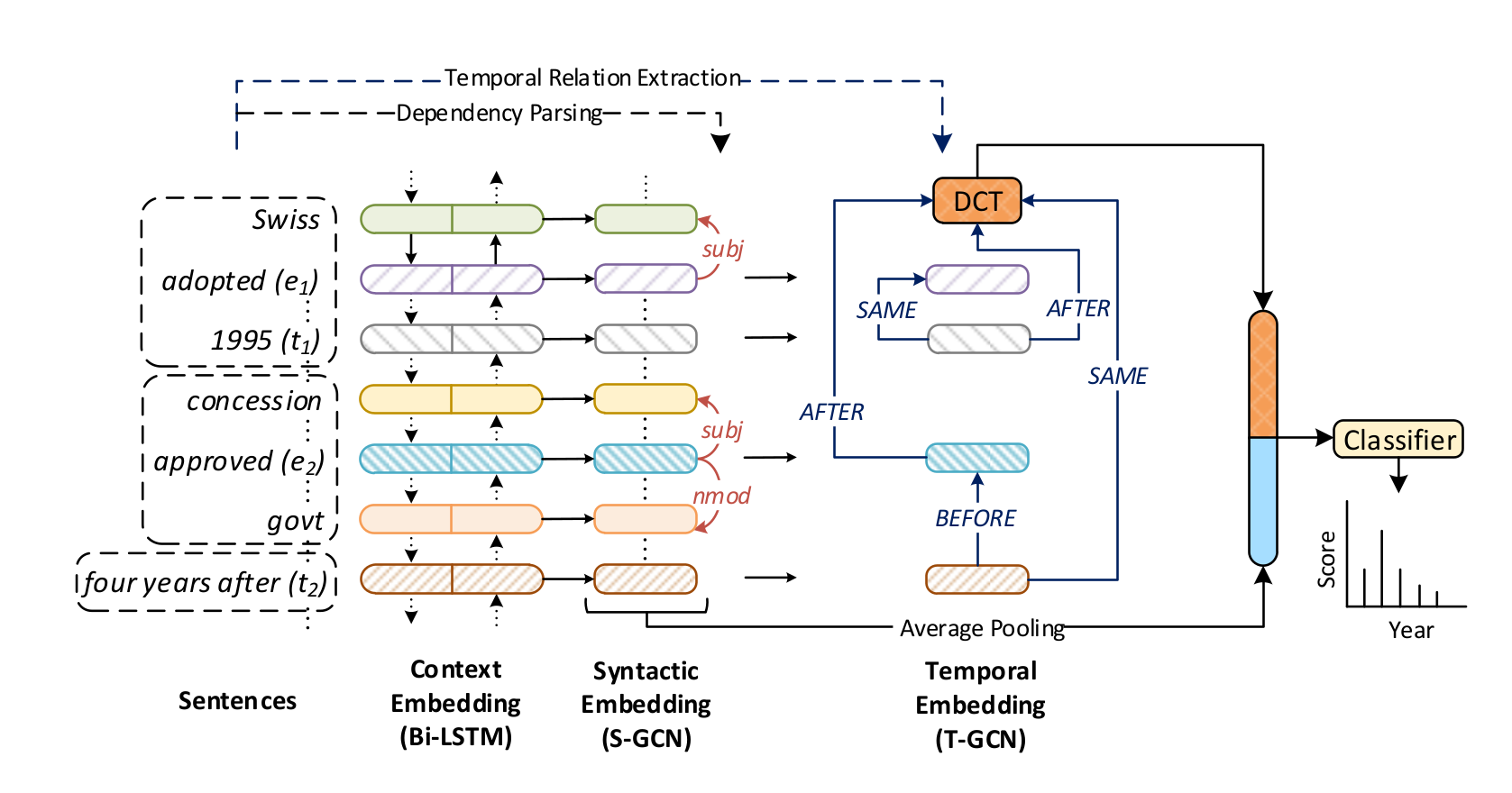 Overview of NeuralDater (proposed method). NeuralDater exploits syntactic and temporal structure in a document to learn effective representation, which in turn are used to predict the document time. NeuralDater uses a Bi-directional LSTM (Bi-LSTM), two Graph Convolution Networks (GCN) – one over the dependency tree and the other over the document’s temporal graph – along with a softmax classifier, all trained end-to-end jointly. Please refer paper for more details.
Overview of NeuralDater (proposed method). NeuralDater exploits syntactic and temporal structure in a document to learn effective representation, which in turn are used to predict the document time. NeuralDater uses a Bi-directional LSTM (Bi-LSTM), two Graph Convolution Networks (GCN) – one over the dependency tree and the other over the document’s temporal graph – along with a softmax classifier, all trained end-to-end jointly. Please refer paper for more details.
- Compatible with TensorFlow 1.x and Python 3.x.
- Dependencies can be installed using
requirements.txt.
-
Download the processed version (includes dependency and temporal graphs of each document) of NYT and APW datasets.
-
Unzip the
.pklfile indatadirectory. -
Documents are originally taken from NYT and APW section of Gigaword Corpus, 5th ed.
-
The structure of the processed input data is as follows.
{ "voc2id": {"w1": 0, "w2": 1, ...}, "et2id": {"NONE":0, "INCLUDES": 1, "BEFORE":2, "IS_INCLUDED":3 ...}, "de2id": {"subj":0, "obj":1, "conj":3 ...}, "train": { "X": [[s1_w1, s1_w2, ...], [s2_w1, s2_w2, ...], ...], "Y": [s1_time_stamp, s2_time_stamp, s3_time_stamp, ...], "DepEdges": [[s1_dep_edges], [s2_dep_edges] ...], "ETEdges": [[s1_et_edges], [s2_et_edges], ...], "ETIdx": [[s1_et1, s1_et2, ...], [s2_et1, s2_et2, ...], ...], "ET": [[s1_et1_type, s1_et2_type, ...], [s2_et1_type, s2_et2_type, ...], ...], } "test": {same as "train"}, "valid": {same as "train"} }voc2idis the mapping of words to their unique identifieret2idis the maping of temporal graph edge types to their unique identifier.de2idis the mapping of dependency graph edges types to their unique identifier.- Each entry of
train,testandvalidis a bag of sentences, whereXdenotes the list sentences as the list of list of word indices.Yis the time stamp associated with each sentence.DepEdgesis the edgelist of dependency parse for each sentence (required for S-GCN).ETEdgesis the edgelist of temporal graph for each sentence (required for T-GCN).ETIdxis the position indices of event/time_expression in each sentence.ETis the type of each word in a sentence.0denotes normal word,1event and2time expression.
For getting temporal graph of new documents. The following steps need to be followed:
-
Setup CAEVO and CATENA as explained in their respective repositories.
-
For extracting event and time mentions of a document
-
./runcaevoraw.sh <path_of_document> -
Above command generates an
.xmlfile. This is used by CATENA for extracting temporal graph and it also contains the dependency parse information of the document which can be extracted using the following command:python preprocess/read_caevo_out.py <caevo_out_path> <destination_path>
-
-
For making the generated
.xmlfile compatible for input to CATENA, use the following script aspython preprocess/make_catena_input.py <caevo_out_path> <destination_path>
-
.xmlgenerated above is given as input to CATENA for getting the temporal graph of the document.java -Xmx6G -jar ./target/CATENA-1.0.3.jar -i <path_to_xml> \ --tlinks ./data/TempEval3.TLINK.txt \ --clinks ./data/Causal-TimeBank.CLINK.txt \ -l ./models/CoNLL2009-ST-English-ALL.anna-3.3.lemmatizer.model \ -g ./models/CoNLL2009-ST-English-ALL.anna-3.3.postagger.model \ -p ./models/CoNLL2009-ST-English-ALL.anna-3.3.parser.model \ -x ./tools/TextPro2.0/ -d ./models/catena-event-dct.model \ -t ./models/catena-event-timex.model \ -e ./models/catena-event-event.model -c ./models/catena-causal-event-event.model > <destination_path>
The above command outputs the list of links in the temporal graph which are given as input to NeuralDater. The output file can be read using the following command:
python preprocess/read_catena_out.py <catena_out_path> <destination_path>
-
After installing python dependencies from
requirements.txt, executesh setup.shfor downloading GloVe embeddings. -
neural_dater.pycontains TensorFlow (1.x) based implementation of NeuralDater (proposed method). -
To start training:
python neural_dater.py -data data/nyt_processed_data.pkl -class 10 -name test_run
-classdenotes the number of classes in datasets,10for NYT and16for APW.-nameis arbitrary name for the run.
Please cite the following paper if you use this code in your work.
@InProceedings{neuraldater2018,
author = "Vashishth, Shikhar and Dasgupta, Shib Sankar and Ray, Swayambhu Nath and Talukdar, Partha",
title = "Dating Documents using Graph Convolution Networks",
booktitle = "Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
year = "2018",
publisher = "Association for Computational Linguistics",
pages = "1605--1615",
location = "Melbourne, Australia",
url = "http://aclweb.org/anthology/P18-1149"
}