Document is modified when opened/Markdown formatting #2189
Comments
|
Thanks for opening this topic. Since the discussion on this question so far has been, I think, fragmented, taking it into a central issue topic is extremely helpful. I think the core of the discussion is exactly the following:
It is useful to note that the the application might include support for rewriting the formatting elements (i.e. markup) of the document without doing so as a side effect of document editing. For example, in principle, a menu command might produce this effect, but only when manually invoked by the user (e.g. "Clean document formatting"). I am glad that it is considered a bug that unmodified document buffers are marked as modified. However, the unmodified document being marked as modified is simply a special case of unmodified parts of an edited document being modified in the raw file. A very common case for editing Markdown documents is changing part of a document, but desiring a resulting file as close as possible to the original, in terms of lines, words, and characters. For example, in this use, inserting a single word, through the editing buffer, in some existing paragraph, would have the sole effect of adding that word to the raw document. Reasons for needing this behavior include integration with revision tracking systems and inclusion of non-standard markup. I believe that this use, for whatever reasons in each case, is common enough that support for it is necessary for an editor to become a popular and reliable application within the Markdown community. Clearly, as observed, this functionality depends on a more sophisticated internal representation of the document. I am wondering though whether the functionality is possible through very minimal enhancements to the document tree. It would seem necessary only to include with each node the original string representation (or offset bounds of some static buffer). Following a change to some part of a document in the editing buffer, the node might be marked dirty, or the string cleared, for a new value to be generated when the document is saved. |
Thank you very much for the explanation. Now I understand some behaviors much better get a better idea how it works and why. I think this information is very important and should be available on a prominent place in the documentation, may even on the readme file. Knowing that you can understand marktext as an translator in well formatted markdown and use it this way. Don't knowing this you could be disappointed about marktext destroying content. |
this would also allow to make changes to the raw text visible, which is normally not possible in "normal" editors, but can be done in Word. For example when I get the message that the file has changed it would be possible to compare changes. |
|
I would also find it very helpful to keep ordered lists as a series of "1." rather than renumbering when opened in Mark Text |
|
Not sure if this is where to add this, but rather than open a new issue i'll comment here first: this is a list:
- item 1
- item 2
- item 3but the actual text file looks more like this: this is a list:
- item 1
- item 2
- item 3 |
This comment has been minimized.
This comment has been minimized.
|
(@axelsimon: Please see #2310.) |
|
Automatic formatting can be a great feature, but only if it is done on demand. Currently, has it is, it is more a problem than a feature for my use cases. For example, Mark Text is problematic with existing files that are managed under Git. You can't edit only the parts that need to be be edited. Mark Text Introduces extra unexpected, and unwanted changes. |
|
This issue is causing me many troubles, because of working on MD on GIT repos :( I tried to build the repo by myself with some of the workaround, but i failed. Maybe I will try again later.. |
|
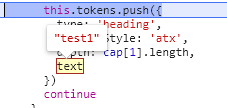
I take a glance at the code. The lexer paser implementation does not remain the source. After reviewing the code, This parsing algorithmn does not consider a minimum diff to preserve the source document The code is here: https://github.com/marktext/marktext/blob/develop/src/muya/lib/parser/marked/lexer.js#L117 for example while parsing // heading
cap = this.rules.heading.exec(src)
if (cap) {
src = src.substring(cap[0].length)
let text = cap[2] ? cap[2].trim() : ''
if (text.endsWith('#')) {
let trimmed = rtrim(text, '#')
if (this.options.pedantic) {
text = trimmed.trim()
} else if (!trimmed || trimmed.endsWith(' ')) {
// CommonMark requires space before trailing #s
text = trimmed.trim()
}
}
this.tokens.push({
type: 'heading',
headingStyle: 'atx',
depth: cap[1].length,
text
})
continue
}
😢 It seems like a big work to fix this issue... update Not Easy Work I think~ |

|
@ghostbody Then this editor is just another hipster's toy, not a real-life editor. |
|
@N0rbert Typora took the first place 😃 |
I think it is not productive to make general denouncements against the quality of the application. The difficulties with usability have been acknowledged by the project maintainers. No one is required to use the software in this project. Currently, the choices are to use MarkText, to use another editor instead, or to use none. If the choices are not suitable for your purposes, if you wish to see improvements in the project, then the most ethical and practical approach is to support the efforts of those contributing to it, if not to make a contribution yourself. Comments toward other purposes best should be given in other venues. |
|
Do we have any update about this issue? |
|
When I was looking forward to using marktext, the configuration information in pure English made me very difficult, and now there is an unsolvable and core user problem, and I feel a little lost. |
|
Still not fixed v0.17.1. |
|
At the moment this is the only thing that prevents me from using MarkText. |
|
I have to revert the changes cased by view manual before commit to git. |
|
One year passed, may any update about this issue? This problem makes it difficult for users to use. I like this project & hope it to greater. |
|
I use Obsidian as my primary markdown editor, and MarkText as secondary. MarkText keeps trying to change the format of my Obsidian markdown files, when I only want to use the application for quickly viewing markdown files within my file system explorer in Windows. Would it be possible to enable some kind of always-view-only mode to bypass this? I don't even need to edit any of the files within MarkText... |
|
Are there any updates on this? |
|
难以想象这个问题,从21年讨论到了23年也依旧还在,好久没有发布新版本了,不知道活跃度到底如何 |
|
Still happens with 0.17.1. |
|
I have switched to obsidian. |
|
@yunnysunny the same issue appears in Obsidian |
I have read the issue on obsidian, it's not the same problem. |
Overview
The goal of this issue is to clarify automatic markdown formatting, the modification notification without any document interaction and further steps to improve the situation.
The document is always formatted
Some would say this is a great feature and others don't. Mark Text formats all content according CommonMark and GFM (+other extensions if enabled). The reason for this is that we don't store the document as string with spaces etc but as block structure with minimal information. As a side effect, we need to build the text file when saving the document. In some situations, we don't know the formatting of the original document and apply the default style according markdown specification.
Why is my document modified after opened?
That's an issue with our data structure/flow and cursor positioning but will hopefully fix soon as we (@Jocs) refactor the data structure and get rid of the old data flow. This should also bring better performance and extension support the core of the editor.
Next steps
It's currently not planned to change the markdown formatting as it's built-in into the editor but as we continuously improve our engine, we'll keep this issue in mind and try our best to overwrite as little as possible. The removal of empty lines is currently not addressed as it would require a significant work to our markdown parser and data structure (#1354).
TODO's:
This is a non-exclusive list for improvements that require changes to the markdown parser, data structure and other parts of the core engine:
Please feel free to contribute on these issues. Any development will be tracked here.
The text was updated successfully, but these errors were encountered: