In this notebook I train 4 different NLP models for the detection of fake news from headlines:
- Bag of Words + Logistic Regression
- FastText Embeddings + CNN
- fine-tuned SMALL BERT (pre-trained model from the Tensorflow Hub)
- fine-tuned BERT (pre-trained model from Huggingface)
The dataset, containing news headlines, is collected from two news websites:
- TheOnion: sarcastic versions of current events (https://www.theonion.com/).
- HuffPost: real (and non-sarcastic) news headlines (https://www.huffpost.com/).
Each record consists of three attributes:
- is_sarcastic: 1 if the record is sarcastic (0 otherwise)
- headline: the headline of the news article
- article_link: link to the original news article. Useful in collecting supplementary data


- NLP
- Python
- Keras
- Tensorflow
- FastText Embedding
- Transformers
- Bert
- Huggingface
- Pandas
- Google Colab
I did a text pre-processing by doing the the following:
- Removing HTML characters
- Converting accented characters
- Fixing contractions
- Removing special characters
then I divided the data into train and test set.
Bag of Words (BOW) is an algorithm that transforms the text into fixed-length vectors. The algorithm counts the number of times the word is present in a document or, in this case, headline. The word occurrences allow to compare different headlines and evaluate their similarities. BOW represents the sentence as a bag of terms. It doesn’t take into account the order and the structure of the words, but it only checks if the words appear in the document.
Once I have the BOW vector for each headline, I use Logistic Regression to train and test the model for detecting fake news headines. Accuracy is around 83%, which is impressive already considering that BOW doesn't consider the order and structure of the words.

Fasttext embedding is a word to vector model: it represents each word as a vector. I used a pretrained model to generate, for each headline, a feature matrix, that is then used as input to a CNN model as shown in the picture. Accuracy is higher (85%) than with the previous model, but still not great.
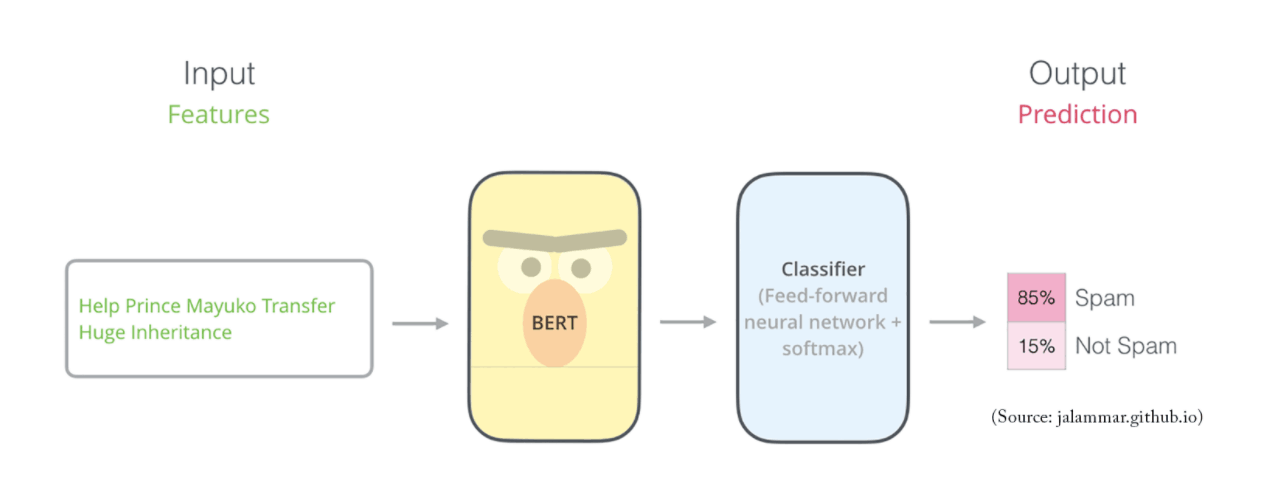
BERT is a family of masked-language models published in 2018 by researchers at Google. It has become a ubiquitous baseline in NLP experiments counting over 150 research publications analyzing and improving the model. SMALL BERT is a faster and ligher variation of BERT for quick training and deployment. It has only 2 encoders. I downloaded the pre-trained model from the Tensorflow Hub and fine-tuned it with my dataset. SMALL BERT seems to be too simple for this task: Accuracy is around 84%. Additional details on the model and its use can be found here: https://www.tensorflow.org/text/tutorials/classify_text_with_bert

{kind=link}
I used the pre-trained model from the Huggingface repository and has the following specs: 12-layer, 768-hidden, 12-heads, 110M parameters. Accuracy increases to 92%. Additional details on the model and its use can be found here: https://huggingface.co/bert-base-uncased.
Test set accuracy:
-
Bag of Words + Logistic Regression show pretty good results for a quick deployment (83% accuracy)
-
FastText Embeddings + CNN is also quick method and increases the accuracy to 85%
-
SMALL BERT doesn't perfom as well: 84% accuracy
-
Bert from HuggingFace has the best accuracy with 92%
- try other transformer-based models available from either the Tensorflow Hub or Huggingface
- try finetuning GPT-3