
demo.mp4
本代码仓库是适用于Automatic1111的 Wav2Lip UHQ扩展插件。
本插件为一体化集成解决方案:只需要一段视频和一段口播音频文件(wav或者mp3),就可以生成一个嘴唇同步的视频。通过Stable Diffusion特别的后处理技术,本插件所生成视频的嘴唇同步效果相比于Wav2Lip tool所生成的视频,有更好的质量。
- 🚀 更新
- 🔗 必要环境
- 💻 安装说明
- 🐍 使用方法
- 👄 关于bark的保真度说明
- 📺 样例
- 📖 后台原理
- 💪 提高质量的小提示
⚠️ 需要注意的约束- 📝 即将上线
- 😎 贡献
- 🙏 鸣谢
- 📝 引用
- 📜 版权声明
- ☕ 支持Wav2lip Studio
2023.09.13
- 👪 增加了 face swap 换脸: 整合了roop (参加下方使用方法章节) 本功能为实验性功能。
2023.08.22
- 👄 增加了 bark (参加下方使用方法章节), 本功能为实验性功能。
2023.08.20
- 🚢 增加了新的面部修复模型选择:GFPGAN。
- ▶ 增加了暂停/恢复功能。
- 📏 优化了释放内存方式,视频生成后会释放内存。
2023.08.17
- 🐛 修复嘴唇发紫的bug
2023.08.16
- ⚡ 除了generated版本的视频,额外输出Wav2lip和enhanced版本的视频,你可以从中选择效果更好的一个版本。
- 🚢 用户界面更新:增加了对CodeFormer Fidelity的控制说明。
- 👄 删除了图片输入方式,因为 SadTalker 的方法更好。
- 🐛 修复了输入和输出视频之间的差异导致遮罩蒙板位置不正确的bug。
- 💪 改进了处理流程,提高了效率。
- 🚫 如果程序在处理过程中,中段还会继续产出视频。
2023.08.13
- ⚡ 加快计算速度。
- 🚢 用户界面更新:添加了一些隐藏参数的设置。
- 👄 提供了“仅追踪嘴巴”的选项。
- 📰 控制debug。
- 🐛 修复了resize factor的bug。
- 最新版本的Stable Diffusion WebUI Automatic1111 Stable Diffusion Webui 。
- FFmpeg : 预先安装好FFmpeg,下载地址:FFmpeg官网。根据你的操作系统,按照官网说明安装好,注意,FFmpeg要加入环境变量设置,便于在任意目录调用。
- 启动Automatic1111
- Face Swap的环境依赖需要编译安装,所以在Windows中,需要安装 Visual Studio. 确保安装时,勾选Python开发环境和C++桌面开发环境包.
- 在扩展菜单里, 找到“从网址安装”标签,输入下方URL地址,点击“安装”:
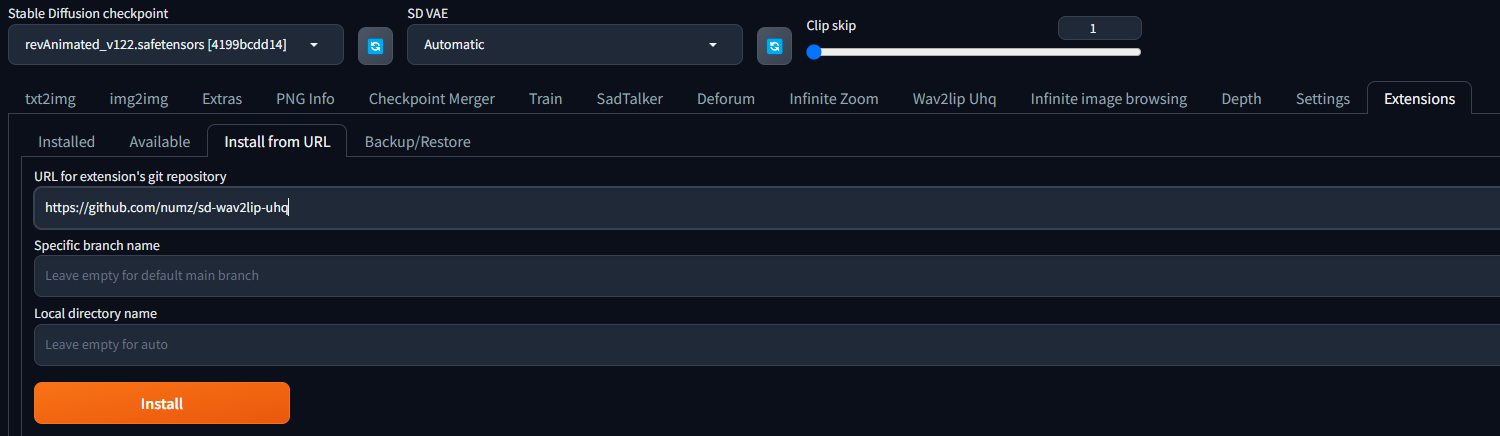
- 来到“已安装”标签,点击“应用并重启用户界面”.

-
如果您仍然看不到"Wav2Lip UHQ"的菜单,尝试重启Automatic1111.
-
🔥 十分重要: 必须要下载模型。从下方表格下载全部所需的模型。(要注意模型文件名,确保文件名正确无误,尤其是s3fd模型)。
| 模型 | 描述 | 地址 | 安装目录 |
|---|---|---|---|
| Wav2Lip | 高精度的唇同步 | Link | extensions\sd-wav2lip-uhq\scripts\wav2lip\checkpoints\ |
| Wav2Lip + GAN | 嘴唇同步稍差,但视觉质量更好 | Link | extensions\sd-wav2lip-uhq\scripts\wav2lip\checkpoints\ |
| s3fd | 人脸检测预训练模型 | Link | extensions\sd-wav2lip-uhq\scripts\wav2lip\face_detection\detection\sfd\s3fd.pth |
| landmark predicator | Dlib 68点人脸特征推测 (点击下载按钮) | Link | extensions\sd-wav2lip-uhq\scripts\wav2lip\predicator\shape_predictor_68_face_landmarks.dat |
| landmark predicator | Dlib 68点人脸特征推测 (备用地址1) | Link | extensions\sd-wav2lip-uhq\scripts\wav2lip\predicator\shape_predictor_68_face_landmarks.dat |
| landmark predicator | Dlib 68点人脸特征推测 (备用地址2,点击下载按钮) | Link | extensions\sd-wav2lip-uhq\scripts\wav2lip\predicator\shape_predictor_68_face_landmarks.dat |
| face swap model | face swap换脸所用模型 | Link | extensions\sd-wav2lip-uhq\scripts\faceswap\model\inswapper_128.onnx |
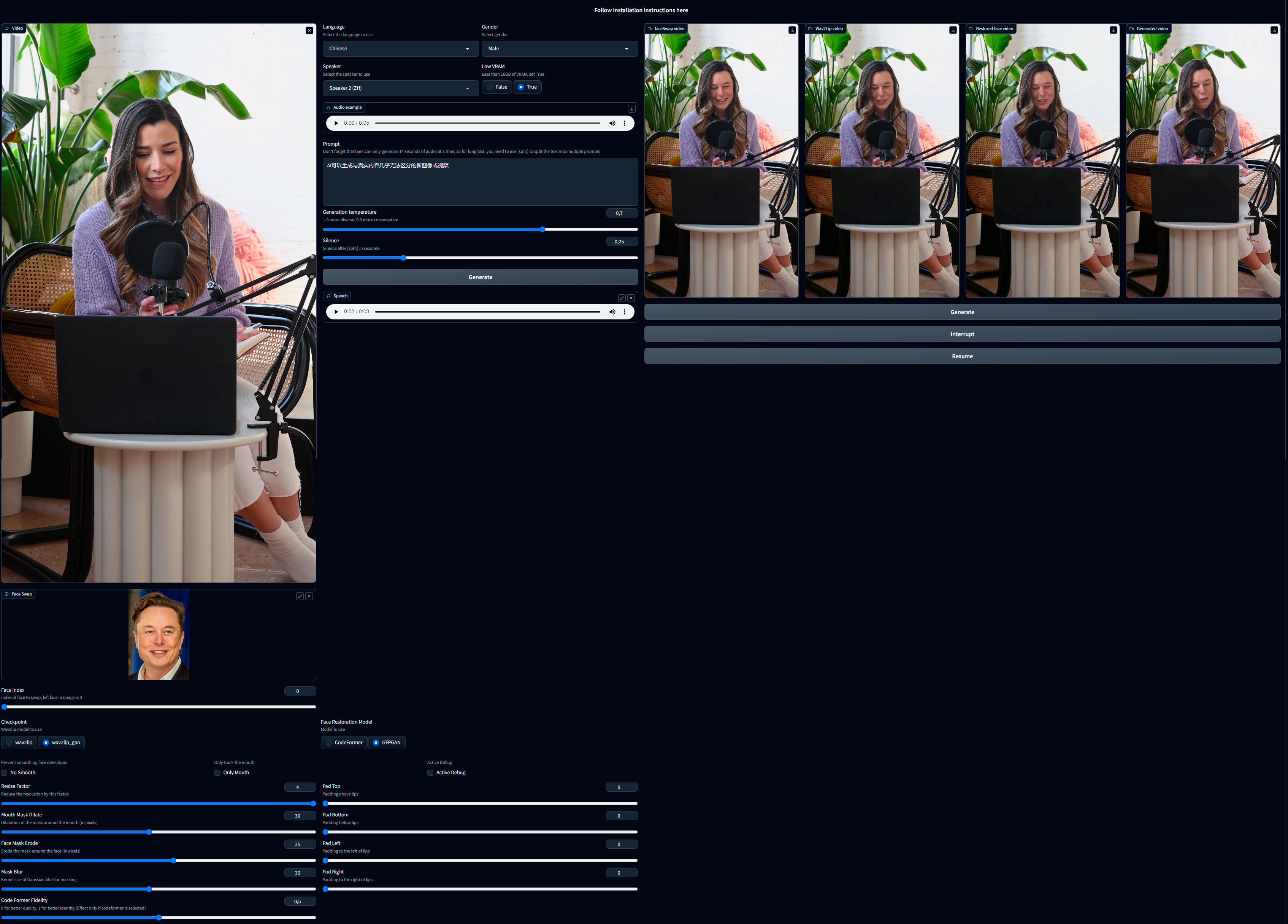
- 上传一个包含人脸的视频文件(avi格式或者mp4格式均可)。如果视频里没有人脸,哪怕只有一帧不包含人脸,会导致处理失败。请注意,如果你上传的是avi文件,在界面上你看不见它,但不用担心,插件会正常处理视频。
- 换脸 (耗时很长,需耐心等待):
- Face Swap: 选择一张照片用来替换视频里的脸。
- Face Index: 如果照片里有多张脸,可以指定其中一个,0 指的是从左到右数的第一个脸。
- 上传一个口播音频文件,现在音频的输入有两种方式:
- 跟原来一样,在音频输入区域上传口播音频文件。
- 用 bark 插件将文字转成口播语音.
- 选择语言 : 土耳其语, 英语, 汉语, 印地语, 意大利语, 日语, 韩语, 葡萄牙语, 俄语, 西班牙语, 波兰语, 德语, 法语
- 选择性别
- 选择朗读者, 你可以在 "Audio Example(声音样例)" 里试听
- 如果你的显卡内存低于16GB,勾选低显存为 True (默认选中)
- 将你需要朗读的文本填入 "Prompt" 区域
- 注意 bark生成的一句话只能在14秒以内,如果你的一句话比较长,需要用"[split]"进行分割。
- 例如,假如你一句话大约有30秒,你可以将你的文本写成这样:
- "这是前半段文字 [split] 这是后半段文字"
- Temperature: 靠近0.0接近原声, 靠近1.0让AI发挥创意, 但现实情况是but in reality, 0.0会感觉有点奇怪,1.0更原声相差甚远。bark设置了0.7为默认值,你可以自行微调以达到效果更佳。
- Silence(停顿) : 在遇到标点符号(。!!.??,)时的停顿时间. 默认值是0.25秒.
- 关于更多Bard的有关细节,可查看 Bark 文档 .
- 下列为已知一些支持的非说话的声音(但有时候没反应).
- [laughter] 大笑
- [laughs] 微笑
- [sighs] 叹气
- [music] 音乐
- [gasps] 喘气
- [clears throat] 清嗓
- "-" or ... 犹豫停顿
- ♪ 歌词
- 大写时用于强调
- 可以在提示词里单独写[MAN] 或者 [WOMAN]可无视朗读者的选择,将文本用指性别的朗读者
- 选择模型 (详见上方表格).
- Padding(填充位移): Wav2Lip用它来移动嘴巴位置。如果嘴巴位置不理想,可以用它来微调,通常情况下,不必刻意调整。
- No Smooth(不要平滑): 当勾选该选项,将会保持原始嘴部形状不做平滑处理。
- Resize Factor(调整大小): 该选项会对视频的分辨率进行调整。默认值是1,如果你需要降低你的视频分辨率,你可以调整它。
- Only Mouth(仅追踪嘴巴): 选中该选项,将仅对嘴部进行追踪,这将会移除例如脸颊和下巴的动作。
- Mouth Mask Dilate(嘴部遮罩蒙板扩张): 该选项用于调整嘴巴覆盖区域,参数越大,覆盖面积越大,根据嘴巴的大小来作出调整。
- Face Mask Erode(面部遮罩蒙板侵蚀): 对脸部外延区域进行渗透侵蚀处理,根据脸型大小作出调整。
- Mask Blur(遮罩模糊): 通过对遮罩层进行模糊处理,使其变得更平滑,建议尽量使该参数小于等于 Mouth Mask Dilate(嘴部遮罩蒙板扩张) 参数.
- Code Former Fidelity(Code Former保真度):
- 当该参数偏向0时,虽然有更高的画质,但可能会引起人物外观特征改变,以及画面闪烁。
- 当该参数偏向1时,虽然降低了画质,但是能更大程度的保留原来人物的外观特征,以及降低画面闪烁。
- 不建议该参数低于0.5。为了达到良好的效果,建议在0.75左右进行调整。
- Active debug(启用debug模式): 开启该选项,将会在debug目录里逐步执行来生成图片。
- 点击“Generate”(生成)按钮。
| 链接 | 语言 |
|---|---|
| 哔哩哔哩 | 中文 |
| 抖音 | 中文 |
| Youtube | 中文 |
Bark十分有趣,但它有时候输出的声音十分奇怪(甚至有点搞笑)。每次生成的结果都有些许不同,你可能需要多生成几次以达到你想要的结果。 除了英语,其他语言的采样似乎并非来自本土母语,听起来有点像外国人在说话。有时候选男,但听起来有点像女,反之亦然。甚至有时候当你选了某一个声音,但听起来像另外一个声音或者另一种语音。
deforum_wav2lip.mp4
deforum_wav2lip_en.mp4
real_person_ch.mp4
FaceSwap.mp4
本扩展分几个流程运行,以此达到提高Wav2Lip生成的视频的质量的效果:
- Generate face swap video: 如果face swap提供了需要替换脸部的图片,那会先将原始视频进行脸部替换,该操作耗时很长,需耐心等待。
- Generate a Wav2lip video(生成Wav2lip视频): 该脚本先使用输入的视频和音频生成低质量的Wav2Lip视频。
- Video Quality Enhancement(视频质量增强): 根据用户选择的面部修复模型来将低清视频转化成高清的视频。
- Mask Creation(创建遮罩蒙板): 该脚本在嘴巴周围制作了一个遮罩蒙板,并试图保持其他面部动作,比如脸颊和下巴的动作。
- Video Generation(生成视频)*: 该脚本会获取高质量的嘴巴图像,并将其覆盖在由嘴部遮罩引导的原始图像上。
- Video Post Processing(后期合成): 该脚本调用ffmpeg生成最终版本的视频。
- 使用高质量的视频作为输入源
- 使用常见FPS(譬如24fps、25fps、30fps、60fps)的视频,如果不是常见的FPS,偶尔会出现一些问题,譬如面部遮罩蒙板处理。
- 使用高质量的音频源文件,不要有音乐,不要有背景白噪声。使用类似 https://podcast.adobe.com/enhance 的工具清除背景音乐。
- 扩大嘴部遮罩蒙板范围。这将有助于模型保留一些面部动作,并盖住原来的嘴巴。
- “遮罩模糊”(Mask Blur)的最大值是“嘴部遮罩蒙板扩张”(Mouth Mask Dilate)值的两倍。如果要增加模糊度,请增加“嘴部遮罩蒙板扩张”的值,否则嘴巴将变得模糊,并且可以看到下面的嘴巴。
- 高清放大有利于提高质量,尤其是在嘴巴周围。但是,它将使处理时间变长。你可以参考Olivio Sarikas的教程来高清放大处理你的视频: https://www.youtube.com/watch?v=3z4MKUqFEUk. 确保去噪强度设置在0.0和0.05之间,选择“revAnimated”模型,并使用批处理模式。回头我再补个简单的教程说明。
- 确保视频的每一帧上都有一张脸。如果未检测到人脸,插件将停止运行。
- 目前的模型对胡须并不友好.
- 如果初始化阶段过长,请考虑使用调整“Resize Factor”来减小视频分辨率的大小。
- 虽然对原始视频没有严格的大小限制,但较大的视频需要更多的处理时间。建议使用“调整大小因子”来最小化视频大小,然后在处理完成后升级视频。
- Mac用户: dlib会报无法安装,在requirements.txt文件里,找到”dlib-bin“,并将其替换成"dlib"
- 教程指引
- 将avi转mp4(目前avi文件在输入框不显示,但依然能正常工作)
- 可用视频文件作为音频的输入
- 独立版本
- ComfyUI 插件
我们欢迎各位对本项目的贡献提交。提交合并提取请求(Pull requests)时,请提供更改的详细说明。 详参 CONTRIBUTING 。
该项目是开源项目,可以免费使用和修改。项目的持续改进,依靠用户的支持。如果您喜欢本项目,愿意支持我,可以在我的Patreon页面上捐款。捐献无论大小,我们都将不胜感激!
您的捐献将帮助我分担了开发和维护的成本,并让我能够分配更多的时间和资源来增强这个项目。感谢您的支持!
如果您在工作、发表文章、教程或演示中使用到了项目,我们非常鼓励您引用此项目。
如需引证本项目,请考虑使用如下BibTeX格式:
@misc{wav2lip_uhq,
author = {numz},
title = {Wav2Lip UHQ},
year = {2023},
howpublished = {GitHub repository},
publisher = {numz},
url = {https://github.com/numz/sd-wav2lip-uhq}
}
- 此代码仓库中的代码是根据MIT许可协议发布的。 LICENSE file.