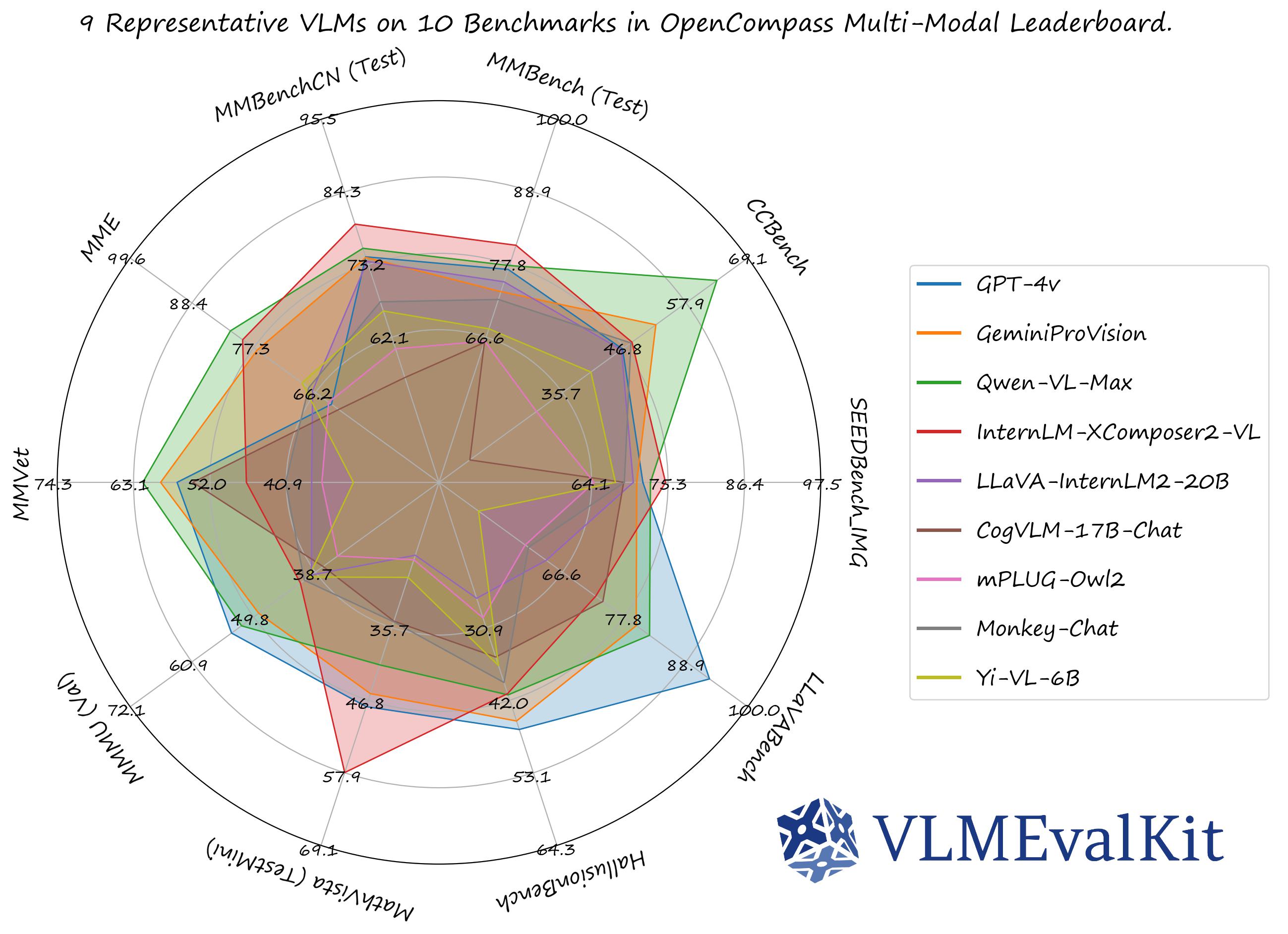
VLMEvalKit (the python package name is vlmeval) is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.
- [2024-05-07] We have supported XVERSE-V-13B, thanks to YJY123 🔥🔥🔥
- [2024-05-06] We have launched a discord channel for VLMEvalKit users: https://discord.gg/evDT4GZmxN. Latest updates and discussion will be posted here
- [2024-05-06] We have supported 2 VLMs based on Llama3 🔥🔥🔥: Bunny-llama3-8B (SigLIP, image size 384) and llava-llama-3-8b (CLIP-L, image size 336), you can now evaluate both models on dozens of datasets we supported
- [2024-04-28] We have supported MMBench V1.1, the new version has better data quality and improved vision indispensability. To obtain the test-set performance, please submit the inference result to the evaluation service 🔥🔥🔥
- [2024-04-28] We have supported POPE, a benchmark for object hallucination evaluation 🔥🔥🔥
- [2024-04-25] We have supported Reka API, the API model ranked first in Vision-Arena 🔥🔥🔥
- [2024-04-21] We have noticed a minor issue with the MathVista evaluation script (which may negatively affect the performance). We have fixed it and updated the leaderboard accordingly
- [2024-04-17] We have supported InternVL-Chat-V1.5 🔥🔥🔥
- [2024-04-15] We have supported RealWorldQA, a multimodal benchmark for real-world spatial understanding 🔥🔥🔥
- [2024-04-09] We have refactored the inference interface of VLMs to a more unified version, check #140 for more details
The performance numbers on our official multi-modal leaderboards can be downloaded from here!
OpenVLM Leaderboard: Download All DETAILED Results.
Supported Dataset
- By default, all evaluation results are presented in OpenVLM Leaderboard.
| Dataset | Dataset Names (for run.py) | Task | Dataset | Dataset Names (for run.py) | Task |
|---|---|---|---|---|---|
| MMBench Series: MMBench, MMBench-CN, CCBench |
MMBench_DEV_[EN/CN] MMBench_TEST_[EN/CN] MMBench_DEV_[EN/CN]V11 MMBench_TEST[EN/CN]_V11 CCBench |
Multi-choice Question (MCQ) |
MMStar | MMStar | MCQ |
| MME | MME | Yes or No (Y/N) | SEEDBench_IMG | SEEDBench_IMG | MCQ |
| MM-Vet | MMVet | VQA | MMMU | MMMU_DEV_VAL/MMMU_TEST | MCQ |
| MathVista | MathVista_MINI | VQA | ScienceQA_IMG | ScienceQA_[VAL/TEST] | MCQ |
| COCO Caption | COCO_VAL | Caption | HallusionBench | HallusionBench | Y/N |
| OCRVQA* | OCRVQA_[TESTCORE/TEST] | VQA | TextVQA* | TextVQA_VAL | VQA |
| ChartQA* | ChartQA_TEST | VQA | AI2D | AI2D_TEST | MCQ |
| LLaVABench | LLaVABench | VQA | DocVQA+ | DocVQA_[VAL/TEST] | VQA |
| InfoVQA+ | InfoVQA_[VAL/TEST] | VQA | OCRBench | OCRBench | VQA |
| RealWorldQA | RealWorldQA | MCQ | POPE+ | POPE | Y/N |
| Core-MM- | CORE_MM | VQA |
* We only provide a subset of the evaluation results, since some VLMs do not yield reasonable results under the zero-shot setting
+ The evaluation results are not available yet
- Only inference is supported in VLMEvalKit
VLMEvalKit will use an judge LLM to extract answer from the output if you set the key, otherwise it uses the exact matching mode (find "Yes", "No", "A", "B", "C"... in the output strings). The exact matching can only be applied to the Yes-or-No tasks and the Multi-choice tasks.
Supported API Models
| GPT-4V (20231106, 20240409)🎞️🚅 | GeminiProVision🎞️🚅 | QwenVLPlus🎞️🚅 | QwenVLMax🎞️🚅 | Step-1V🎞️🚅 |
|---|---|---|---|---|
| Reka🚅 |
Supported PyTorch / HF Models
🎞️: Support multiple images as inputs.
🚅: Model can be used without any additional configuration / operation.
Transformers Version Recommendation:
Note that some VLMs may not be able to run under certain transformer versions, we recommend the following settings to evaluate each VLM:
- Please use
transformers==4.33.0for:Qwen series,Monkey series,InternLM-XComposer Series,mPLUG-Owl2,OpenFlamingo v2,IDEFICS series,VisualGLM,MMAlaya,SharedCaptioner,MiniGPT-4 series,InstructBLIP series,PandaGPT,VXVERSE. - Please use
transformers==4.37.0for:LLaVA series,ShareGPT4V series,TransCore-M,LLaVA (XTuner),CogVLM Series,EMU2 Series,Yi-VL Series,MiniCPM-V series,OmniLMM-12B,DeepSeek-VL series,InternVL series. - Please use
transformers==4.39.0for:LLaVA-Next series. - Please use
transformers==4.40.0for:IDEFICS2,Bunny-Llama3.
# Demo
from vlmeval.config import supported_VLM
model = supported_VLM['idefics_9b_instruct']()
# Forward Single Image
ret = model.generate(['assets/apple.jpg', 'What is in this image?'])
print(ret) # The image features a red apple with a leaf on it.
# Forward Multiple Images
ret = model.generate(['assets/apple.jpg', 'assets/apple.jpg', 'How many apples are there in the provided images? '])
print(ret) # There are two apples in the provided images.See QuickStart for a quick start guide.
To develop custom benchmarks, VLMs, or simply contribute other codes to VLMEvalKit, please refer to Development_Guide.
The codebase is designed to:
- Provide an easy-to-use, opensource evaluation toolkit to make it convenient for researchers & developers to evaluate existing LVLMs and make evaluation results easy to reproduce.
- Make it easy for VLM developers to evaluate their own models. To evaluate the VLM on multiple supported benchmarks, one just need to implement a single
generate_inner()function, all other workloads (data downloading, data preprocessing, prediction inference, metric calculation) are handled by the codebase.
The codebase is not designed to:
- Reproduce the exact accuracy number reported in the original papers of all 3rd party benchmarks. The reason can be two-fold:
- VLMEvalKit uses generation-based evaluation for all VLMs (and optionally with LLM-based answer extraction). Meanwhile, some benchmarks may use different approaches (SEEDBench uses PPL-based evaluation, eg.). For those benchmarks, we compare both scores in the corresponding result. We encourage developers to support other evaluation paradigms in the codebase.
- By default, we use the same prompt template for all VLMs to evaluate on a benchmark. Meanwhile, some VLMs may have their specific prompt templates (some may not covered by the codebase at this time). We encourage VLM developers to implement their own prompt template in VLMEvalKit, if that is not covered currently. That will help to improve the reproducibility.
If you use VLMEvalKit in your research or wish to refer to the published OpenSource evaluation results, please use the following BibTeX entry and the BibTex entry corresponding to the specific VLM / benchmark you used.
@misc{2023opencompass,
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
author={OpenCompass Contributors},
howpublished = {\url{https://github.com/open-compass/opencompass}},
year={2023}
}- opencompass: An LLM evaluation platform, supporting a wide range of models (LLaMA, LLaMa2, ChatGLM2, ChatGPT, Claude, etc) over 50+ datasets.
- MMBench: Official Repo of "MMBench: Is Your Multi-modal Model an All-around Player?"
- BotChat: Evaluating LLMs' multi-round chatting capability.
- LawBench: Benchmarking Legal Knowledge of Large Language Models.
- Ada-LEval: Length Adaptive Evaluation, measures the long-context modeling capability of language models.