![]()
This project is an example that how to implement FastAPI and the pydiator-core. You can see the detail of the pydiator-core on this link https://github.com/ozgurkara/pydiator-core
uvicorn main:app --reload
or docker-compose up
coverage run --source app/ -m pytest
coverage report -m
coverage html
You can see details here https://github.com/ozgurkara/pydiator-core
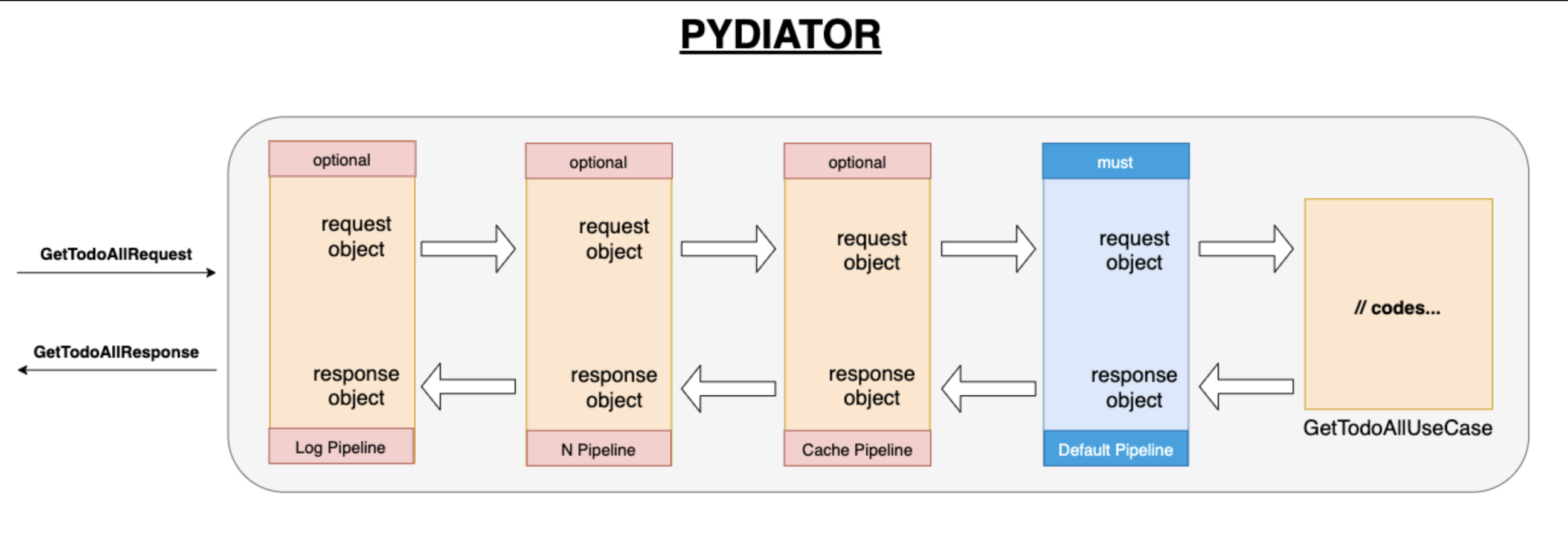
This architecture;
- Testable
- Use case oriented
- Has aspect programming (Authorization, Validation, Cache, Logging, Tracer etc.) support
- Clean architecture
- SOLID principles
- Has publisher subscriber infrastructure
There are ready implementations;
- Redis cache
- Swagger (http://0.0.0.0:8080)
Add New Use Case
#resources/sample/get_sample_by_id.py
class GetSampleByIdRequest(BaseRequest):
def __init__(self, id: int):
self.id = id
class GetSampleByIdResponse(BaseResponse):
def __init__(self, id: int, title: str):
self.id = id
self.title = title
class GetSampleByIdUseCase(BaseHandler):
async def handle(self, req: GetSampleByIdRequest):
# related codes are here such as business
return GetSampleByIdResponse(id=req.id, title="hello pydiatr") Register Use Case
# utils/pydiator/pydiator_core_config.py set_up_pydiator
container.register_request(GetSampleByIdRequest, GetSampleByIdUseCase())Calling Use Case;
await pydiator.send(GetSampleByIdRequest(id=1))You can think that the pipeline is middleware for use cases. So, all pipelines are called with the sequence for every use case. You can obtain more features via pipeline such as cache, tracing, log, retry mechanism, authorization. You should know and be careful that if you register a pipeline, it runs for every use case calling.
Add New Pipeline
class SamplePipeline(BasePipeline):
def __init__(self):
pass
async def handle(self, req: BaseRequest) -> object:
# before executed pipeline and use case
response = await self.next().handle(req)
# after executed next pipeline and use case
return response Register Pipeline
# utils/pydiator/pydiator_core_config.py set_up_pydiator
container.register_pipeline(SamplePipeline())The notification feature provides you the pub-sub pattern as ready.
The notification is being used for example in this repository. We want to trigger 2 things if the todo item is added or deleted or updated;
1- We want to clear the to-do list cache.
2- We want to write the id information of the to-do item to console
Add New Notification
class TodoTransactionNotification(BaseModel, BaseNotification):
id: int = Field(0, gt=0, title="todo id")Add Subscriber
class TodoClearCacheSubscriber(BaseNotificationHandler):
def __init__(self):
self.cache_provider = get_cache_provider()
async def handle(self, notification: TodoTransactionNotification):
self.cache_provider.delete(GetTodoAllRequest().get_cache_key())
class TransactionLogSubscriber(BaseNotificationHandler):
def __init__(self):
self.cache_provider = get_cache_provider()
async def handle(self, notification: TodoTransactionNotification):
print(f'the transaction completed. its id {notification.id}')Register Notification
container.register_notification(TodoTransactionNotification,
[TodoClearCacheSubscriber(), TransactionLogSubscriber()])Calling Notification
await pydiator.publish(TodoTransactionNotification(id=1))The cache pipeline decides that put to cache or not via the request model. If the request model inherits from the BaseCacheable object, this use case response can be cacheable.
If the cache already exists, the cache pipeline returns with cache data so, the use case is not called. Otherwise, the use case is called and the response of the use case is added to cache on the cache pipeline.
class GetTodoAllRequest(BaseModel, BaseRequest, BaseCacheable):
# cache key.
def get_cache_key(self) -> str:
return type(self).__name__ # it is cache key
# cache duration value as second
def get_cache_duration(self) -> int:
return 600
# cache location type
def get_cache_type(self) -> CacheType:
return CacheType.DISTRIBUTEDRequirements;
1- Must have a redis and should be set the below environment variables
REDIS_HOST = 'redis ip'
2- Must be activated the below environment variables on the config for using the cache;
DISTRIBUTED_CACHE_IS_ENABLED=True
CACHE_PIPELINE_IS_ENABLED=True