✨ [UPDATE]: Fine-tuned LLama2 with QLoRA will be added soon!
This project aims to generate a title from the given abstract for academic articles. Models were fine tuned with PEFT using the ArXiv dataset. Two different models were tuned with LoRA (Hu et al., 2021). Only articles in the computer science category were selected in the ArXiv dataset. This number has also been reduced due to memory and time limits. The fine-tuned models are available via HuggingFace spaces:
The project includes:
- Low Rank Adaptation Method (LoRA)
- Parameter Efficient Fine Tuning (PEFT)
- HuggingFace model trainings (T5-base, BART-base)
- Evaluation metric of
Rouge Score - One-shot, zero-shot evaluation and addition of instruction prompt
- Model merging and uploading to HuggingFace
- Tracking logs, memory usage, elapsed time for preprocessing, training, evaluation processes, visualization of training/testing loss
- EDA and script for filtering the ArXiv dataset with only Computer Science (CS) articles.
- Filtering and converting .json dataset to .csv format
External libraries and packages:
- Torch
- HuggingFace
- Transformers
- BitsAndBytes
- PEFT
- Accelerate
- Evaluate (Rouge score)
- LoraLib
- Trl
- Pandas, NumPy, Matplotlib, tqdm, time
Training Parameters and Limitations
- 6000 training samples, 1000 validation samples, 250 test samples are filtered from the dataset.
- (Number of CS related papers is 299131. However, one of the aims of this project is check the efficiency of small LLMs with PEFT/LORA. Therefore, the less training data samples and less training epochs are considered.)
- Models are trained for 6 epochs.
- Lora attention
R=8,alpha=64,dropout=0.01,learning rate=2e-4,paged_adamW_32bit optimizer
- Memory Cached: 11.2 GB
- Training time: 11423.89 s
- Memory Cached: 13.7 GB
- Training time: 9793.74 s
| Original Title | Generated Title | |
|---|---|---|
| 1 | Quantum circuits for strongly correlated quantum systems | Quantum Simulation of strongly correlated Many-Body Hamiltonians |
| 2 | TeKo: Text-Rich Graph Neural Networks with External Knowledge | Text-rich Graph Neural Networks with External Knowledge |
| 3 | CARGO: Effective format-free compressed storage of genomic information | CARGO: Compressed ARchiving for GenOmics |
| 4 | Energy-Efficient Power Control of Train-ground mmWave Communication for | Energy Efficiency of train-ground mmWave communication for high speed trains |
| 5 | A survey on bias in machine learning research | Understanding the sources and consequences of bias in machine learning |
| 6 | SA-UNet: Spatial Attention U-Net for Retinal Vessel Segmentation | Spatial Attention U-Net: Spatial Attention for Eye-related Diseases |
| 7 | A new heuristic algorithm for fast k-segmentation | A novel heuristic algorithm for k-segmentation |
| 8 | Progression and Challenges of IoT in Healthcare: A Short Review | Smart Healthcare and Healthcare: A Comparative Analysis of Smart Healthcare and Security |
| 9 | FVC: A New Framework towards Deep Video Compression in Feature Space | Feature-space Video Compression for Learning Based Video Coding |
-
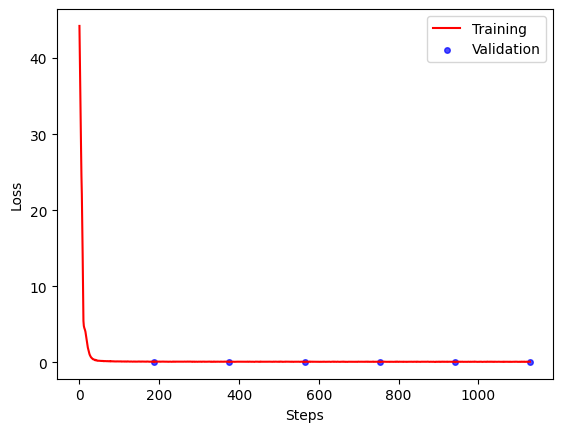
BART Training/Testing Loss (6 epochs)
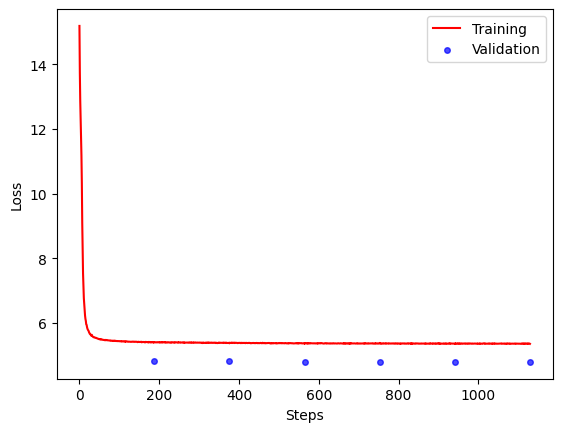
-
T5 Training/Testing Loss (6 epochs)