Before (or after) diving into the code, if you want to understand the context behind this project, see READMEQuant.md
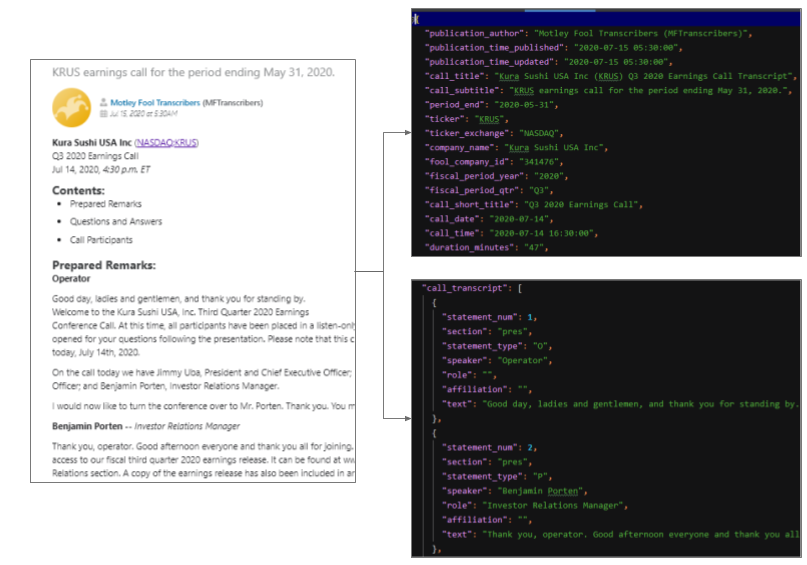
scrapers.py provides functions that scrape and structure individual transcripts
sync_downloads.py and sync_scrapes.py are wrappers that queue a series of transcript-events, keeping local/cloud directories in sync with fool.com
- Supports local or S3 file-store (see
outputpathinput parameter) - Supports multiprocessing (see parameter in
config.py) - Polite, under-the-radar scraping (i.e. various throttles and perameters available in
config.py)
self-contained scraping functions that can be imported (or called via cli) to process individual events (transcripts)
foolcalls/examples/module_usage.py
scrape a specific url:
import requests
from foolcalls.scrapers import scrape_transcript_urls_by_page, scrape_transcript
transcript_url = 'https://www.fool.com/earnings/call-transcripts/' \
'2020/07/15/kura-sushi-usa-inc-krus-q3-2020-earnings-call-tran.aspx'
response = requests.get(transcript_url)
transcript = scrape_transcript(response.text)
print(json.dumps(transcript, indent=2))get a handful of transcripts from fool.com
import requests
from foolcalls.scrapers import scrape_transcript_urls_by_page, scrape_transcript
num_of_pages = 3
output = []
for page in range(0, num_of_pages): # for a given page...
transcript_urls = scrape_transcript_urls_by_page(page) # get list of transcripts on that page
for transcript_url in transcript_urls: # for each transcript in the list
response = requests.get(transcript_url) # get the raw html
transcript = scrape_transcript(response.text) # structure its contents into a dictionary
output.append(transcript)
time.sleep(5) # sleep 5 seconds between reqeusts
print(json.dumps(transcript, indent=2))- Crawl & Download w/
sync_downloader.py- keeping transcripts on fool.com in sync with your local or s3 filestores - Scrape & Structure w/
sync_scrapers.py- structuring individual raw html file into a consistently structured JSON
invoke/queue a series of events (transcripts), keeping local/cloud directories in sync with fool.com
foolcalls/sync_downloads.py
usage: sync_downloads.py [-h] [--scraper_callback] [--overwrite] outputpath
Download raw html files of earnings call transcripts from fool.com
positional arguments:
outputpath where to send output on local machine; if outputpath=='s3', output is
uploaded to the Aws.OUPUT_BUCKET variable defined in config.py
optional arguments:
-h, --help show this help message and exit
--scraper_callback whether to invoke the transcript scraper immediately after a file is
downloaded; otherwise scraping can be run as a separate batch process
--overwrite overwrite transcripts that have already been downloaded to specified <outputpath>; o
therwise it's an update (i.e. only download new transcripts)
S3 naming convention: <config.Aws.OUPUT_BUCKET>/state=downloaded/rundate=20200711/cid=*.gz
Local naming convention: ./output/state=downloaded/rundate=20200711/cid=*.gz
foolcalls/sync_scrapes.py
usage: sync_scrapes.py [-h] [--overwrite] outputpath
scrape the contents of a call from a
positional arguments:
outputpath where to send output on local machine; if outputpath=='s3', output is uploaded to the Aws.OUPUT_BUCKET variable defined in config.py
optional arguments:
-h, --help show this help message and exit
--overwrite Overwrite holdings that have already been downloaded to S3
S3 naming convention: <config.Aws.OUPUT_BUCKET>/state=structured/version=202007.1/cid=*.json
Local naming convention: ./output/state=structured/version=202007.1/cid=*.json