This project provides users the ability to do paraphrase generation for sentences through a clean and simple API. A demo can be seen here: pair-a-phrase
The paraphraser was developed under the Insight Data Science Artificial Intelligence program.
The underlying model is a bidirectional LSTM encoder and LSTM decoder with attention trained using Tensorflow. Downloadable link here: paraphrase model
- python 3.5
- Tensorflow 1.4.1
- spacy
Download the model checkpoint from the link above and run:
python inference.py --checkpoint=<checkpoint_path/model-171856>
The dataset used to train this model is an aggregation of many different public datasets. To name a few:
- para-nmt-5m
- Quora question pair
- SNLI
- Semeval
- And more!
I have not included the aggregated dataset as part of this repo. If you're curious and would like to know more, contact me. Pretrained embeddings come from John Wieting's para-nmt-50m project.
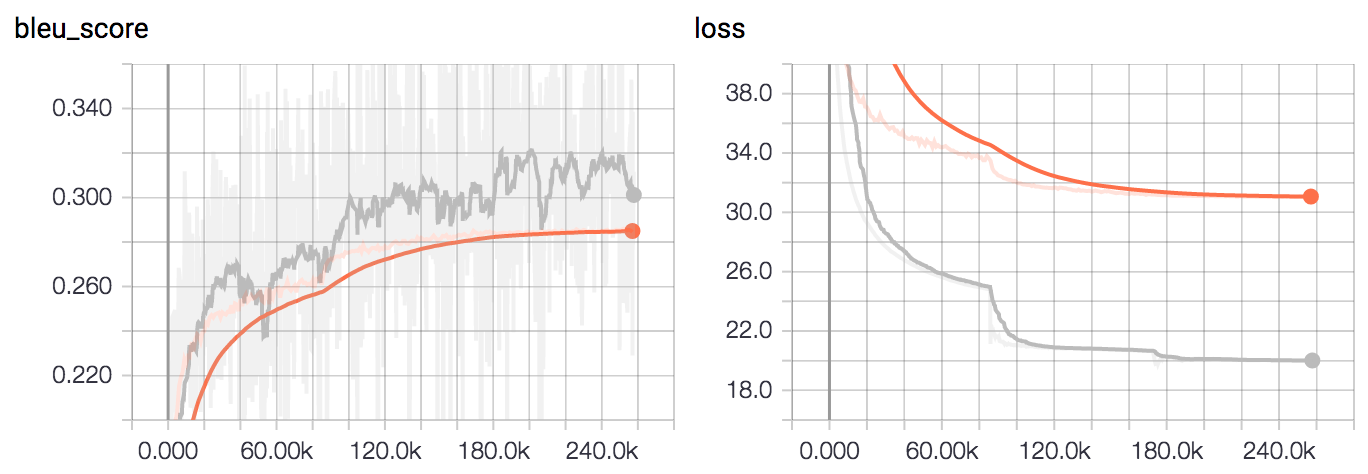
Training was done for 2 epochs on a Nvidia GTX 1080 and evaluated on the BLEU score. The Tensorboard training curves can be seen below. The grey curve is train and the orange curve is dev.
- pip installable package
- Explore deeper number of layers
- Recurrent layer dropout
- Greater dataset augmentation
- Try residual layer
- Model compression
- Byte pair encoding for out of set vocabulary
@inproceedings { wieting-17-millions,
author = {John Wieting and Kevin Gimpel},
title = {Pushing the Limits of Paraphrastic Sentence Embeddings with Millions of Machine Translations},
booktitle = {arXiv preprint arXiv:1711.05732}, year = {2017}
}
@inproceedings { wieting-17-backtrans,
author = {John Wieting, Jonathan Mallinson, and Kevin Gimpel},
title = {Learning Paraphrastic Sentence Embeddings from Back-Translated Bitext},
booktitle = {Proceedings of Empirical Methods in Natural Language Processing},
year = {2017}
}
Create the environment in the /paraphraser directory
conda env create -f env.yml
Activate the environment
conda activate paraphraser-env
Download the model checkpoint from above, rename it to "checkpoints", and place it within the /paraphraser/paraphraser directory
Download para-nmt-50m here
- Rename it to para-nmt-50m and place it inside the /paraphraser directory
You MAY need to run the following three commands (when prompted)
conda install tensorflow==1.14
conda install spacy
python3 -m spacy download en_core_web_sm
Run the inference.py script
cd paraphraser
python inference.py --checkpoint=checkpoints/model-171856