convert sentence-transformer to onnx model
因为工作需要,做到需要使用nlp问答的内容,然后就考虑到sentence-transformer(以下简称为sbert模型)。而且sbert句子转向量这个方法感觉很高效,因此就考虑到这个维度。
但是在使用sbert的过程中,遇到推理速度问题,也就是sbert的encode速度太慢了。后来花费了大量的时间在提高模型推理效率的工作上。
最后摸索出一个推理的高效方法:将模型转换成onnx格式的文件或者转换成tensorrt的plan格式文件。
这个模型不能直接转换么?确实不行。
在作者的一个issue可以找到答案:
UKPLab/sentence-transformers#46
Sadly I never worked with onnx. In SentenceTransformer, the forward function takes in one argument: features (and the second in python is self). Features is a dictionary, that contains the different features, for example, token ids, word weights, attention values, token_type_ids. For the BERT model, I think your input must look like this:
input_features = {'input_ids': dummy_input0, 'token_type_ids': dummy_input1, 'input_mask': dummy_input2}And then:
torch.onnx.export(model,input_features, onnx_file_name, verbose=True)
在这个链接下,作者说他的模型已经放在了huggingface Models Hub上,且Huggingface支持转换onnx。我尝试了一下,还是会出现问题。
既然整个的sbert模型不能直接转换,而且sbert中非常耗时间的模型其实是在transformer部分。那么我单独对transformer部分做加速不行么?答案是可以的。
以sbert的paraphrase-multilingual-MiniLM-L12-v2模型为案例。模型可以从这个链接下载https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/v0.2/
这个模型解压之后,模型实际上分为两个部分:
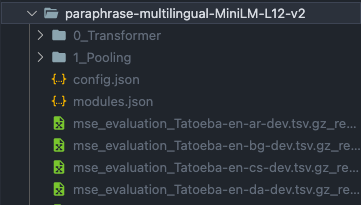
- 第一部分是
0_Transformer部分 - 第二部分是
1_Pooling部分。
可是两个模型的导入,并没有在sbert包里面明显的体现出来。使用的是import_from_string方式,非常巧妙。说白了:就是基于importlib包和模型文件里面的modules.json配合,巧妙的导入模型:
具体代码如下:
import importlib
import os
import json
from collections import OrderedDict
def import_from_string(dotted_path):
"""
Import a dotted module path and return the attribute/class designated by the
last name in the path. Raise ImportError if the import failed.
"""
try:
module_path, class_name = dotted_path.rsplit('.', 1)
except ValueError:
msg = "%s doesn't look like a module path" % dotted_path
raise ImportError(msg)
try:
module = importlib.import_module(dotted_path)
except:
module = importlib.import_module(module_path)
try:
return getattr(module, class_name)
except AttributeError:
msg = 'Module "%s" does not define a "%s" attribute/class' % (module_path, class_name)
raise ImportError(msg)
model_path = "../models/paraphrase-multilingual-MiniLM-L12-v2"
modules_json_path = os.path.join(model_path, 'modules.json')
with open(modules_json_path) as fIn:
modules_config = json.load(fIn)
modules = OrderedDict()
for module_config in modules_config:
module_class = import_from_string(module_config['type'])
module = module_class.load(os.path.join(model_path, module_config['path']))
modules[module_config['name']] = module
短短几行代码,就可以把两个模型都导入。而这两个模型,都是相互独立的,在推理的时候,就是把transforemr的token_embeddings和tokenizer后的attention_mask输入到pooling模型里面。
具体的操作步骤其实非常简单了,就是把第一部分的模型转换一下,然后再把模型的输出和pooling结合起来就可以。
代码太多了,我这里就不分享了。直接给大家仓库地址: https://github.com/yuanzhoulvpi2017/quick_sentence_transformers
- 具体的转换步骤,可以查看 仓库里面的
03_sbert2onnx_gpu.ipynb - 转换后的模型,如何用在pooling层上呢,可以查看仓库里面的
06speedtest.py
中间参考了大量资料,列举如下:
-
https://towardsdatascience.com/hugging-face-transformer-inference-under-1-millisecond-latency-e1be0057a51c 这个链接给我很大的影响,让我知道tensorrt和onnx推理能比pytorch直接跑快那么多,但是现在triton我还没搞,估计这个肯定比fastapi要快不少。
-
https://github.com/shibing624/text2vec 感谢徐明大佬的text2vec。我就是在阅读他的仓库的时候,发现了sentence-transformer包。同时也受到他这个包的一些写法的启发。
-
https://maple.link/2021/06/10/ONNX%E6%A8%A1%E5%9E%8B%E8%BD%ACTRT%20engine/ 我是从这个大佬的文章里面看到,如何把模型从onnx转换成tenosrrt的。写的非常清楚。后来改了他的代码一些细节部分。
-
https://onnxruntime.ai/docs/tutorials/huggingface.html 这个是onnxruntime官网,我在这个官网案例了,找到了如何加速transofmer,进而学会了如何加速sbert的transformer部分。
-
https://github.com/UKPLab/sentence-transformers 说到底还是看sbert作者本身的代码,我从这个包里面学到了很多知识,不限于python、pytorch、数据流的控制、loss修改等部分,学习到非常非常多新的思想。